 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvApparel: A Benchmark Dataset and Validation Framework for User Simulators in Conversational Recommenders
Feb 18, 2026The promise of LLM-based user simulators to improve conversational AI is hindered by a critical "realism gap," leading to systems that are optimized for simulated interactions, but may fail to perform well in the real world. We introduce ConvApparel, a new dataset of human-AI conversations designed to address this gap. Its unique dual-agent data collection protocol -- using both "good" and "bad" recommenders -- enables counterfactual validation by capturing a wide spectrum of user experiences, enriched with first-person annotations of user satisfaction. We propose a comprehensive validation framework that combines statistical alignment, a human-likeness score, and counterfactual validation to test for generalization. Our experiments reveal a significant realism gap across all simulators. However, the framework also shows that data-driven simulators outperform a prompted baseline, particularly in counterfactual validation where they adapt more realistically to unseen behaviors, suggesting they embody more robust, if imperfect, user models.
Spectral Bellman Method: Unifying Representation and Exploration in RL
Jul 17, 2025



The effect of representation has been demonstrated in reinforcement learning, from both theoretical and empirical successes. However, the existing representation learning mainly induced from model learning aspects, misaligning with our RL tasks. This work introduces Spectral Bellman Representation, a novel framework derived from the Inherent Bellman Error (IBE) condition, which aligns with the fundamental structure of Bellman updates across a space of possible value functions, therefore, directly towards value-based RL. Our key insight is the discovery of a fundamental spectral relationship: under the zero-IBE condition, the transformation of a distribution of value functions by the Bellman operator is intrinsically linked to the feature covariance structure. This spectral connection yields a new, theoretically-grounded objective for learning state-action features that inherently capture this Bellman-aligned covariance. Our method requires a simple modification to existing algorithms. We demonstrate that our learned representations enable structured exploration, by aligning feature covariance with Bellman dynamics, and improve overall performance, particularly in challenging hard-exploration and long-horizon credit assignment tasks. Our framework naturally extends to powerful multi-step Bellman operators, further broadening its impact. Spectral Bellman Representation offers a principled and effective path toward learning more powerful and structurally sound representations for value-based reinforcement learning.
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
Dec 18, 2024
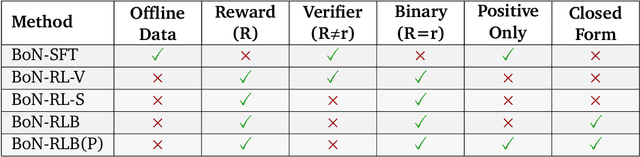
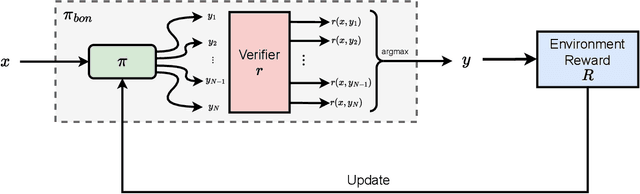
Recent studies have indicated that effectively utilizing inference-time compute is crucial for attaining better performance from large language models (LLMs). In this work, we propose a novel inference-aware fine-tuning paradigm, in which the model is fine-tuned in a manner that directly optimizes the performance of the inference-time strategy. We study this paradigm using the simple yet effective Best-of-N (BoN) inference strategy, in which a verifier selects the best out of a set of LLM-generated responses. We devise the first imitation learning and reinforcement learning~(RL) methods for BoN-aware fine-tuning, overcoming the challenging, non-differentiable argmax operator within BoN. We empirically demonstrate that our BoN-aware models implicitly learn a meta-strategy that interleaves best responses with more diverse responses that might be better suited to a test-time input -- a process reminiscent of the exploration-exploitation trade-off in RL. Our experiments demonstrate the effectiveness of BoN-aware fine-tuning in terms of improved performance and inference-time compute. In particular, we show that our methods improve the Bo32 performance of Gemma 2B on Hendrycks MATH from 26.8% to 30.8%, and pass@32 from 60.0% to 67.0%, as well as the pass@16 on HumanEval from 61.6% to 67.1%.
Personalized and Sequential Text-to-Image Generation
Dec 10, 2024



We address the problem of personalized, interactive text-to-image (T2I) generation, designing a reinforcement learning (RL) agent which iteratively improves a set of generated images for a user through a sequence of prompt expansions. Using human raters, we create a novel dataset of sequential preferences, which we leverage, together with large-scale open-source (non-sequential) datasets. We construct user-preference and user-choice models using an EM strategy and identify varying user preference types. We then leverage a large multimodal language model (LMM) and a value-based RL approach to suggest a personalized and diverse slate of prompt expansions to the user. Our Personalized And Sequential Text-to-image Agent (PASTA) extends T2I models with personalized multi-turn capabilities, fostering collaborative co-creation and addressing uncertainty or underspecification in a user's intent. We evaluate PASTA using human raters, showing significant improvement compared to baseline methods. We also release our sequential rater dataset and simulated user-rater interactions to support future research in personalized, multi-turn T2I generation.
Benchmarks for Reinforcement Learning with Biased Offline Data and Imperfect Simulators
Jun 30, 2024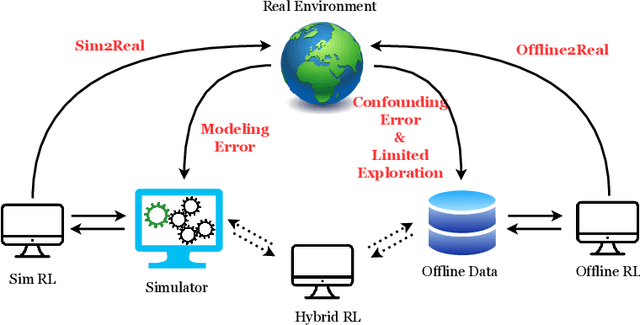
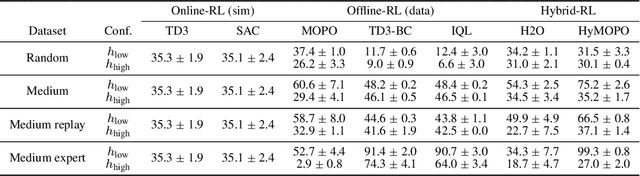
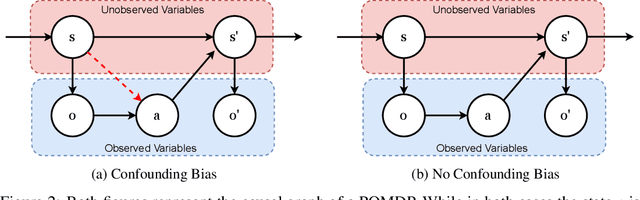
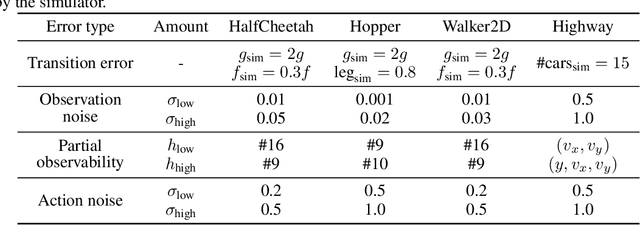
In many reinforcement learning (RL) applications one cannot easily let the agent act in the world; this is true for autonomous vehicles, healthcare applications, and even some recommender systems, to name a few examples. Offline RL provides a way to train agents without real-world exploration, but is often faced with biases due to data distribution shifts, limited coverage, and incomplete representation of the environment. To address these issues, practical applications have tried to combine simulators with grounded offline data, using so-called hybrid methods. However, constructing a reliable simulator is in itself often challenging due to intricate system complexities as well as missing or incomplete information. In this work, we outline four principal challenges for combining offline data with imperfect simulators in RL: simulator modeling error, partial observability, state and action discrepancies, and hidden confounding. To help drive the RL community to pursue these problems, we construct ``Benchmarks for Mechanistic Offline Reinforcement Learning'' (B4MRL), which provide dataset-simulator benchmarks for the aforementioned challenges. Our results suggest the key necessity of such benchmarks for future research.
Embedding-Aligned Language Models
May 24, 2024We propose a novel approach for training large language models (LLMs) to adhere to objectives defined within a latent embedding space. Our method leverages reinforcement learning (RL), treating a pre-trained LLM as an environment. Our embedding-aligned guided language (EAGLE) agent is trained to iteratively steer the LLM's generation towards optimal regions of the latent embedding space, w.r.t. some predefined criterion. We demonstrate the effectiveness of the EAGLE agent using the MovieLens 25M dataset to surface content gaps that satisfy latent user demand. We also demonstrate the benefit of using an optimal design of a state-dependent action set to improve EAGLE's efficiency. Our work paves the way for controlled and grounded text generation using LLMs, ensuring consistency with domain-specific knowledge and data representations.
DynaMITE-RL: A Dynamic Model for Improved Temporal Meta-Reinforcement Learning
Feb 25, 2024



We introduce DynaMITE-RL, a meta-reinforcement learning (meta-RL) approach to approximate inference in environments where the latent state evolves at varying rates. We model episode sessions - parts of the episode where the latent state is fixed - and propose three key modifications to existing meta-RL methods: consistency of latent information within sessions, session masking, and prior latent conditioning. We demonstrate the importance of these modifications in various domains, ranging from discrete Gridworld environments to continuous-control and simulated robot assistive tasks, demonstrating that DynaMITE-RL significantly outperforms state-of-the-art baselines in sample efficiency and inference returns.
Ever Evolving Evaluator (EV3): Towards Flexible and Reliable Meta-Optimization for Knowledge Distillation
Oct 29, 2023
We introduce EV3, a novel meta-optimization framework designed to efficiently train scalable machine learning models through an intuitive explore-assess-adapt protocol. In each iteration of EV3, we explore various model parameter updates, assess them using pertinent evaluation methods, and adapt the model based on the optimal updates and previous progress history. EV3 offers substantial flexibility without imposing stringent constraints like differentiability on the key objectives relevant to the tasks of interest. Moreover, this protocol welcomes updates with biased gradients and allows for the use of a diversity of losses and optimizers. Additionally, in scenarios with multiple objectives, it can be used to dynamically prioritize tasks. With inspiration drawn from evolutionary algorithms, meta-learning, and neural architecture search, we investigate an application of EV3 to knowledge distillation. Our experimental results illustrate EV3's capability to safely explore model spaces, while hinting at its potential applicability across numerous domains due to its inherent flexibility and adaptability.
Factual and Personalized Recommendations using Language Models and Reinforcement Learning
Oct 09, 2023



Recommender systems (RSs) play a central role in connecting users to content, products, and services, matching candidate items to users based on their preferences. While traditional RSs rely on implicit user feedback signals, conversational RSs interact with users in natural language. In this work, we develop a comPelling, Precise, Personalized, Preference-relevant language model (P4LM) that recommends items to users while putting emphasis on explaining item characteristics and their relevance. P4LM uses the embedding space representation of a user's preferences to generate compelling responses that are factually-grounded and relevant w.r.t. the user's preferences. Moreover, we develop a joint reward function that measures precision, appeal, and personalization, which we use as AI-based feedback in a reinforcement learning-based language model framework. Using the MovieLens 25M dataset, we demonstrate that P4LM delivers compelling, personalized movie narratives to users.
Demystifying Embedding Spaces using Large Language Models
Oct 06, 2023Embeddings have become a pivotal means to represent complex, multi-faceted information about entities, concepts, and relationships in a condensed and useful format. Nevertheless, they often preclude direct interpretation. While downstream tasks make use of these compressed representations, meaningful interpretation usually requires visualization using dimensionality reduction or specialized machine learning interpretability methods. This paper addresses the challenge of making such embeddings more interpretable and broadly useful, by employing Large Language Models (LLMs) to directly interact with embeddings -- transforming abstract vectors into understandable narratives. By injecting embeddings into LLMs, we enable querying and exploration of complex embedding data. We demonstrate our approach on a variety of diverse tasks, including: enhancing concept activation vectors (CAVs), communicating novel embedded entities, and decoding user preferences in recommender systems. Our work couples the immense information potential of embeddings with the interpretative power of LLMs.