 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Promises of Transformer-Based LMs for the Representation of Normative Claims in the Legal Domain
Paper and Code
Aug 25, 2021
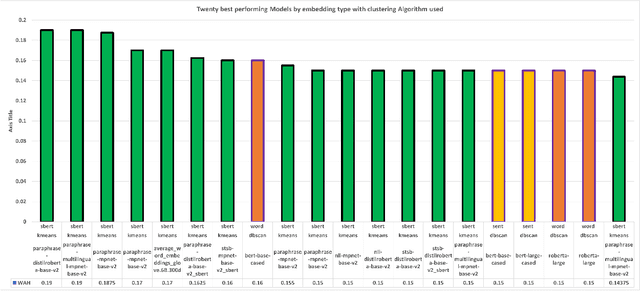
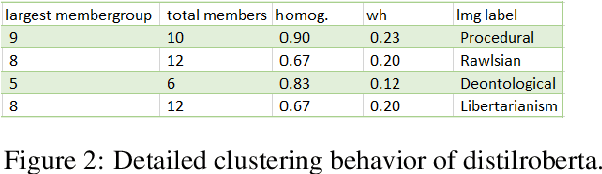
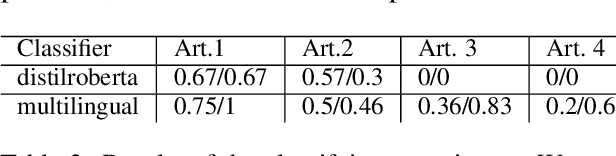
In this article, we explore the potential of transformer-based language models (LMs) to correctly represent normative statements in the legal domain, taking tax law as our use case. In our experiment, we use a variety of LMs as bases for both word- and sentence-based clusterers that are then evaluated on a small, expert-compiled test-set, consisting of real-world samples from tax law research literature that can be clearly assigned to one of four normative theories. The results of the experiment show that clusterers based on sentence-BERT-embeddings deliver the most promising results. Based on this main experiment, we make first attempts at using the best performing models in a bootstrapping loop to build classifiers that map normative claims on one of these four normative theories.