 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptiVocab: Enhancing LLM Efficiency in Focused Domains through Lightweight Vocabulary Adaptation
Mar 25, 2025
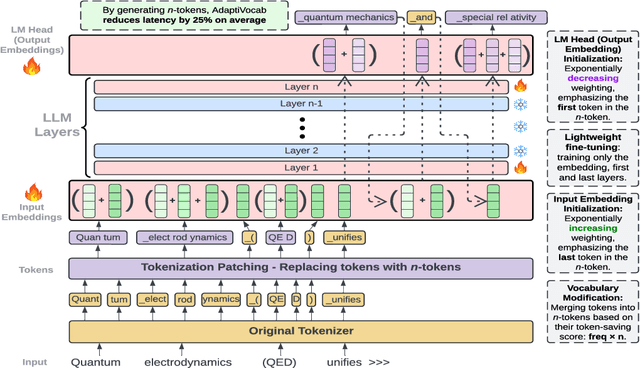
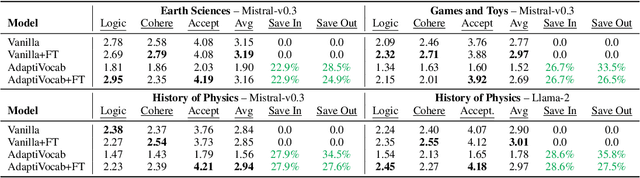
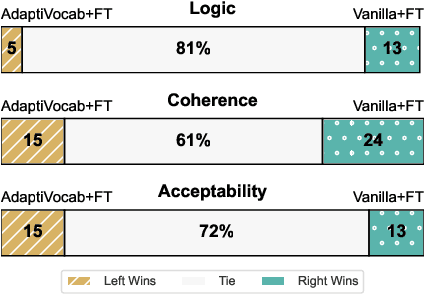
Large Language Models (LLMs) have shown impressive versatility as general purpose models. However, their broad applicability comes at a high-cost computational overhead, particularly in auto-regressive decoding where each step requires a forward pass. In domain-specific settings, general-purpose capabilities are unnecessary and can be exchanged for efficiency. In this work, we take a novel perspective on domain adaptation, reducing latency and computational costs by adapting the vocabulary to focused domains of interest. We introduce AdaptiVocab, an end-to-end approach for vocabulary adaptation, designed to enhance LLM efficiency in low-resource domains. AdaptiVocab can be applied to any tokenizer and architecture, modifying the vocabulary by replacing tokens with domain-specific n-gram-based tokens, thereby reducing the number of tokens required for both input processing and output generation. AdaptiVocab initializes new n-token embeddings using an exponentially weighted combination of existing embeddings and employs a lightweight fine-tuning phase that can be efficiently performed on a single GPU. We evaluate two 7B LLMs across three niche domains, assessing efficiency, generation quality, and end-task performance. Our results show that AdaptiVocab reduces token usage by over 25% without compromising performance
DropCompute: simple and more robust distributed synchronous training via compute variance reduction
Jun 18, 2023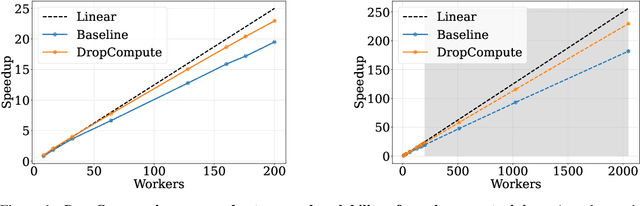

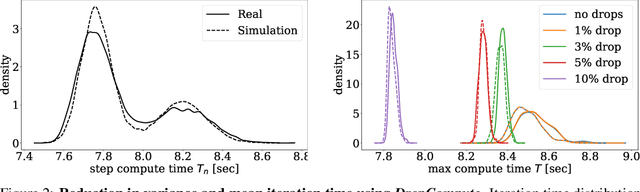
Background: Distributed training is essential for large scale training of deep neural networks (DNNs). The dominant methods for large scale DNN training are synchronous (e.g. All-Reduce), but these require waiting for all workers in each step. Thus, these methods are limited by the delays caused by straggling workers. Results: We study a typical scenario in which workers are straggling due to variability in compute time. We find an analytical relation between compute time properties and scalability limitations, caused by such straggling workers. With these findings, we propose a simple yet effective decentralized method to reduce the variation among workers and thus improve the robustness of synchronous training. This method can be integrated with the widely used All-Reduce. Our findings are validated on large-scale training tasks using 200 Gaudi Accelerators.
Energy awareness in low precision neural networks
Feb 06, 2022



Power consumption is a major obstacle in the deployment of deep neural networks (DNNs) on end devices. Existing approaches for reducing power consumption rely on quite general principles, including avoidance of multiplication operations and aggressive quantization of weights and activations. However, these methods do not take into account the precise power consumed by each module in the network, and are therefore not optimal. In this paper we develop accurate power consumption models for all arithmetic operations in the DNN, under various working conditions. We reveal several important factors that have been overlooked to date. Based on our analysis, we present PANN (power-aware neural network), a simple approach for approximating any full-precision network by a low-power fixed-precision variant. Our method can be applied to a pre-trained network, and can also be used during training to achieve improved performance. In contrast to previous methods, PANN incurs only a minor degradation in accuracy w.r.t. the full-precision version of the network, even when working at the power-budget of a 2-bit quantized variant. In addition, our scheme enables to seamlessly traverse the power-accuracy trade-off at deployment time, which is a major advantage over existing quantization methods that are constrained to specific bit widths.
Logarithmic Unbiased Quantization: Practical 4-bit Training in Deep Learning
Dec 19, 2021


Quantization of the weights and activations is one of the main methods to reduce the computational footprint of Deep Neural Networks (DNNs) training. Current methods enable 4-bit quantization of the forward phase. However, this constitutes only a third of the training process. Reducing the computational footprint of the entire training process requires the quantization of the neural gradients, i.e., the loss gradients with respect to the outputs of intermediate neural layers. In this work, we examine the importance of having unbiased quantization in quantized neural network training, where to maintain it, and how. Based on this, we suggest a $\textit{logarithmic unbiased quantization}$ (LUQ) method to quantize both the forward and backward phase to 4-bit, achieving state-of-the-art results in 4-bit training without overhead. For example, in ResNet50 on ImageNet, we achieved a degradation of 1.18%. We further improve this to degradation of only 0.64% after a single epoch of high precision fine-tuning combined with a variance reduction method -- both add overhead comparable to previously suggested methods. Finally, we suggest a method that uses the low precision format to avoid multiplications during two-thirds of the training process, thus reducing by 5x the area used by the multiplier.
Task Agnostic Continual Learning Using Online Variational Bayes with Fixed-Point Updates
Oct 01, 2020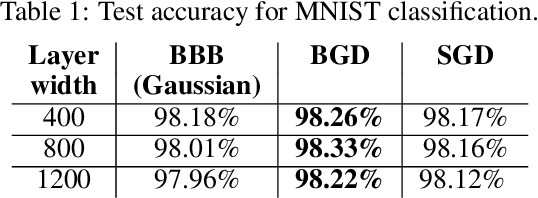
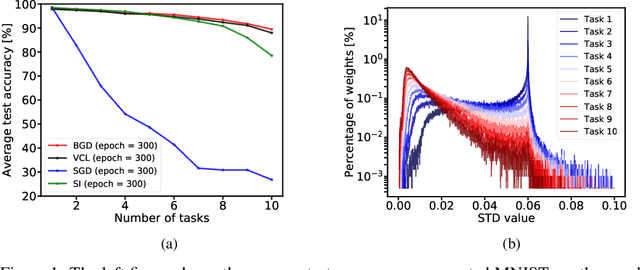
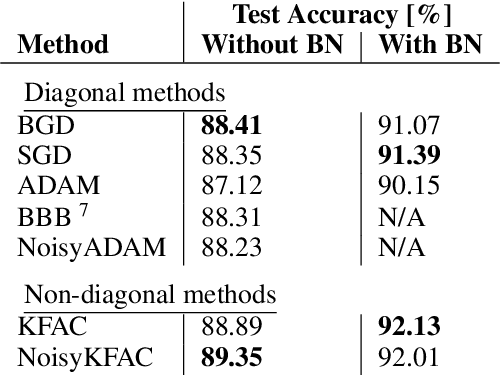
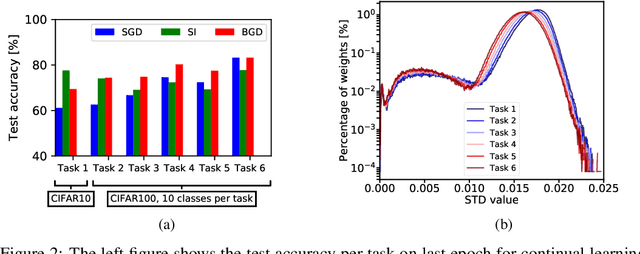
Background: Catastrophic forgetting is the notorious vulnerability of neural networks to the changes in the data distribution during learning. This phenomenon has long been considered a major obstacle for using learning agents in realistic continual learning settings. A large body of continual learning research assumes that task boundaries are known during training. However, only a few works consider scenarios in which task boundaries are unknown or not well defined -- task agnostic scenarios. The optimal Bayesian solution for this requires an intractable online Bayes update to the weights posterior. Contributions: We aim to approximate the online Bayes update as accurately as possible. To do so, we derive novel fixed-point equations for the online variational Bayes optimization problem, for multivariate Gaussian parametric distributions. By iterating the posterior through these fixed-point equations, we obtain an algorithm (FOO-VB) for continual learning which can handle non-stationary data distribution using a fixed architecture and without using external memory (i.e. without access to previous data). We demonstrate that our method (FOO-VB) outperforms existing methods in task agnostic scenarios. FOO-VB Pytorch implementation will be available online.
Neural gradients are lognormally distributed: understanding sparse and quantized training
Jun 17, 2020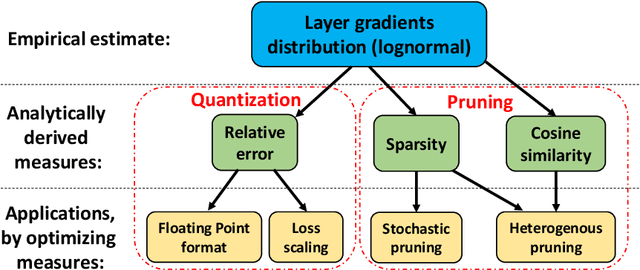

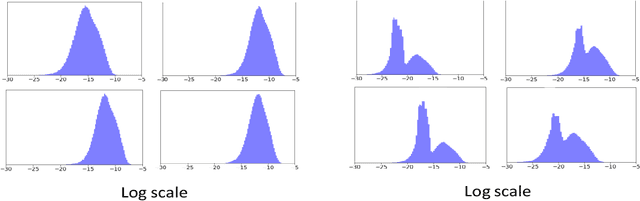
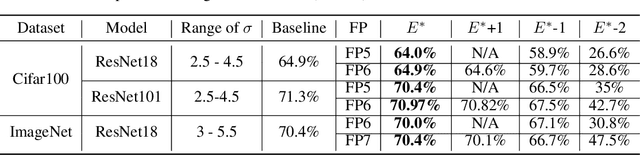
Neural gradient compression remains a main bottleneck in improving training efficiency, as most existing neural network compression methods (e.g., pruning or quantization) focus on weights, activations, and weight gradients. However, these methods are not suitable for compressing neural gradients, which have a very different distribution. Specifically, we find that the neural gradients follow a lognormal distribution. Taking this into account, we suggest two methods to reduce the computational and memory burdens of neural gradients. The first one is stochastic gradient pruning, which can accurately set the sparsity level -- up to 85% gradient sparsity without hurting validation accuracy (ResNet18 on ImageNet). The second method determines the floating-point format for low numerical precision gradients (e.g., FP8). Our results shed light on previous findings related to local scaling, the optimal bit-allocation for the mantissa and exponent, and challenging workloads for which low-precision floating-point arithmetic has reported to fail. Reference implementation accompanies the paper.
The Knowledge Within: Methods for Data-Free Model Compression
Dec 03, 2019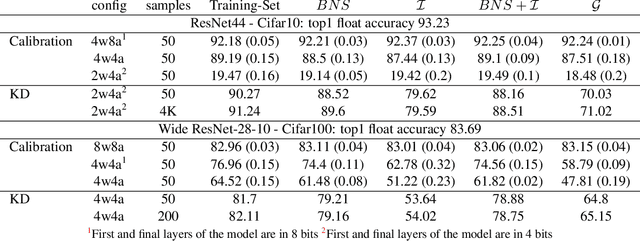
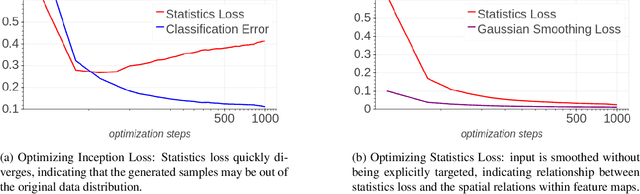
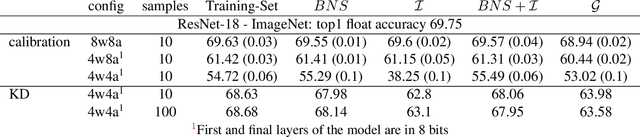
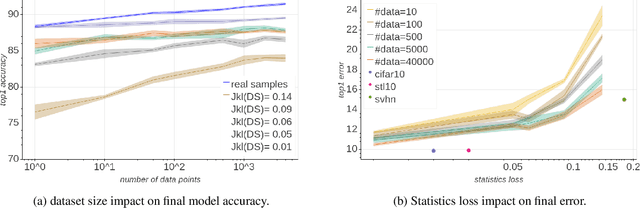
Background: Recently, an extensive amount of research has been focused on compressing and accelerating Deep Neural Networks (DNNs). So far, high compression rate algorithms required the entire training dataset, or its subset, for fine-tuning and low precision calibration process. However, this requirement is unacceptable when sensitive data is involved as in medical and biometric use-cases. Contributions: We present three methods for generating synthetic samples from trained models. Then, we demonstrate how these samples can be used to fine-tune or to calibrate quantized models with negligible accuracy degradation compared to the original training set --- without using any real data in the process. Furthermore, we suggest that our best performing method, leveraging intrinsic batch normalization layers' statistics of a trained model, can be used to evaluate data similarity. Our approach opens a path towards genuine data-free model compression, alleviating the need for training data during deployment.
At Stability's Edge: How to Adjust Hyperparameters to Preserve Minima Selection in Asynchronous Training of Neural Networks?
Sep 26, 2019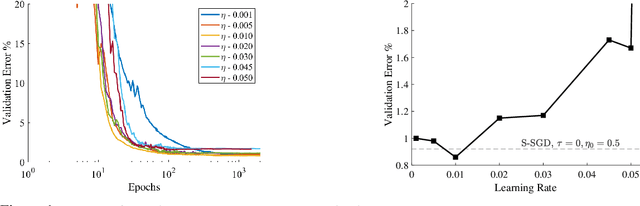

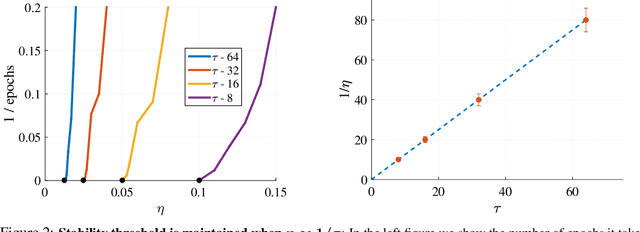
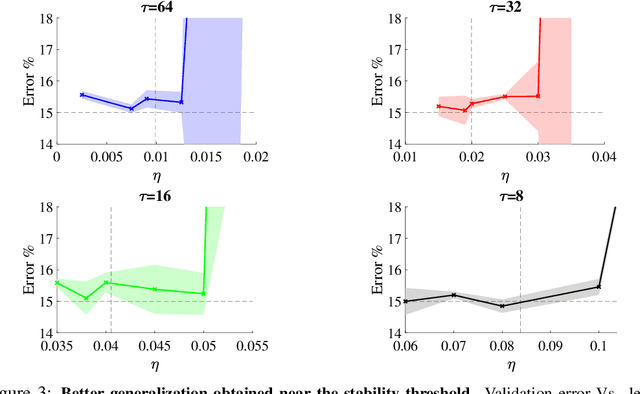
Background: Recent developments have made it possible to accelerate neural networks training significantly using large batch sizes and data parallelism. Training in an asynchronous fashion, where delay occurs, can make training even more scalable. However, asynchronous training has its pitfalls, mainly a degradation in generalization, even after convergence of the algorithm. This gap remains not well understood, as theoretical analysis so far mainly focused on the convergence rate of asynchronous methods. Contributions: We examine asynchronous training from the perspective of dynamical stability. We find that the degree of delay interacts with the learning rate, to change the set of minima accessible by an asynchronous stochastic gradient descent algorithm. We derive closed-form rules on how the learning rate could be changed, while keeping the accessible set the same. Specifically, for high delay values, we find that the learning rate should be kept inversely proportional to the delay. We then extend this analysis to include momentum. We find momentum should be either turned off, or modified to improve training stability. We provide empirical experiments to validate our theoretical findings.
Mix & Match: training convnets with mixed image sizes for improved accuracy, speed and scale resiliency
Aug 12, 2019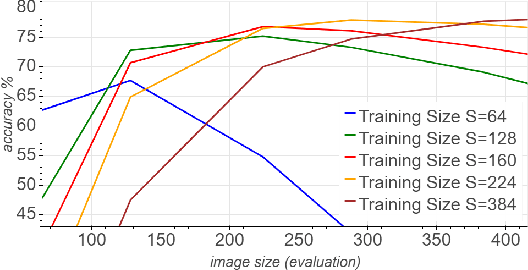
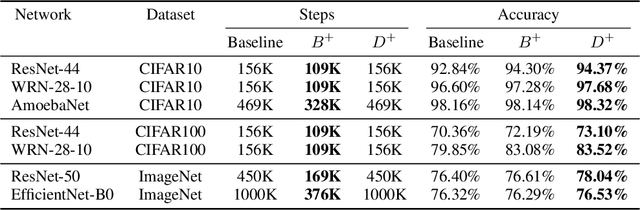
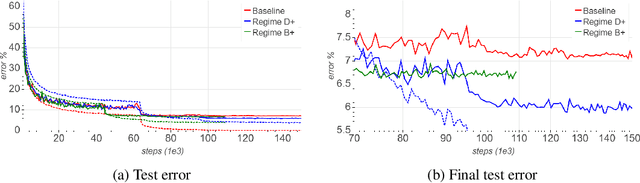
Convolutional neural networks (CNNs) are commonly trained using a fixed spatial image size predetermined for a given model. Although trained on images of aspecific size, it is well established that CNNs can be used to evaluate a wide range of image sizes at test time, by adjusting the size of intermediate feature maps. In this work, we describe and evaluate a novel mixed-size training regime that mixes several image sizes at training time. We demonstrate that models trained using our method are more resilient to image size changes and generalize well even on small images. This allows faster inference by using smaller images attest time. For instance, we receive a 76.43% top-1 accuracy using ResNet50 with an image size of 160, which matches the accuracy of the baseline model with 2x fewer computations. Furthermore, for a given image size used at test time, we show this method can be exploited either to accelerate training or the final test accuracy. For example, we are able to reach a 79.27% accuracy with a model evaluated at a 288 spatial size for a relative improvement of 14% over the baseline.
Augment your batch: better training with larger batches
Jan 27, 2019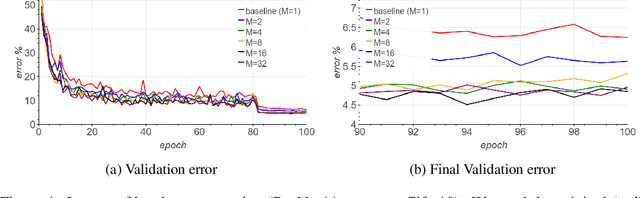
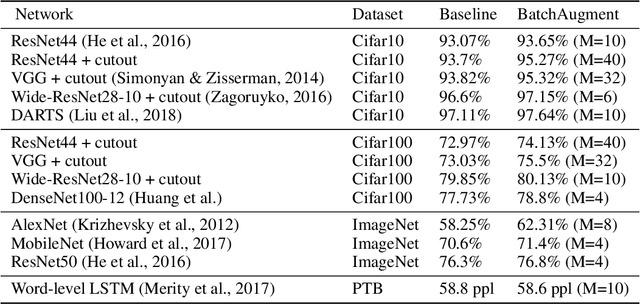

Large-batch SGD is important for scaling training of deep neural networks. However, without fine-tuning hyperparameter schedules, the generalization of the model may be hampered. We propose to use batch augmentation: replicating instances of samples within the same batch with different data augmentations. Batch augmentation acts as a regularizer and an accelerator, increasing both generalization and performance scaling. We analyze the effect of batch augmentation on gradient variance and show that it empirically improves convergence for a wide variety of deep neural networks and datasets. Our results show that batch augmentation reduces the number of necessary SGD updates to achieve the same accuracy as the state-of-the-art. Overall, this simple yet effective method enables faster training and better generalization by allowing more computational resources to be used concurrently.