 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEF HIPE-2026: Evaluating Accurate and Efficient Person-Place Relation Extraction from Multilingual Historical Texts
Feb 19, 2026HIPE-2026 is a CLEF evaluation lab dedicated to person-place relation extraction from noisy, multilingual historical texts. Building on the HIPE-2020 and HIPE-2022 campaigns, it extends the series toward semantic relation extraction by targeting the task of identifying person--place associations in multiple languages and time periods. Systems are asked to classify relations of two types - $at$ ("Has the person ever been at this place?") and $isAt$ ("Is the person located at this place around publication time?") - requiring reasoning over temporal and geographical cues. The lab introduces a three-fold evaluation profile that jointly assesses accuracy, computational efficiency, and domain generalization. By linking relation extraction to large-scale historical data processing, HIPE-2026 aims to support downstream applications in knowledge-graph construction, historical biography reconstruction, and spatial analysis in digital humanities.
Information Representation Fairness in Long-Document Embeddings: The Peculiar Interaction of Positional and Language Bias
Jan 23, 2026To be discoverable in an embedding-based search process, each part of a document should be reflected in its embedding representation. To quantify any potential reflection biases, we introduce a permutation-based evaluation framework. With this, we observe that state-of-the-art embedding models exhibit systematic positional and language biases when documents are longer and consist of multiple segments. Specifically, early segments and segments in higher-resource languages like English are over-represented, while later segments and segments in lower-resource languages are marginalized. In our further analysis, we find that the positional bias stems from front-loaded attention distributions in pooling-token embeddings, where early tokens receive more attention. To mitigate this issue, we introduce an inference-time attention calibration method that redistributes attention more evenly across document positions, increasing discoverabiltiy of later segments. Our evaluation framework and attention calibration is available at https://github.com/impresso/fair-sentence-transformers
Mechanistic Decomposition of Sentence Representations
Jun 04, 2025



Sentence embeddings are central to modern NLP and AI systems, yet little is known about their internal structure. While we can compare these embeddings using measures such as cosine similarity, the contributing features are not human-interpretable, and the content of an embedding seems untraceable, as it is masked by complex neural transformations and a final pooling operation that combines individual token embeddings. To alleviate this issue, we propose a new method to mechanistically decompose sentence embeddings into interpretable components, by using dictionary learning on token-level representations. We analyze how pooling compresses these features into sentence representations, and assess the latent features that reside in a sentence embedding. This bridges token-level mechanistic interpretability with sentence-level analysis, making for more transparent and controllable representations. In our studies, we obtain several interesting insights into the inner workings of sentence embedding spaces, for instance, that many semantic and syntactic aspects are linearly encoded in the embeddings.
Sentence Smith: Formally Controllable Text Transformation and its Application to Evaluation of Text Embedding Models
Feb 20, 2025We propose the Sentence Smith framework that enables controlled and specified manipulation of text meaning. It consists of three main steps: 1. Parsing a sentence into a semantic graph, 2. Applying human-designed semantic manipulation rules, and 3. Generating text from the manipulated graph. A final filtering step (4.) ensures the validity of the applied transformation. To demonstrate the utility of Sentence Smith in an application study, we use it to generate hard negative pairs that challenge text embedding models. Since the controllable generation makes it possible to clearly isolate different types of semantic shifts, we can gain deeper insights into the specific strengths and weaknesses of widely used text embedding models, also addressing an issue in current benchmarking where linguistic phenomena remain opaque. Human validation confirms that the generations produced by Sentence Smith are highly accurate.
Interpretable Text Embeddings and Text Similarity Explanation: A Primer
Feb 20, 2025


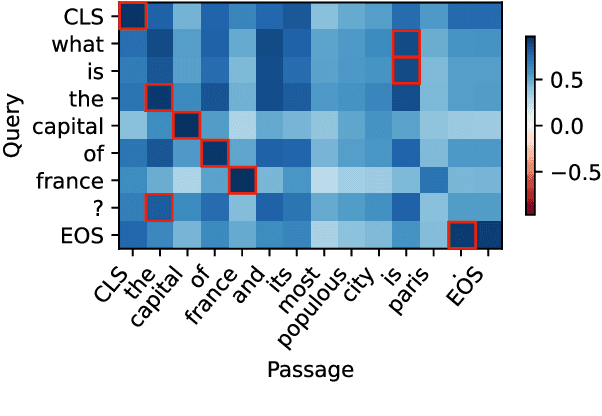
Text embeddings and text embedding models are a backbone of many AI and NLP systems, particularly those involving search. However, interpretability challenges persist, especially in explaining obtained similarity scores, which is crucial for applications requiring transparency. In this paper, we give a structured overview of interpretability methods specializing in explaining those similarity scores, an emerging research area. We study the methods' individual ideas and techniques, evaluating their potential for improving interpretability of text embeddings and explaining predicted similarities.
Adapting Multilingual Embedding Models to Historical Luxembourgish
Feb 11, 2025


The growing volume of digitized historical texts requires effective semantic search using text embeddings. However, pre-trained multilingual models, typically evaluated on contemporary texts, face challenges with historical digitized content due to OCR noise and outdated spellings. We explore the use of multilingual embeddings for cross-lingual semantic search on historical Luxembourgish, a low-resource language. We collect historical Luxembourgish news articles spanning various time periods and use GPT-4o to segment and translate them into closely related languages, creating 20,000 parallel training sentences per language pair. We further create a historical bitext mining evaluation set and find that these models struggle to perform cross-lingual search on historical Luxembourgish. To address this, we propose a simple adaptation method using in-domain training data, achieving up to 98\% accuracy in cross-lingual evaluations. We release our adapted models and historical Luxembourgish-German/French bitexts to support further research.
PARAPHRASUS : A Comprehensive Benchmark for Evaluating Paraphrase Detection Models
Sep 18, 2024



The task of determining whether two texts are paraphrases has long been a challenge in NLP. However, the prevailing notion of paraphrase is often quite simplistic, offering only a limited view of the vast spectrum of paraphrase phenomena. Indeed, we find that evaluating models in a paraphrase dataset can leave uncertainty about their true semantic understanding. To alleviate this, we release paraphrasus, a benchmark designed for multi-dimensional assessment of paraphrase detection models and finer model selection. We find that paraphrase detection models under a fine-grained evaluation lens exhibit trade-offs that cannot be captured through a single classification dataset.
Natural Language Processing RELIES on Linguistics
May 09, 2024Large Language Models (LLMs) have become capable of generating highly fluent text in certain languages, without modules specially designed to capture grammar or semantic coherence. What does this mean for the future of linguistic expertise in NLP? We highlight several aspects in which NLP (still) relies on linguistics, or where linguistic thinking can illuminate new directions. We argue our case around the acronym $RELIES$ that encapsulates six major facets where linguistics contributes to NLP: $R$esources, $E$valuation, $L$ow-resource settings, $I$nterpretability, $E$xplanation, and the $S$tudy of language. This list is not exhaustive, nor is linguistics the main point of reference for every effort under these themes; but at a macro level, these facets highlight the enduring importance of studying machine systems vis-a-vis systems of human language.
A Closer Look at Classification Evaluation Metrics and a Critical Reflection of Common Evaluation Practice
Apr 25, 2024Classification systems are evaluated in a countless number of papers. However, we find that evaluation practice is often nebulous. Frequently, metrics are selected without arguments, and blurry terminology invites misconceptions. For instance, many works use so-called 'macro' metrics to rank systems (e.g., 'macro F1') but do not clearly specify what they would expect from such a 'macro' metric. This is problematic, since picking a metric can affect paper findings as well as shared task rankings, and thus any clarity in the process should be maximized. Starting from the intuitive concepts of bias and prevalence, we perform an analysis of common evaluation metrics, considering expectations as found expressed in papers. Equipped with a thorough understanding of the metrics, we survey metric selection in recent shared tasks of Natural Language Processing. The results show that metric choices are often not supported with convincing arguments, an issue that can make any ranking seem arbitrary. This work aims at providing overview and guidance for more informed and transparent metric selection, fostering meaningful evaluation.
Schroedinger's Threshold: When the AUC doesn't predict Accuracy
Apr 04, 2024



The Area Under Curve measure (AUC) seems apt to evaluate and compare diverse models, possibly without calibration. An important example of AUC application is the evaluation and benchmarking of models that predict faithfulness of generated text. But we show that the AUC yields an academic and optimistic notion of accuracy that can misalign with the actual accuracy observed in application, yielding significant changes in benchmark rankings. To paint a more realistic picture of downstream model performance (and prepare a model for actual application), we explore different calibration modes, testing calibration data and method.