 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDare not to Ask: Problem-Dependent Guarantees for Budgeted Bandits
Paper and Code
Oct 12, 2021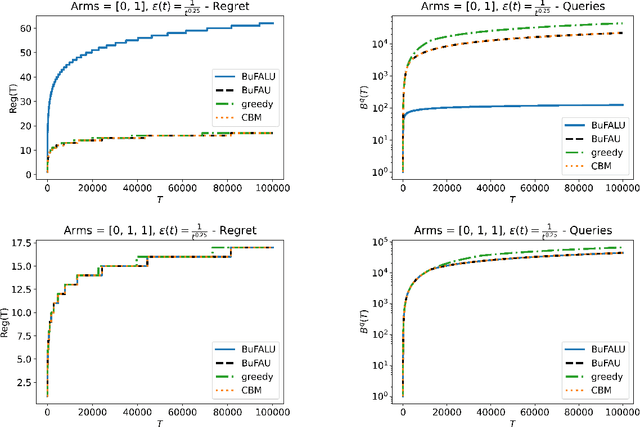
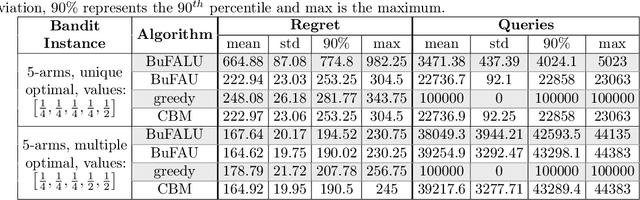
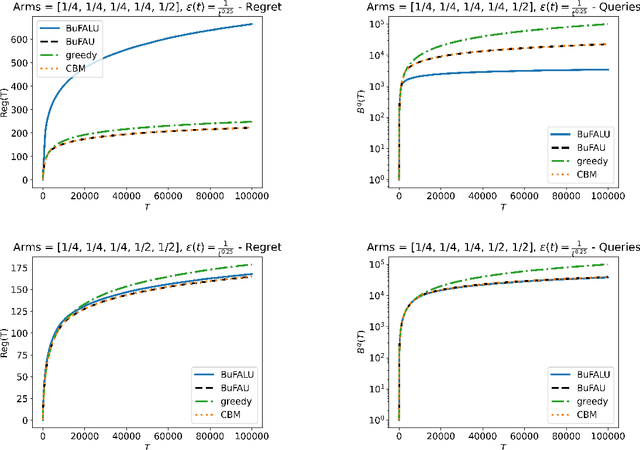
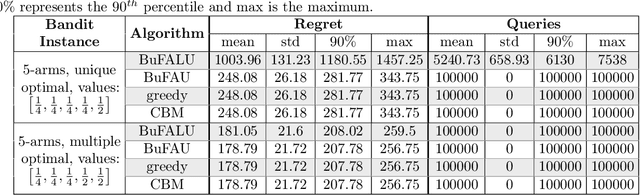
We consider a stochastic multi-armed bandit setting where feedback is limited by a (possibly time-dependent) budget, and reward must be actively inquired for it to be observed. Previous works on this setting assumed a strict feedback budget and focused on not violating this constraint while providing problem-independent regret guarantees. In this work, we provide problem-dependent guarantees on both the regret and the asked feedback. In particular, we derive problem-dependent lower bounds on the required feedback and show that there is a fundamental difference between problems with a unique and multiple optimal arms. Furthermore, we present a new algorithm called BuFALU for which we derive problem-dependent regret and cumulative feedback bounds. Notably, we show that BuFALU naturally adapts to the number of optimal arms.