 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Driven Inertial Generated Data for Smartphone Location Classification
Apr 20, 2025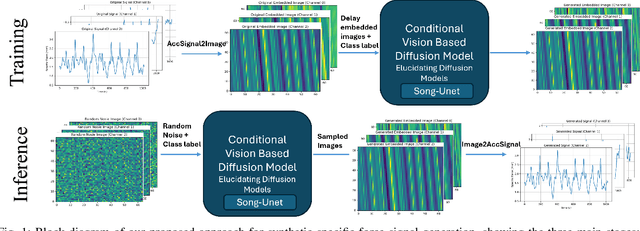
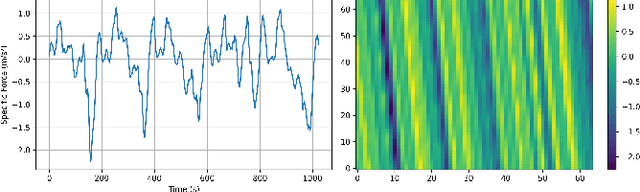
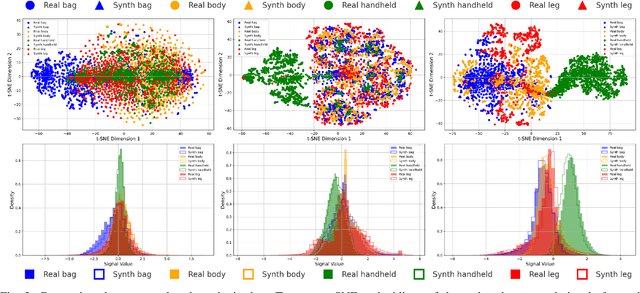

Despite the crucial role of inertial measurements in motion tracking and navigation systems, the time-consuming and resource-intensive nature of collecting extensive inertial data has hindered the development of robust machine learning models in this field. In recent years, diffusion models have emerged as a revolutionary class of generative models, reshaping the landscape of artificial data generation. These models surpass generative adversarial networks and other state-of-the-art approaches to complex tasks. In this work, we propose diffusion-driven specific force-generated data for smartphone location recognition. We provide a comprehensive evaluation methodology by comparing synthetic and real recorded specific force data across multiple metrics. Our results demonstrate that our diffusion-based generative model successfully captures the distinctive characteristics of specific force signals across different smartphone placement conditions. Thus, by creating diverse, realistic synthetic data, we can reduce the burden of extensive data collection while providing high-quality training data for machine learning models.
The Alternative Annotator Test for LLM-as-a-Judge: How to Statistically Justify Replacing Human Annotators with LLMs
Jan 19, 2025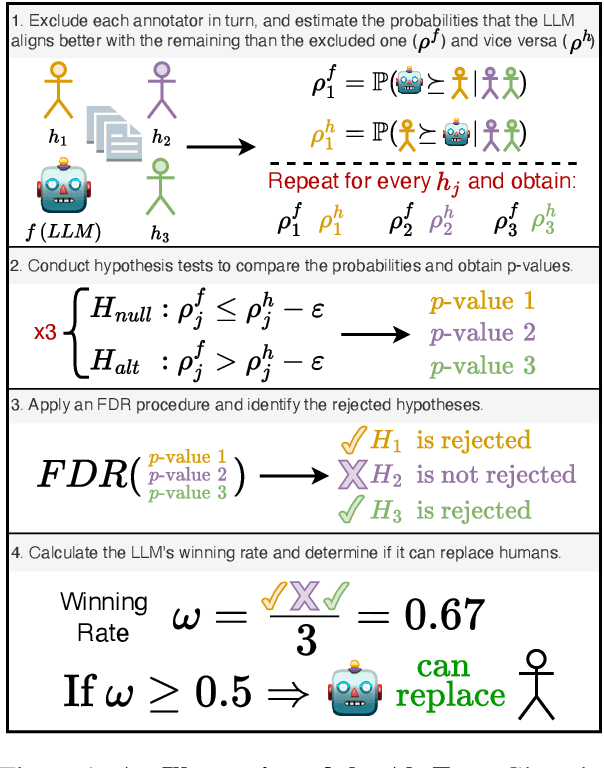
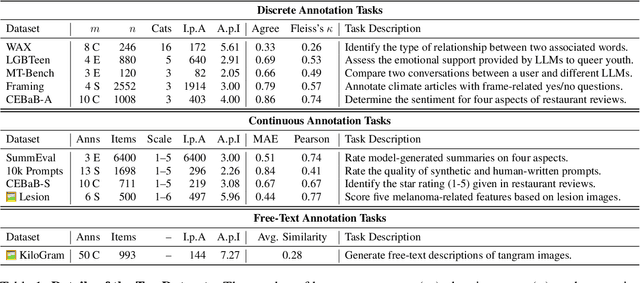
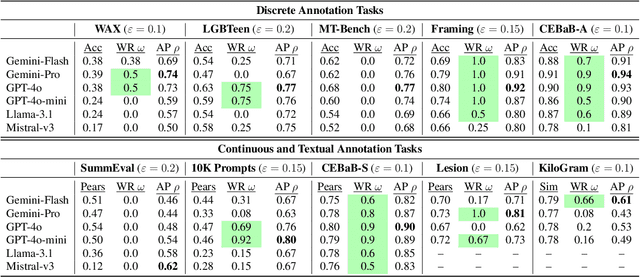
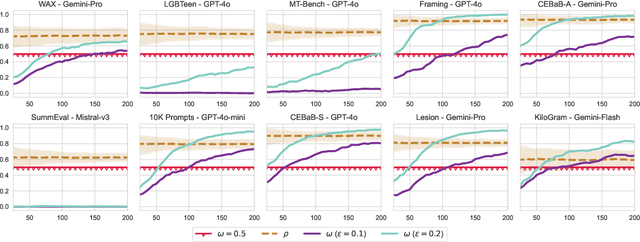
The "LLM-as-a-judge" paradigm employs Large Language Models (LLMs) as annotators and evaluators in tasks traditionally performed by humans. LLM annotations are widely used, not only in NLP research but also in fields like medicine, psychology, and social science. Despite their role in shaping study results and insights, there is no standard or rigorous procedure to determine whether LLMs can replace human annotators. In this paper, we propose a novel statistical procedure -- the Alternative Annotator Test (alt-test) -- that requires only a modest subset of annotated examples to justify using LLM annotations. Additionally, we introduce a versatile and interpretable measure for comparing LLM judges. To demonstrate our procedure, we curated a diverse collection of ten datasets, consisting of language and vision-language tasks, and conducted experiments with six LLMs and four prompting techniques. Our results show that LLMs can sometimes replace humans with closed-source LLMs (such as GPT-4o), outperforming open-source LLMs, and that prompting techniques yield judges of varying quality. We hope this study encourages more rigorous and reliable practices.
State of What Art? A Call for Multi-Prompt LLM Evaluation
Dec 31, 2023Recent advances in large language models (LLMs) have led to the development of various evaluation benchmarks. These benchmarks typically rely on a single instruction template for evaluating all LLMs on a specific task. In this paper, we comprehensively analyze the brittleness of results obtained via single-prompt evaluations across 6.5M instances, involving 20 different LLMs and 39 tasks from 3 benchmarks. To improve robustness of the analysis, we propose to evaluate LLMs with a set of diverse prompts instead. We discuss tailored evaluation metrics for specific use cases (e.g., LLM developers vs. developers interested in a specific downstream task), ensuring a more reliable and meaningful assessment of LLM capabilities. We then implement these criteria and conduct evaluations of multiple models, providing insights into the true strengths and limitations of current LLMs.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
The Eval4NLP 2023 Shared Task on Prompting Large Language Models as Explainable Metrics
Oct 30, 2023



With an increasing number of parameters and pre-training data, generative large language models (LLMs) have shown remarkable capabilities to solve tasks with minimal or no task-related examples. Notably, LLMs have been successfully employed as evaluation metrics in text generation tasks. Within this context, we introduce the Eval4NLP 2023 shared task that asks participants to explore prompting and score extraction for machine translation (MT) and summarization evaluation. Specifically, we propose a novel competition setting in which we select a list of allowed LLMs and disallow fine-tuning to ensure a focus on prompting. We present an overview of participants' approaches and evaluate them on a new reference-free test set spanning three language pairs for MT and a summarization dataset. Notably, despite the task's restrictions, the best-performing systems achieve results on par with or even surpassing recent reference-free metrics developed using larger models, including GEMBA and Comet-Kiwi-XXL. Finally, as a separate track, we perform a small-scale human evaluation of the plausibility of explanations given by the LLMs.
Human-in-the-Loop Schema Induction
Feb 25, 2023Schema induction builds a graph representation explaining how events unfold in a scenario. Existing approaches have been based on information retrieval (IR) and information extraction(IE), often with limited human curation. We demonstrate a human-in-the-loop schema induction system powered by GPT-3. We first describe the different modules of our system, including prompting to generate schematic elements, manual edit of those elements, and conversion of those into a schema graph. By qualitatively comparing our system to previous ones, we show that our system not only transfers to new domains more easily than previous approaches, but also reduces efforts of human curation thanks to our interactive interface.
On the Limitations of Reference-Free Evaluations of Generated Text
Oct 22, 2022There is significant interest in developing evaluation metrics which accurately estimate the quality of generated text without the aid of a human-written reference text, which can be time consuming and expensive to collect or entirely unavailable in online applications. However, in this work, we demonstrate that these reference-free metrics are inherently biased and limited in their ability to evaluate generated text, and we argue that they should not be used to measure progress on tasks like machine translation or summarization. We show how reference-free metrics are equivalent to using one generation model to evaluate another, which has several limitations: (1) the metrics can be optimized at test time to find the approximate best-possible output, (2) they are inherently biased toward models which are more similar to their own, and (3) they can be biased against higher-quality outputs, including those written by humans. Therefore, we recommend that reference-free metrics should be used as diagnostic tools for analyzing and understanding model behavior instead of measures of how well models perform a task, in which the goal is to achieve as high of a score as possible.
Zero-Shot On-the-Fly Event Schema Induction
Oct 12, 2022
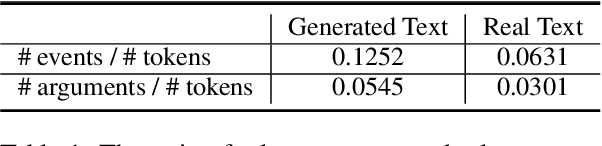


What are the events involved in a pandemic outbreak? What steps should be taken when planning a wedding? The answers to these questions can be found by collecting many documents on the complex event of interest, extracting relevant information, and analyzing it. We present a new approach in which large language models are utilized to generate source documents that allow predicting, given a high-level event definition, the specific events, arguments, and relations between them to construct a schema that describes the complex event in its entirety. Using our model, complete schemas on any topic can be generated on-the-fly without any manual data collection, i.e., in a zero-shot manner. Moreover, we develop efficient methods to extract pertinent information from texts and demonstrate in a series of experiments that these schemas are considered to be more complete than human-curated ones in the majority of examined scenarios. Finally, we show that this framework is comparable in performance with previous supervised schema induction methods that rely on collecting real texts while being more general and flexible without the need for a predefined ontology.
Re-Examining System-Level Correlations of Automatic Summarization Evaluation Metrics
Apr 21, 2022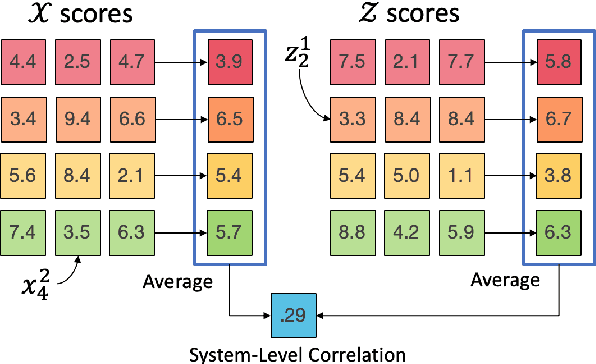
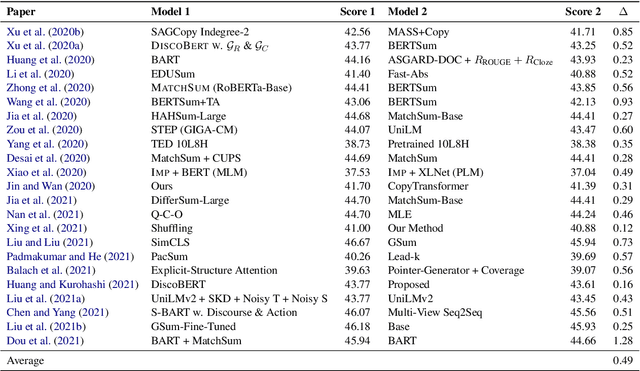
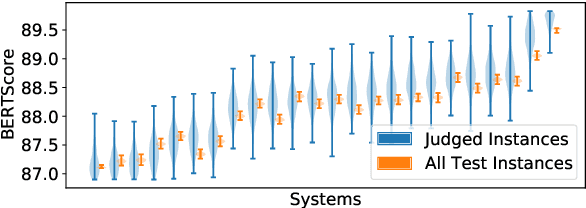
How reliably an automatic summarization evaluation metric replicates human judgments of summary quality is quantified by system-level correlations. We identify two ways in which the definition of the system-level correlation is inconsistent with how metrics are used to evaluate systems in practice and propose changes to rectify this disconnect. First, we calculate the system score for an automatic metric using the full test set instead of the subset of summaries judged by humans, which is currently standard practice. We demonstrate how this small change leads to more precise estimates of system-level correlations. Second, we propose to calculate correlations only on pairs of systems that are separated by small differences in automatic scores which are commonly observed in practice. This allows us to demonstrate that our best estimate of the correlation of ROUGE to human judgments is near 0 in realistic scenarios. The results from the analyses point to the need to collect more high-quality human judgments and to improve automatic metrics when differences in system scores are small.
A Statistical Analysis of Summarization Evaluation Metrics using Resampling Methods
Mar 31, 2021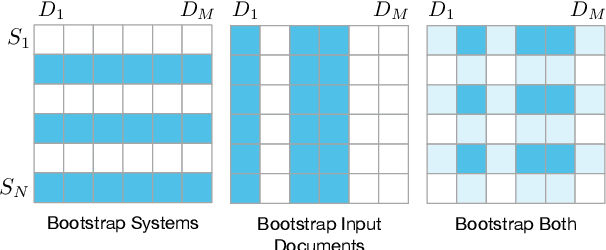
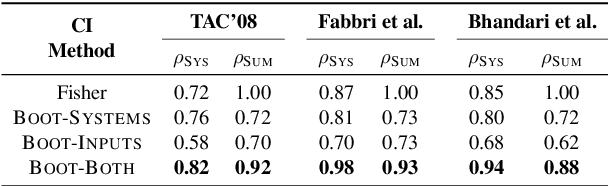
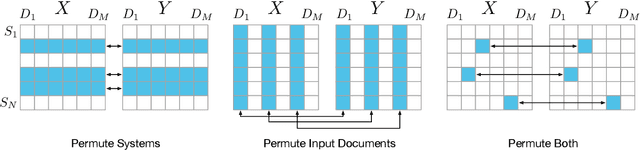
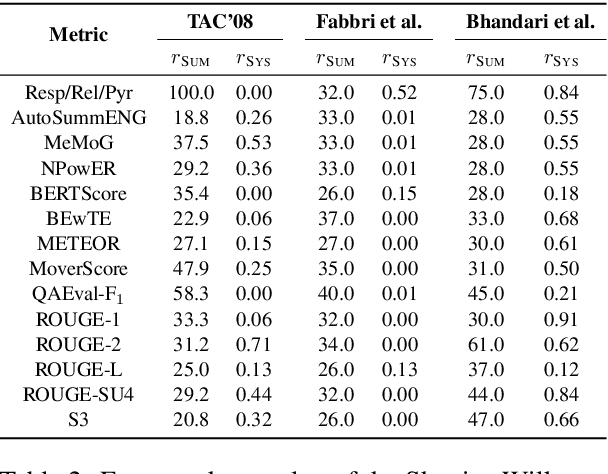
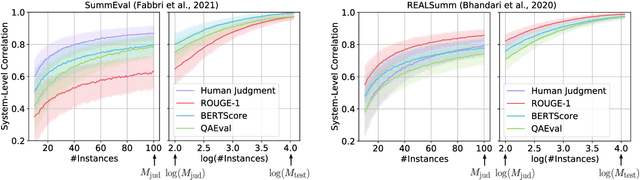
The quality of a summarization evaluation metric is quantified by calculating the correlation between its scores and human annotations across a large number of summaries. Currently, it is not clear how precise these correlation estimates are, nor whether differences between two metrics' correlations reflects a true difference or if it is due to random chance. In this work, we address these two problems by proposing methods for calculating confidence intervals and running hypothesis tests for correlations using two resampling methods, bootstrapping and permutation. After evaluating which of the proposed methods is most appropriate for summarization through two simulation experiments, we analyze the results of applying these methods to several different automatic evaluation metrics across three sets of human annotations. We find that the confidence intervals are rather wide, demonstrating high uncertainty in how reliable automatic metrics truly are. Further, although many metrics fail to show statistical improvements over ROUGE, two recent works, QAEval and BERTScore, do in some evaluation settings.