 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality
Feb 15, 2026Standard factuality evaluations of LLMs treat all errors alike, obscuring whether failures arise from missing knowledge (empty shelves) or from limited access to encoded facts (lost keys). We propose a behavioral framework that profiles factual knowledge at the level of facts rather than questions, characterizing each fact by whether it is encoded, and then by how accessible it is: cannot be recalled, can be directly recalled, or can only be recalled with inference-time computation (thinking). To support such profiling, we introduce WikiProfile, a new benchmark constructed via an automated pipeline with a prompted LLM grounded in web search. Across 4 million responses from 13 LLMs, we find that encoding is nearly saturated in frontier models on our benchmark, with GPT-5 and Gemini-3 encoding 95--98% of facts. However, recall remains a major bottleneck: many errors previously attributed to missing knowledge instead stem from failures to access it. These failures are systematic and disproportionately affect long-tail facts and reverse questions. Finally, we show that thinking improves recall and can recover a substantial fraction of failures, indicating that future gains may rely less on scaling and more on methods that improve how models utilize what they already encode.
LIBERTy: A Causal Framework for Benchmarking Concept-Based Explanations of LLMs with Structural Counterfactuals
Jan 15, 2026Concept-based explanations quantify how high-level concepts (e.g., gender or experience) influence model behavior, which is crucial for decision-makers in high-stakes domains. Recent work evaluates the faithfulness of such explanations by comparing them to reference causal effects estimated from counterfactuals. In practice, existing benchmarks rely on costly human-written counterfactuals that serve as an imperfect proxy. To address this, we introduce a framework for constructing datasets containing structural counterfactual pairs: LIBERTy (LLM-based Interventional Benchmark for Explainability with Reference Targets). LIBERTy is grounded in explicitly defined Structured Causal Models (SCMs) of the text generation, interventions on a concept propagate through the SCM until an LLM generates the counterfactual. We introduce three datasets (disease detection, CV screening, and workplace violence prediction) together with a new evaluation metric, order-faithfulness. Using them, we evaluate a wide range of methods across five models and identify substantial headroom for improving concept-based explanations. LIBERTy also enables systematic analysis of model sensitivity to interventions: we find that proprietary LLMs show markedly reduced sensitivity to demographic concepts, likely due to post-training mitigation. Overall, LIBERTy provides a much-needed benchmark for developing faithful explainability methods.
Multi-Domain Explainability of Preferences
May 26, 2025
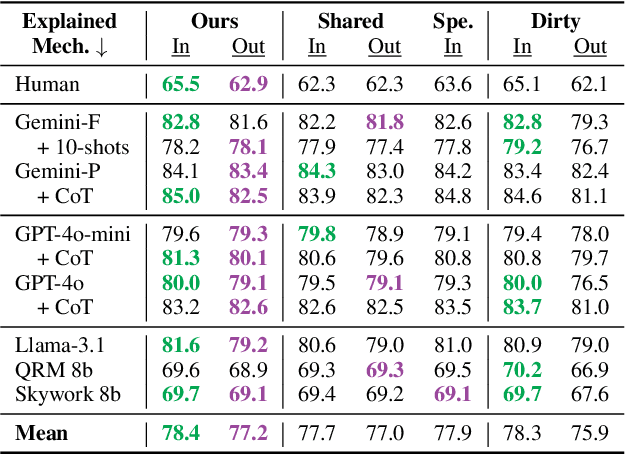
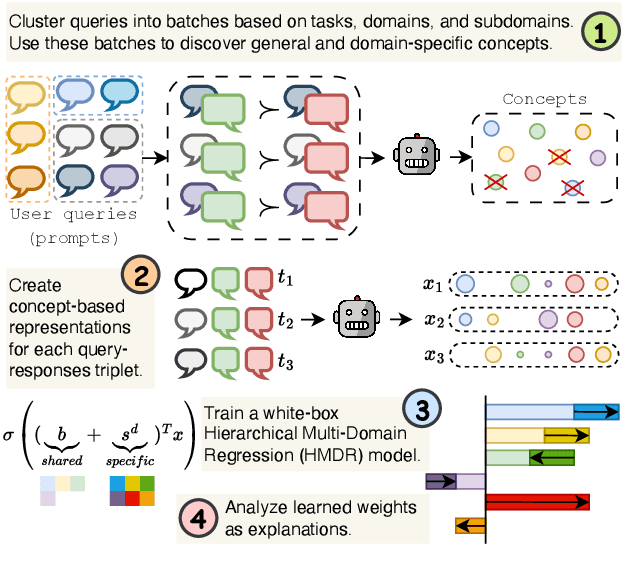
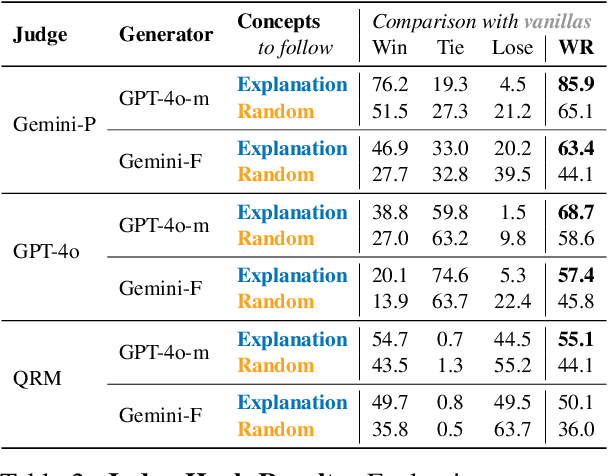
Preference mechanisms, such as human preference, LLM-as-a-Judge (LaaJ), and reward models, are central to aligning and evaluating large language models (LLMs). Yet, the underlying concepts that drive these preferences remain poorly understood. In this work, we propose a fully automated end-to-end method for generating local and global concept-based explanations of preferences across multiple domains. Our method employs an LLM to discover concepts that differentiate between chosen and rejected responses and represent them with concept-based vectors. To model the relationships between concepts and preferences, we propose a white-box Hierarchical Multi-Domain Regression model that captures both domain-general and domain-specific effects. To evaluate our method, we curate a dataset spanning eight challenging and diverse domains and explain twelve mechanisms. Our method achieves strong preference prediction performance, outperforming baselines while also being explainable. Additionally, we assess explanations in two novel application-driven settings. First, guiding LLM outputs with concepts from LaaJ explanations yields responses that those judges consistently prefer. Second, prompting LaaJs with concepts explaining humans improves their preference predictions. Together, our work provides a new paradigm for explainability in the era of LLMs.
Dementia Through Different Eyes: Explainable Modeling of Human and LLM Perceptions for Early Awareness
May 19, 2025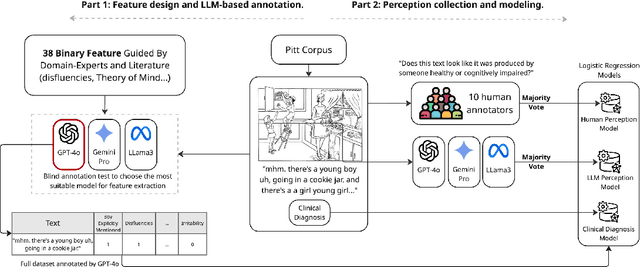
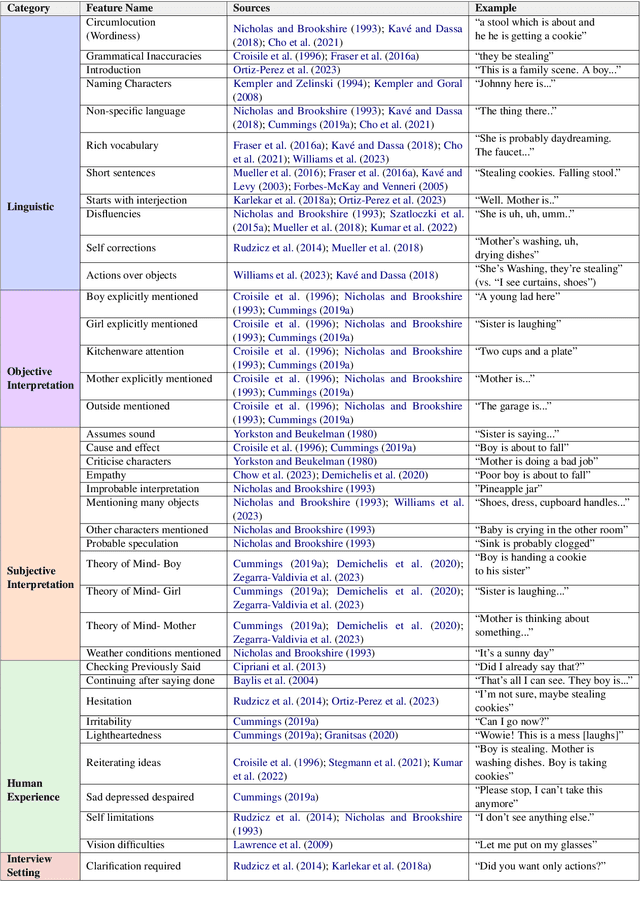
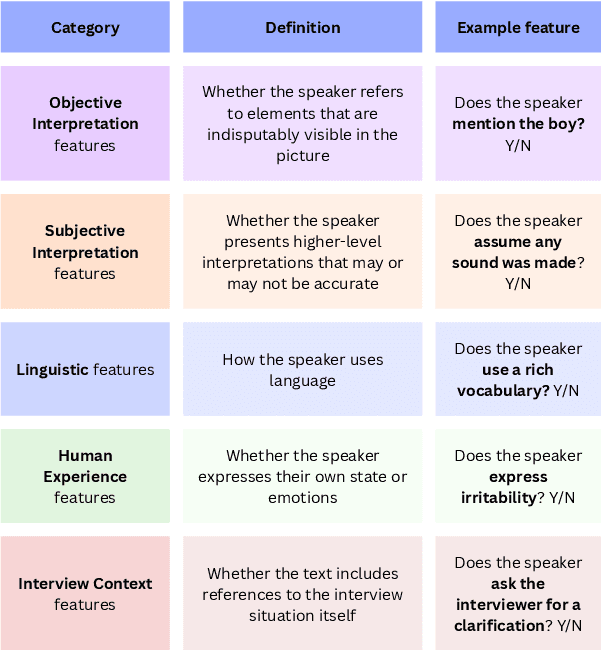
Cognitive decline often surfaces in language years before diagnosis. It is frequently non-experts, such as those closest to the patient, who first sense a change and raise concern. As LLMs become integrated into daily communication and used over prolonged periods, it may even be an LLM that notices something is off. But what exactly do they notice--and should be noticing--when making that judgment? This paper investigates how dementia is perceived through language by non-experts. We presented transcribed picture descriptions to non-expert humans and LLMs, asking them to intuitively judge whether each text was produced by someone healthy or with dementia. We introduce an explainable method that uses LLMs to extract high-level, expert-guided features representing these picture descriptions, and use logistic regression to model human and LLM perceptions and compare with clinical diagnoses. Our analysis reveals that human perception of dementia is inconsistent and relies on a narrow, and sometimes misleading, set of cues. LLMs, by contrast, draw on a richer, more nuanced feature set that aligns more closely with clinical patterns. Still, both groups show a tendency toward false negatives, frequently overlooking dementia cases. Through our interpretable framework and the insights it provides, we hope to help non-experts better recognize the linguistic signs that matter.
AdaptiVocab: Enhancing LLM Efficiency in Focused Domains through Lightweight Vocabulary Adaptation
Mar 25, 2025
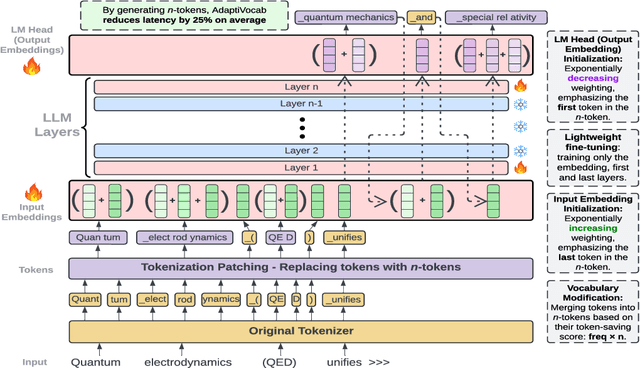
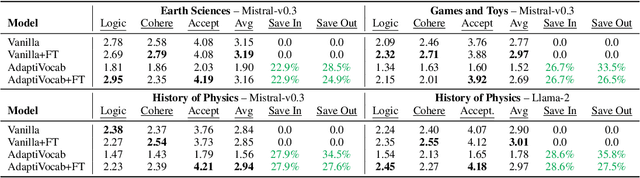
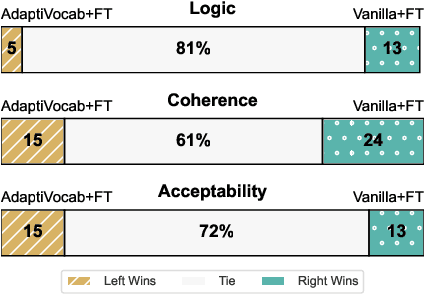
Large Language Models (LLMs) have shown impressive versatility as general purpose models. However, their broad applicability comes at a high-cost computational overhead, particularly in auto-regressive decoding where each step requires a forward pass. In domain-specific settings, general-purpose capabilities are unnecessary and can be exchanged for efficiency. In this work, we take a novel perspective on domain adaptation, reducing latency and computational costs by adapting the vocabulary to focused domains of interest. We introduce AdaptiVocab, an end-to-end approach for vocabulary adaptation, designed to enhance LLM efficiency in low-resource domains. AdaptiVocab can be applied to any tokenizer and architecture, modifying the vocabulary by replacing tokens with domain-specific n-gram-based tokens, thereby reducing the number of tokens required for both input processing and output generation. AdaptiVocab initializes new n-token embeddings using an exponentially weighted combination of existing embeddings and employs a lightweight fine-tuning phase that can be efficiently performed on a single GPU. We evaluate two 7B LLMs across three niche domains, assessing efficiency, generation quality, and end-task performance. Our results show that AdaptiVocab reduces token usage by over 25% without compromising performance
The Alternative Annotator Test for LLM-as-a-Judge: How to Statistically Justify Replacing Human Annotators with LLMs
Jan 19, 2025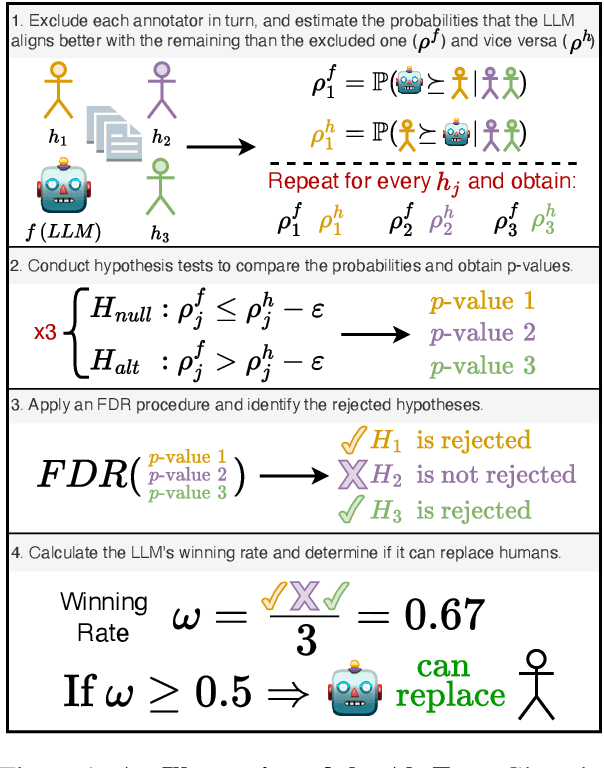
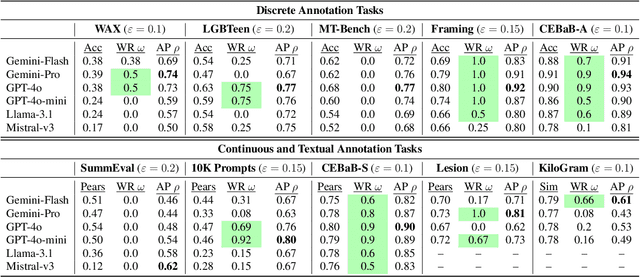
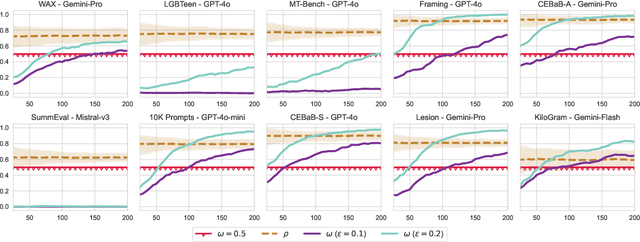
The "LLM-as-a-judge" paradigm employs Large Language Models (LLMs) as annotators and evaluators in tasks traditionally performed by humans. LLM annotations are widely used, not only in NLP research but also in fields like medicine, psychology, and social science. Despite their role in shaping study results and insights, there is no standard or rigorous procedure to determine whether LLMs can replace human annotators. In this paper, we propose a novel statistical procedure -- the Alternative Annotator Test (alt-test) -- that requires only a modest subset of annotated examples to justify using LLM annotations. Additionally, we introduce a versatile and interpretable measure for comparing LLM judges. To demonstrate our procedure, we curated a diverse collection of ten datasets, consisting of language and vision-language tasks, and conducted experiments with six LLMs and four prompting techniques. Our results show that LLMs can sometimes replace humans with closed-source LLMs (such as GPT-4o), outperforming open-source LLMs, and that prompting techniques yield judges of varying quality. We hope this study encourages more rigorous and reliable practices.
Are LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Model Performance
Oct 24, 2024



NLP benchmarks rely on standardized datasets for training and evaluating models and are crucial for advancing the field. Traditionally, expert annotations ensure high-quality labels; however, the cost of expert annotation does not scale well with the growing demand for larger datasets required by modern models. While crowd-sourcing provides a more scalable solution, it often comes at the expense of annotation precision and consistency. Recent advancements in large language models (LLMs) offer new opportunities to enhance the annotation process, particularly for detecting label errors in existing datasets. In this work, we consider the recent approach of LLM-as-a-judge, leveraging an ensemble of LLMs to flag potentially mislabeled examples. Through a case study of four datasets from the TRUE benchmark, covering different tasks and domains, we empirically analyze the labeling quality of existing datasets, and compare expert, crowd-sourced, and our LLM-based annotations in terms of agreement, label quality, and efficiency, demonstrating the strengths and limitations of each annotation method. Our findings reveal a substantial number of label errors, which, when corrected, induce a significant upward shift in reported model performance. This suggests that many of the LLMs so-called mistakes are due to label errors rather than genuine model failures. Additionally, we discuss the implications of mislabeled data and propose methods to mitigate them in training to improve model performance.
NL-Eye: Abductive NLI for Images
Oct 03, 2024
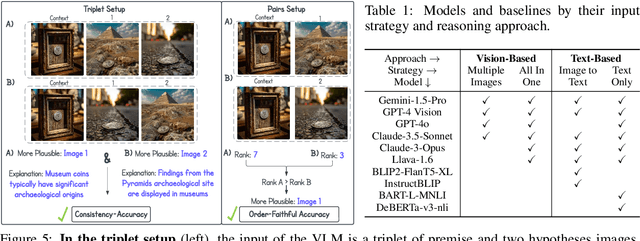

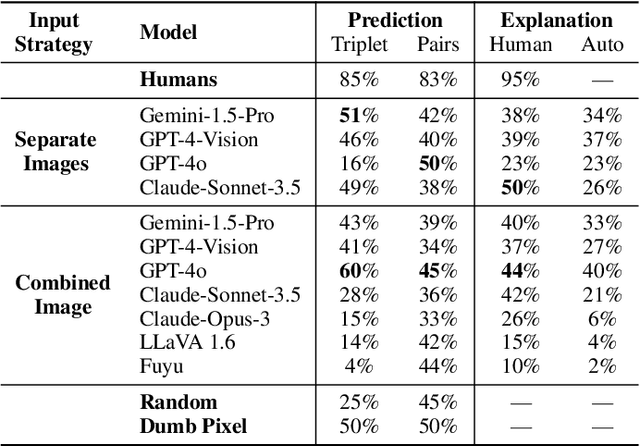
Will a Visual Language Model (VLM)-based bot warn us about slipping if it detects a wet floor? Recent VLMs have demonstrated impressive capabilities, yet their ability to infer outcomes and causes remains underexplored. To address this, we introduce NL-Eye, a benchmark designed to assess VLMs' visual abductive reasoning skills. NL-Eye adapts the abductive Natural Language Inference (NLI) task to the visual domain, requiring models to evaluate the plausibility of hypothesis images based on a premise image and explain their decisions. NL-Eye consists of 350 carefully curated triplet examples (1,050 images) spanning diverse reasoning categories: physical, functional, logical, emotional, cultural, and social. The data curation process involved two steps - writing textual descriptions and generating images using text-to-image models, both requiring substantial human involvement to ensure high-quality and challenging scenes. Our experiments show that VLMs struggle significantly on NL-Eye, often performing at random baseline levels, while humans excel in both plausibility prediction and explanation quality. This demonstrates a deficiency in the abductive reasoning capabilities of modern VLMs. NL-Eye represents a crucial step toward developing VLMs capable of robust multimodal reasoning for real-world applications, including accident-prevention bots and generated video verification.
On Behalf of the Stakeholders: Trends in NLP Model Interpretability in the Era of LLMs
Jul 27, 2024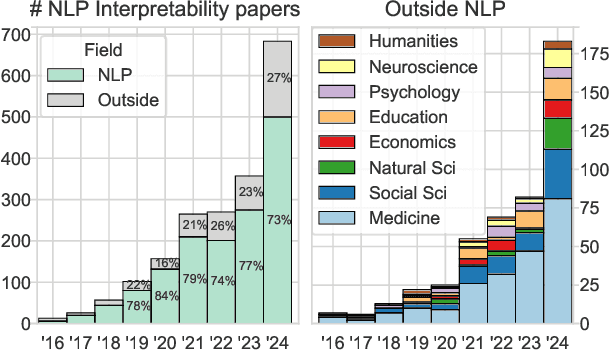
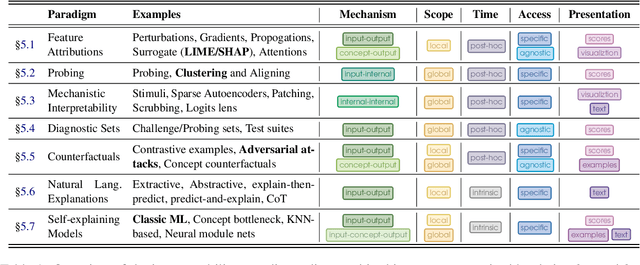
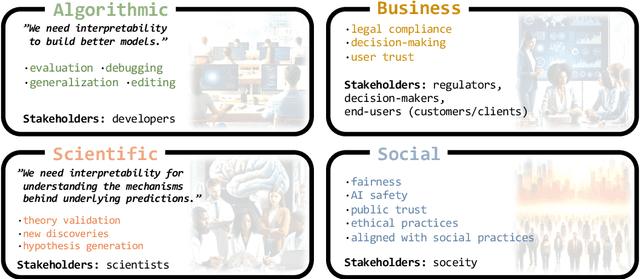
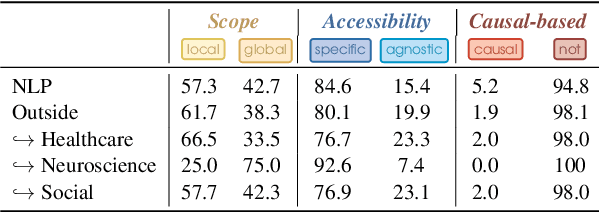
Recent advancements in NLP systems, particularly with the introduction of LLMs, have led to widespread adoption of these systems by a broad spectrum of users across various domains, impacting decision-making, the job market, society, and scientific research. This surge in usage has led to an explosion in NLP model interpretability and analysis research, accompanied by numerous technical surveys. Yet, these surveys often overlook the needs and perspectives of explanation stakeholders. In this paper, we address three fundamental questions: Why do we need interpretability, what are we interpreting, and how? By exploring these questions, we examine existing interpretability paradigms, their properties, and their relevance to different stakeholders. We further explore the practical implications of these paradigms by analyzing trends from the past decade across multiple research fields. To this end, we retrieved thousands of papers and employed an LLM to characterize them. Our analysis reveals significant disparities between NLP developers and non-developer users, as well as between research fields, underscoring the diverse needs of stakeholders. For example, explanations of internal model components are rarely used outside the NLP field. We hope this paper informs the future design, development, and application of methods that align with the objectives and requirements of various stakeholders.
The Colorful Future of LLMs: Evaluating and Improving LLMs as Emotional Supporters for Queer Youth
Feb 19, 2024
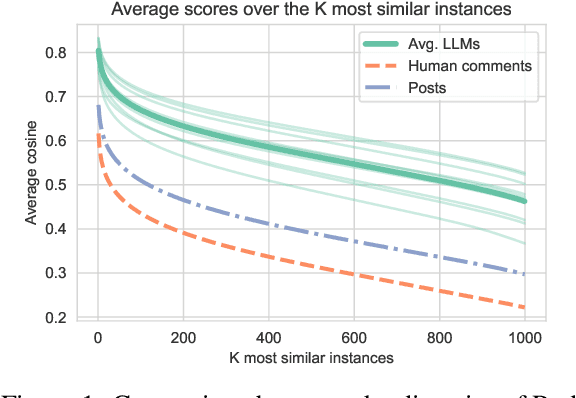
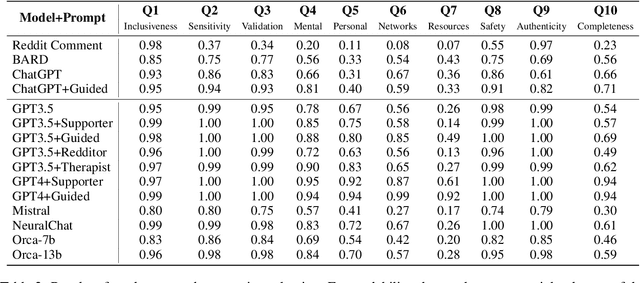
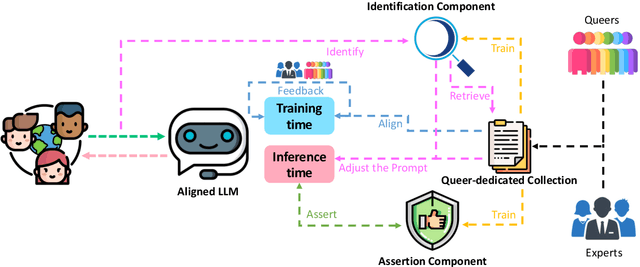
Queer youth face increased mental health risks, such as depression, anxiety, and suicidal ideation. Hindered by negative stigma, they often avoid seeking help and rely on online resources, which may provide incompatible information. Although access to a supportive environment and reliable information is invaluable, many queer youth worldwide have no access to such support. However, this could soon change due to the rapid adoption of Large Language Models (LLMs) such as ChatGPT. This paper aims to comprehensively explore the potential of LLMs to revolutionize emotional support for queers. To this end, we conduct a qualitative and quantitative analysis of LLM's interactions with queer-related content. To evaluate response quality, we develop a novel ten-question scale that is inspired by psychological standards and expert input. We apply this scale to score several LLMs and human comments to posts where queer youth seek advice and share experiences. We find that LLM responses are supportive and inclusive, outscoring humans. However, they tend to be generic, not empathetic enough, and lack personalization, resulting in nonreliable and potentially harmful advice. We discuss these challenges, demonstrate that a dedicated prompt can improve the performance, and propose a blueprint of an LLM-supporter that actively (but sensitively) seeks user context to provide personalized, empathetic, and reliable responses. Our annotated dataset is available for further research.