 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Multi-Step Lookahead Information Via Adaptive Batching
Jan 15, 2026We study tabular reinforcement learning problems with multiple steps of lookahead information. Before acting, the learner observes $\ell$ steps of future transition and reward realizations: the exact state the agent would reach and the rewards it would collect under any possible course of action. While it has been shown that such information can drastically boost the value, finding the optimal policy is NP-hard, and it is common to apply one of two tractable heuristics: processing the lookahead in chunks of predefined sizes ('fixed batching policies'), and model predictive control. We first illustrate the problems with these two approaches and propose utilizing the lookahead in adaptive (state-dependent) batches; we refer to such policies as adaptive batching policies (ABPs). We derive the optimal Bellman equations for these strategies and design an optimistic regret-minimizing algorithm that enables learning the optimal ABP when interacting with unknown environments. Our regret bounds are order-optimal up to a potential factor of the lookahead horizon $\ell$, which can usually be considered a small constant.
Online Linear Regression with Paid Stochastic Features
Nov 11, 2025We study an online linear regression setting in which the observed feature vectors are corrupted by noise and the learner can pay to reduce the noise level. In practice, this may happen for several reasons: for example, because features can be measured more accurately using more expensive equipment, or because data providers can be incentivized to release less private features. Assuming feature vectors are drawn i.i.d. from a fixed but unknown distribution, we measure the learner's regret against the linear predictor minimizing a notion of loss that combines the prediction error and payment. When the mapping between payments and noise covariance is known, we prove that the rate $\sqrt{T}$ is optimal for regret if logarithmic factors are ignored. When the noise covariance is unknown, we show that the optimal regret rate becomes of order $T^{2/3}$ (ignoring log factors). Our analysis leverages matrix martingale concentration, showing that the empirical loss uniformly converges to the expected one for all payments and linear predictors.
Stable Matching with Ties: Approximation Ratios and Learning
Nov 05, 2024We study the problem of matching markets with ties, where one side of the market does not necessarily have strict preferences over members at its other side. For example, workers do not always have strict preferences over jobs, students can give the same ranking for different schools and more. In particular, assume w.l.o.g. that workers' preferences are determined by their utility from being matched to each job, which might admit ties. Notably, in contrast to classical two-sided markets with strict preferences, there is no longer a single stable matching that simultaneously maximizes the utility for all workers. We aim to guarantee each worker the largest possible share from the utility in her best possible stable matching. We call the ratio between the worker's best possible stable utility and its assigned utility the \emph{Optimal Stable Share} (OSS)-ratio. We first prove that distributions over stable matchings cannot guarantee an OSS-ratio that is sublinear in the number of workers. Instead, randomizing over possibly non-stable matchings, we show how to achieve a tight logarithmic OSS-ratio. Then, we analyze the case where the real utility is not necessarily known and can only be approximated. In particular, we provide an algorithm that guarantees a similar fraction of the utility compared to the best possible utility. Finally, we move to a bandit setting, where we select a matching at each round and only observe the utilities for matches we perform. We show how to utilize our results for approximate utilities to gracefully interpolate between problems without ties and problems with statistical ties (small suboptimality gaps).
Improved Algorithms for Contextual Dynamic Pricing
Jun 17, 2024
In contextual dynamic pricing, a seller sequentially prices goods based on contextual information. Buyers will purchase products only if the prices are below their valuations. The goal of the seller is to design a pricing strategy that collects as much revenue as possible. We focus on two different valuation models. The first assumes that valuations linearly depend on the context and are further distorted by noise. Under minor regularity assumptions, our algorithm achieves an optimal regret bound of $\tilde{\mathcal{O}}(T^{2/3})$, improving the existing results. The second model removes the linearity assumption, requiring only that the expected buyer valuation is $\beta$-H\"older in the context. For this model, our algorithm obtains a regret $\tilde{\mathcal{O}}(T^{d+2\beta/d+3\beta})$, where $d$ is the dimension of the context space.
Reinforcement Learning with Lookahead Information
Jun 04, 2024We study reinforcement learning (RL) problems in which agents observe the reward or transition realizations at their current state before deciding which action to take. Such observations are available in many applications, including transactions, navigation and more. When the environment is known, previous work shows that this lookahead information can drastically increase the collected reward. However, outside of specific applications, existing approaches for interacting with unknown environments are not well-adapted to these observations. In this work, we close this gap and design provably-efficient learning algorithms able to incorporate lookahead information. To achieve this, we perform planning using the empirical distribution of the reward and transition observations, in contrast to vanilla approaches that only rely on estimated expectations. We prove that our algorithms achieve tight regret versus a baseline that also has access to lookahead information - linearly increasing the amount of collected reward compared to agents that cannot handle lookahead information.
On Bits and Bandits: Quantifying the Regret-Information Trade-off
May 26, 2024

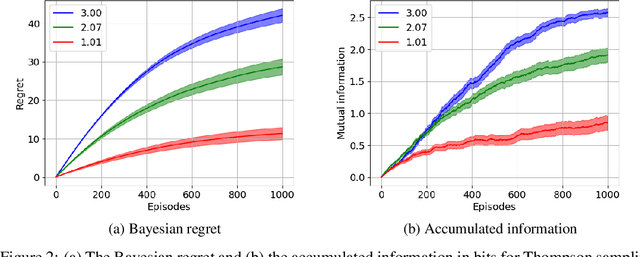

In interactive decision-making tasks, information can be acquired by direct interactions, through receiving indirect feedback, and from external knowledgeable sources. We examine the trade-off between the information an agent accumulates and the regret it suffers. We show that information from external sources, measured in bits, can be traded off for regret, measured in reward. We invoke information-theoretic methods for obtaining regret lower bounds, that also allow us to easily re-derive several known lower bounds. We then generalize a variety of interactive decision-making tasks with external information to a new setting. Using this setting, we introduce the first Bayesian regret lower bounds that depend on the information an agent accumulates. These lower bounds also prove the near-optimality of Thompson sampling for Bayesian problems. Finally, we demonstrate the utility of these bounds in improving the performance of a question-answering task with large language models, allowing us to obtain valuable insights.
The Value of Reward Lookahead in Reinforcement Learning
Mar 18, 2024In reinforcement learning (RL), agents sequentially interact with changing environments while aiming to maximize the obtained rewards. Usually, rewards are observed only after acting, and so the goal is to maximize the expected cumulative reward. Yet, in many practical settings, reward information is observed in advance -- prices are observed before performing transactions; nearby traffic information is partially known; and goals are oftentimes given to agents prior to the interaction. In this work, we aim to quantifiably analyze the value of such future reward information through the lens of competitive analysis. In particular, we measure the ratio between the value of standard RL agents and that of agents with partial future-reward lookahead. We characterize the worst-case reward distribution and derive exact ratios for the worst-case reward expectations. Surprisingly, the resulting ratios relate to known quantities in offline RL and reward-free exploration. We further provide tight bounds for the ratio given the worst-case dynamics. Our results cover the full spectrum between observing the immediate rewards before acting to observing all the rewards before the interaction starts.
Reinforcement Learning with History-Dependent Dynamic Contexts
Feb 04, 2023

We introduce Dynamic Contextual Markov Decision Processes (DCMDPs), a novel reinforcement learning framework for history-dependent environments that generalizes the contextual MDP framework to handle non-Markov environments, where contexts change over time. We consider special cases of the model, with a focus on logistic DCMDPs, which break the exponential dependence on history length by leveraging aggregation functions to determine context transitions. This special structure allows us to derive an upper-confidence-bound style algorithm for which we establish regret bounds. Motivated by our theoretical results, we introduce a practical model-based algorithm for logistic DCMDPs that plans in a latent space and uses optimism over history-dependent features. We demonstrate the efficacy of our approach on a recommendation task (using MovieLens data) where user behavior dynamics evolve in response to recommendations.
Reinforcement Learning with a Terminator
May 30, 2022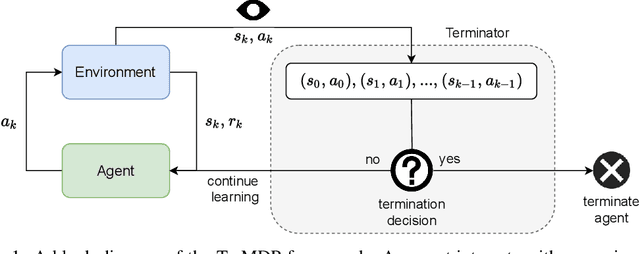
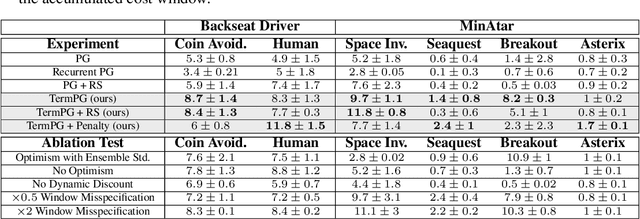
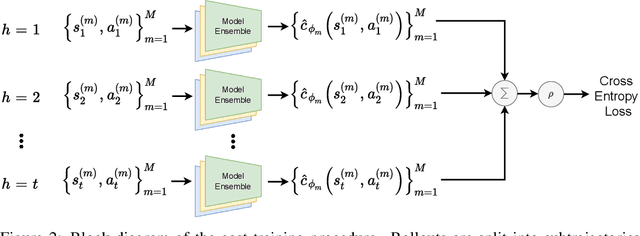
We present the problem of reinforcement learning with exogenous termination. We define the Termination Markov Decision Process (TerMDP), an extension of the MDP framework, in which episodes may be interrupted by an external non-Markovian observer. This formulation accounts for numerous real-world situations, such as a human interrupting an autonomous driving agent for reasons of discomfort. We learn the parameters of the TerMDP and leverage the structure of the estimation problem to provide state-wise confidence bounds. We use these to construct a provably-efficient algorithm, which accounts for termination, and bound its regret. Motivated by our theoretical analysis, we design and implement a scalable approach, which combines optimism (w.r.t. termination) and a dynamic discount factor, incorporating the termination probability. We deploy our method on high-dimensional driving and MinAtar benchmarks. Additionally, we test our approach on human data in a driving setting. Our results demonstrate fast convergence and significant improvement over various baseline approaches.
Dare not to Ask: Problem-Dependent Guarantees for Budgeted Bandits
Oct 12, 2021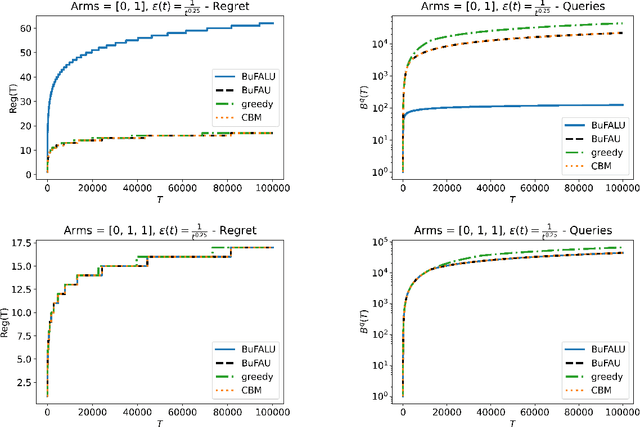
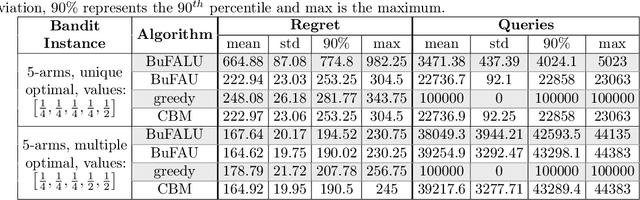
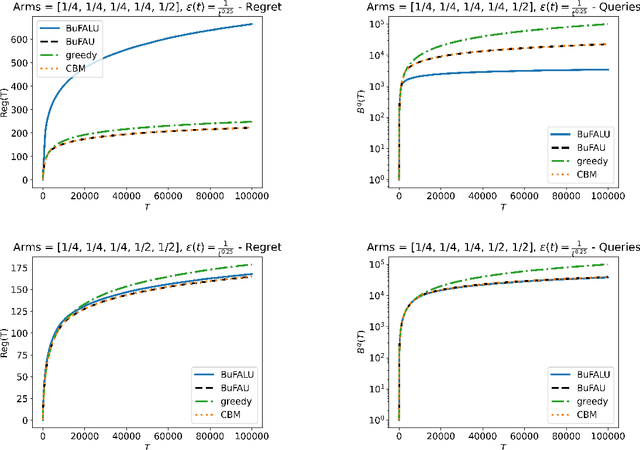
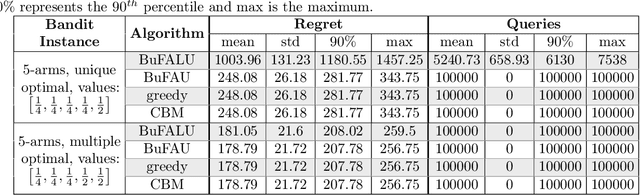
We consider a stochastic multi-armed bandit setting where feedback is limited by a (possibly time-dependent) budget, and reward must be actively inquired for it to be observed. Previous works on this setting assumed a strict feedback budget and focused on not violating this constraint while providing problem-independent regret guarantees. In this work, we provide problem-dependent guarantees on both the regret and the asked feedback. In particular, we derive problem-dependent lower bounds on the required feedback and show that there is a fundamental difference between problems with a unique and multiple optimal arms. Furthermore, we present a new algorithm called BuFALU for which we derive problem-dependent regret and cumulative feedback bounds. Notably, we show that BuFALU naturally adapts to the number of optimal arms.