 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Smith: Formally Controllable Text Transformation and its Application to Evaluation of Text Embedding Models
Feb 20, 2025We propose the Sentence Smith framework that enables controlled and specified manipulation of text meaning. It consists of three main steps: 1. Parsing a sentence into a semantic graph, 2. Applying human-designed semantic manipulation rules, and 3. Generating text from the manipulated graph. A final filtering step (4.) ensures the validity of the applied transformation. To demonstrate the utility of Sentence Smith in an application study, we use it to generate hard negative pairs that challenge text embedding models. Since the controllable generation makes it possible to clearly isolate different types of semantic shifts, we can gain deeper insights into the specific strengths and weaknesses of widely used text embedding models, also addressing an issue in current benchmarking where linguistic phenomena remain opaque. Human validation confirms that the generations produced by Sentence Smith are highly accurate.
Uncovering More Shallow Heuristics: Probing the Natural Language Inference Capacities of Transformer-Based Pre-Trained Language Models Using Syllogistic Patterns
Jan 19, 2022



In this article, we explore the shallow heuristics used by transformer-based pre-trained language models (PLMs) that are fine-tuned for natural language inference (NLI). To do so, we construct or own dataset based on syllogistic, and we evaluate a number of models' performance on our dataset. We find evidence that the models rely heavily on certain shallow heuristics, picking up on symmetries and asymmetries between premise and hypothesis. We suggest that the lack of generalization observable in our study, which is becoming a topic of lively debate in the field, means that the PLMs are currently not learning NLI, but rather spurious heuristics.
Exploring the Promises of Transformer-Based LMs for the Representation of Normative Claims in the Legal Domain
Aug 25, 2021
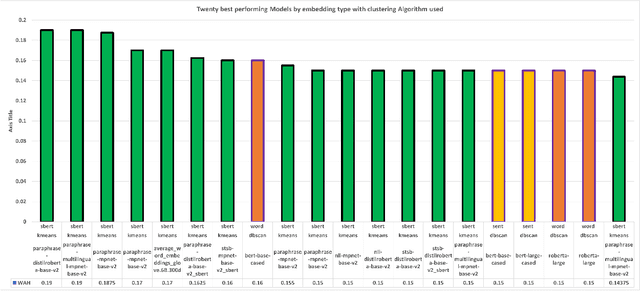
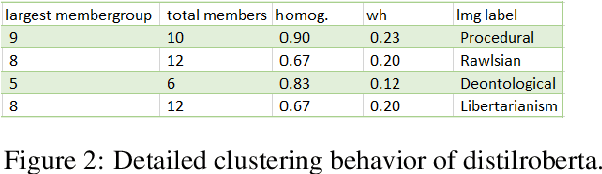
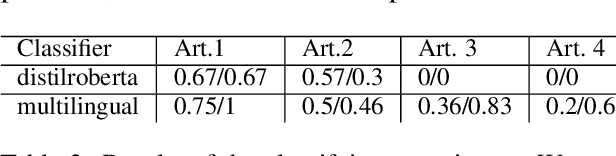
In this article, we explore the potential of transformer-based language models (LMs) to correctly represent normative statements in the legal domain, taking tax law as our use case. In our experiment, we use a variety of LMs as bases for both word- and sentence-based clusterers that are then evaluated on a small, expert-compiled test-set, consisting of real-world samples from tax law research literature that can be clearly assigned to one of four normative theories. The results of the experiment show that clusterers based on sentence-BERT-embeddings deliver the most promising results. Based on this main experiment, we make first attempts at using the best performing models in a bootstrapping loop to build classifiers that map normative claims on one of these four normative theories.