 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUMAGE: Probabilistic Low rank Unbiased Min Variance Gradient Estimator for Efficient Large Model Training
May 23, 2025Accelerator memory and networking constraints have emerged as dominant bottlenecks when training large language models LLMs with billions of parameters. Existing low rank gradient estimators such as GaLoRE and FLORA compress gradients and optimizer tensors by projecting weight gradients onto a rank r subspace, enabling LLM training on consumer hardware. Yet, these methods are either biased or subject to high estimator variance. Moreover, the optimizer state based on the first and second moments estimates expressed in the previous subspace becomes misaligned whenever the projection is updated, leading to instabilities during training. We propose PLUMAGE: Probabilistic Low rank Unbiased Minimum vAriance Gradient Estimator. PLUMAGE is a drop in replacement for existing low rank gradient estimators. It does not introduce new hyperparameters beyond the chosen rank r and the update interval. In addition, we resolve optimizer state misalignment issues to prevent spurious weight updates and enhance training stability. We empirically demonstrate that PLUMAGE shrinks the full rank optimization's gap over the pre training evaluation loss by 33% on average across models and the average training loss across the GLUE benchmark by 28% within a similar computational and memory footprint as GaloRE.
Statistical Testing for Efficient Out of Distribution Detection in Deep Neural Networks
Feb 25, 2021
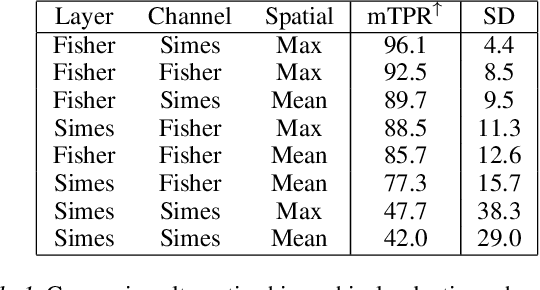


Commonly, Deep Neural Networks (DNNs) generalize well on samples drawn from a distribution similar to that of the training set. However, DNNs' predictions are brittle and unreliable when the test samples are drawn from a dissimilar distribution. This presents a major concern for deployment in real-world applications, where such behavior may come at a great cost -- as in the case of autonomous vehicles or healthcare applications. This paper frames the Out Of Distribution (OOD) detection problem in DNN as a statistical hypothesis testing problem. Unlike previous OOD detection heuristics, our framework is guaranteed to maintain the false positive rate (detecting OOD as in-distribution) for test data. We build on this framework to suggest a novel OOD procedure based on low-order statistics. Our method achieves comparable or better than state-of-the-art results on well-accepted OOD benchmarks without retraining the network parameters -- and at a fraction of the computational cost.
The Knowledge Within: Methods for Data-Free Model Compression
Dec 03, 2019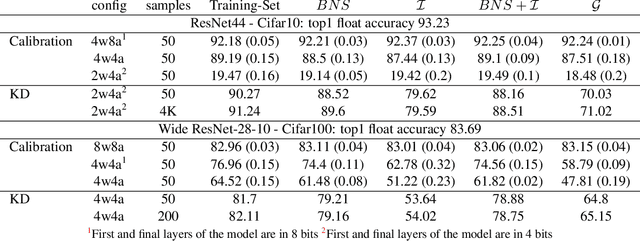
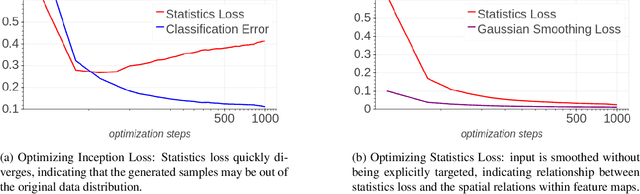
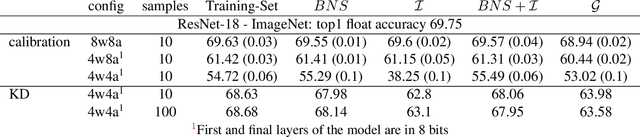
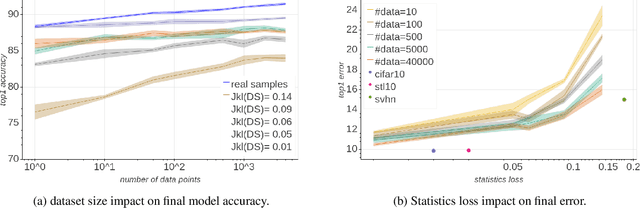
Background: Recently, an extensive amount of research has been focused on compressing and accelerating Deep Neural Networks (DNNs). So far, high compression rate algorithms required the entire training dataset, or its subset, for fine-tuning and low precision calibration process. However, this requirement is unacceptable when sensitive data is involved as in medical and biometric use-cases. Contributions: We present three methods for generating synthetic samples from trained models. Then, we demonstrate how these samples can be used to fine-tune or to calibrate quantized models with negligible accuracy degradation compared to the original training set --- without using any real data in the process. Furthermore, we suggest that our best performing method, leveraging intrinsic batch normalization layers' statistics of a trained model, can be used to evaluate data similarity. Our approach opens a path towards genuine data-free model compression, alleviating the need for training data during deployment.
Learn What Not to Learn: Action Elimination with Deep Reinforcement Learning
Sep 06, 2018
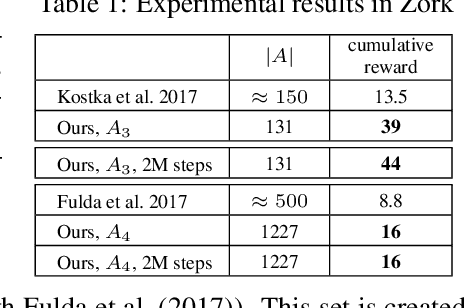
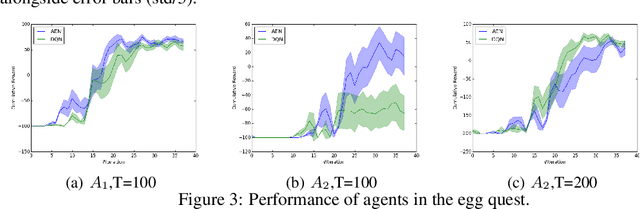
Learning how to act when there are many available actions in each state is a challenging task for Reinforcement Learning (RL) agents, especially when many of the actions are redundant or irrelevant. In such cases, it is sometimes easier to learn which actions not to take. In this work, we propose the Action-Elimination Deep Q-Network (AE-DQN) architecture that combines a Deep RL algorithm with an Action Elimination Network (AEN) that eliminates sub-optimal actions. The AEN is trained to predict invalid actions, supervised by an external elimination signal provided by the environment. Simulations demonstrate a considerable speedup and added robustness over vanilla DQN in text-based games with over a thousand discrete actions.