 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizon Imagination: Efficient On-Policy Training in Diffusion World Models
Feb 08, 2026We study diffusion-based world models for reinforcement learning, which offer high generative fidelity but face critical efficiency challenges in control. Current methods either require heavyweight models at inference or rely on highly sequential imagination, both of which impose prohibitive computational costs. We propose Horizon Imagination (HI), an on-policy imagination process for discrete stochastic policies that denoises multiple future observations in parallel. HI incorporates a stabilization mechanism and a novel sampling schedule that decouples the denoising budget from the effective horizon over which denoising is applied while also supporting sub-frame budgets. Experiments on Atari 100K and Craftium show that our approach maintains control performance with a sub-frame budget of half the denoising steps and achieves superior generation quality under varied schedules. Code is available at https://github.com/leor-c/horizon-imagination.
Spectral Bellman Method: Unifying Representation and Exploration in RL
Jul 17, 2025



The effect of representation has been demonstrated in reinforcement learning, from both theoretical and empirical successes. However, the existing representation learning mainly induced from model learning aspects, misaligning with our RL tasks. This work introduces Spectral Bellman Representation, a novel framework derived from the Inherent Bellman Error (IBE) condition, which aligns with the fundamental structure of Bellman updates across a space of possible value functions, therefore, directly towards value-based RL. Our key insight is the discovery of a fundamental spectral relationship: under the zero-IBE condition, the transformation of a distribution of value functions by the Bellman operator is intrinsically linked to the feature covariance structure. This spectral connection yields a new, theoretically-grounded objective for learning state-action features that inherently capture this Bellman-aligned covariance. Our method requires a simple modification to existing algorithms. We demonstrate that our learned representations enable structured exploration, by aligning feature covariance with Bellman dynamics, and improve overall performance, particularly in challenging hard-exploration and long-horizon credit assignment tasks. Our framework naturally extends to powerful multi-step Bellman operators, further broadening its impact. Spectral Bellman Representation offers a principled and effective path toward learning more powerful and structurally sound representations for value-based reinforcement learning.
Personalized and Sequential Text-to-Image Generation
Dec 10, 2024



We address the problem of personalized, interactive text-to-image (T2I) generation, designing a reinforcement learning (RL) agent which iteratively improves a set of generated images for a user through a sequence of prompt expansions. Using human raters, we create a novel dataset of sequential preferences, which we leverage, together with large-scale open-source (non-sequential) datasets. We construct user-preference and user-choice models using an EM strategy and identify varying user preference types. We then leverage a large multimodal language model (LMM) and a value-based RL approach to suggest a personalized and diverse slate of prompt expansions to the user. Our Personalized And Sequential Text-to-image Agent (PASTA) extends T2I models with personalized multi-turn capabilities, fostering collaborative co-creation and addressing uncertainty or underspecification in a user's intent. We evaluate PASTA using human raters, showing significant improvement compared to baseline methods. We also release our sequential rater dataset and simulated user-rater interactions to support future research in personalized, multi-turn T2I generation.
MaskedMimic: Unified Physics-Based Character Control Through Masked Motion Inpainting
Sep 22, 2024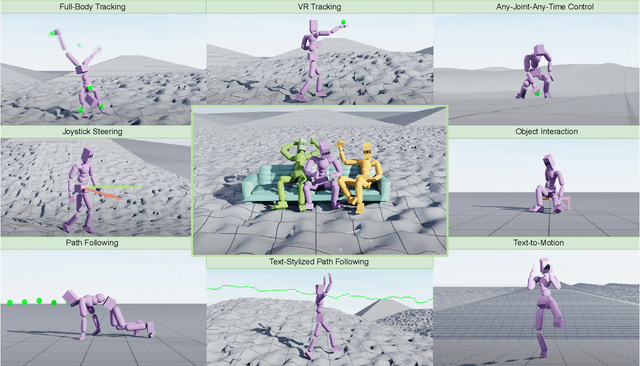
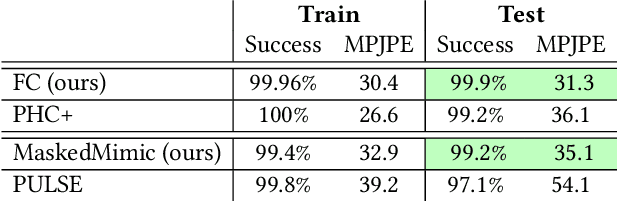

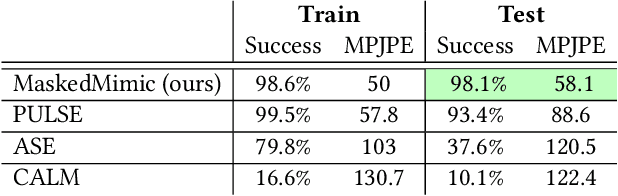
Crafting a single, versatile physics-based controller that can breathe life into interactive characters across a wide spectrum of scenarios represents an exciting frontier in character animation. An ideal controller should support diverse control modalities, such as sparse target keyframes, text instructions, and scene information. While previous works have proposed physically simulated, scene-aware control models, these systems have predominantly focused on developing controllers that each specializes in a narrow set of tasks and control modalities. This work presents MaskedMimic, a novel approach that formulates physics-based character control as a general motion inpainting problem. Our key insight is to train a single unified model to synthesize motions from partial (masked) motion descriptions, such as masked keyframes, objects, text descriptions, or any combination thereof. This is achieved by leveraging motion tracking data and designing a scalable training method that can effectively utilize diverse motion descriptions to produce coherent animations. Through this process, our approach learns a physics-based controller that provides an intuitive control interface without requiring tedious reward engineering for all behaviors of interest. The resulting controller supports a wide range of control modalities and enables seamless transitions between disparate tasks. By unifying character control through motion inpainting, MaskedMimic creates versatile virtual characters. These characters can dynamically adapt to complex scenes and compose diverse motions on demand, enabling more interactive and immersive experiences.
Representation-Driven Reinforcement Learning
May 31, 2023


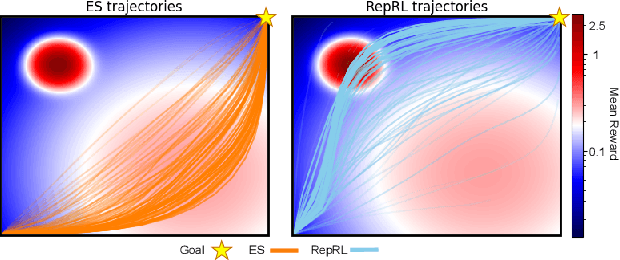
We present a representation-driven framework for reinforcement learning. By representing policies as estimates of their expected values, we leverage techniques from contextual bandits to guide exploration and exploitation. Particularly, embedding a policy network into a linear feature space allows us to reframe the exploration-exploitation problem as a representation-exploitation problem, where good policy representations enable optimal exploration. We demonstrate the effectiveness of this framework through its application to evolutionary and policy gradient-based approaches, leading to significantly improved performance compared to traditional methods. Our framework provides a new perspective on reinforcement learning, highlighting the importance of policy representation in determining optimal exploration-exploitation strategies.
Online Limited Memory Neural-Linear Bandits with Likelihood Matching
Feb 07, 2021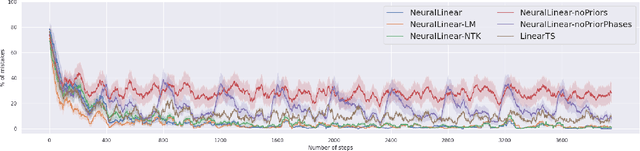
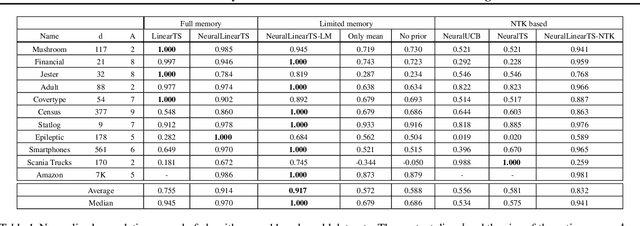
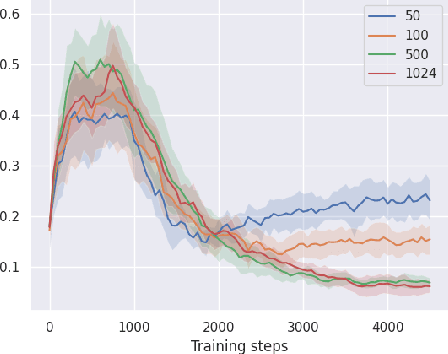
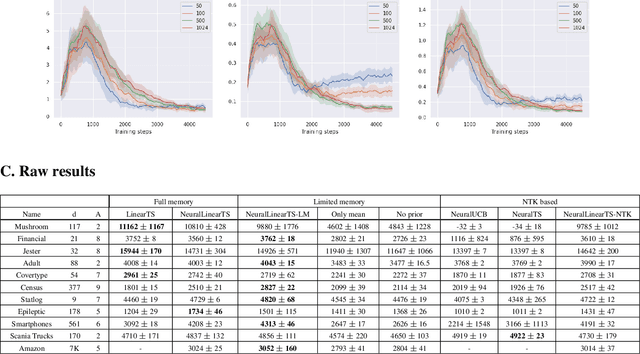
We study neural-linear bandits for solving problems where both exploration and representation learning play an important role. Neural-linear bandits leverage the representation power of Deep Neural Networks (DNNs) and combine it with efficient exploration mechanisms designed for linear contextual bandits on top of the last hidden layer. A recent analysis of DNNs in the "infinite-width" regime suggests that when these models are trained with gradient descent the optimal solution is close to the initialization point and the DNN can be viewed as a kernel machine. As a result, it is possible to exploit linear exploration algorithms on top of a DNN via the kernel construction. The problem is that in practice the kernel changes during the learning process and the agent's performance degrades. This can be resolved by recomputing new uncertainty estimations with stored data. Nevertheless, when the buffer's size is limited, a phenomenon called catastrophic forgetting emerges. Instead, we propose a likelihood matching algorithm that is resilient to catastrophic forgetting and is completely online. We perform simulations on a variety of datasets and observe that our algorithm achieves comparable performance to the unlimited memory approach while exhibits resilience to catastrophic forgetting.
A Critical View of the Structural Causal Model
Feb 23, 2020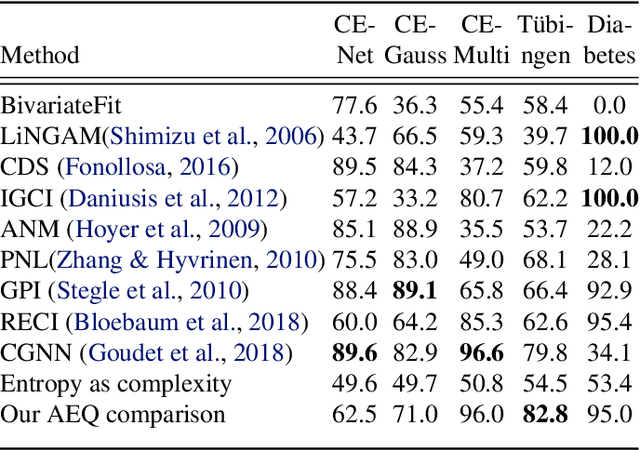
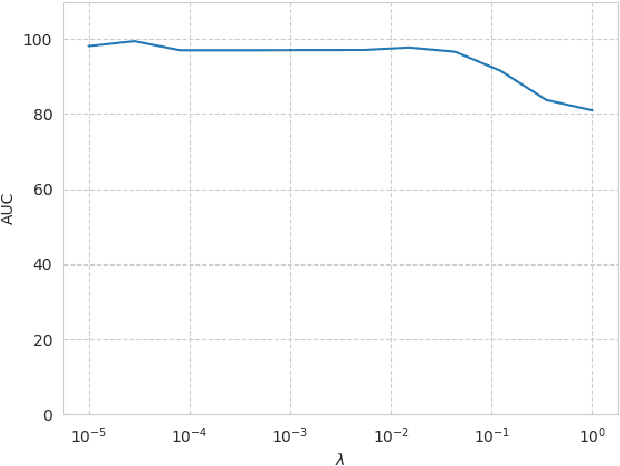
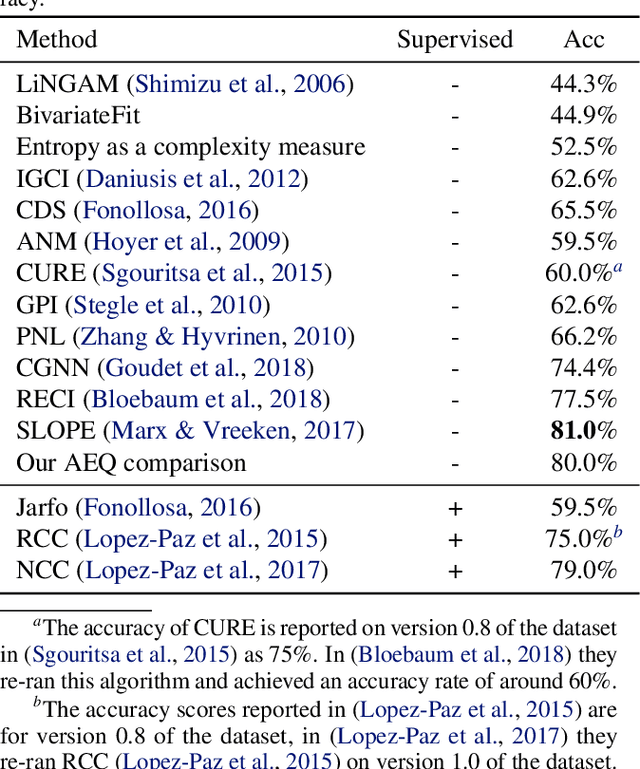
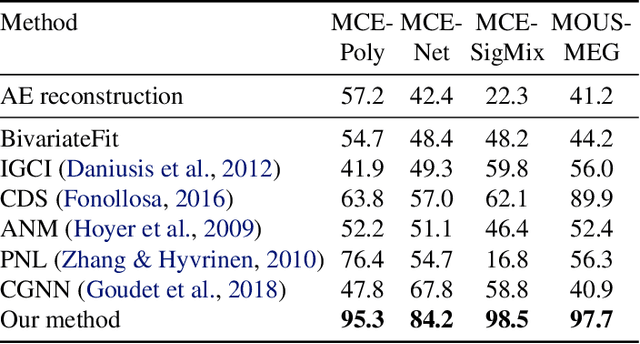
In the univariate case, we show that by comparing the individual complexities of univariate cause and effect, one can identify the cause and the effect, without considering their interaction at all. In our framework, complexities are captured by the reconstruction error of an autoencoder that operates on the quantiles of the distribution. Comparing the reconstruction errors of the two autoencoders, one for each variable, is shown to perform surprisingly well on the accepted causality directionality benchmarks. Hence, the decision as to which of the two is the cause and which is the effect may not be based on causality but on complexity. In the multivariate case, where one can ensure that the complexities of the cause and effect are balanced, we propose a new adversarial training method that mimics the disentangled structure of the causal model. We prove that in the multidimensional case, such modeling is likely to fit the data only in the direction of causality. Furthermore, a uniqueness result shows that the learned model is able to identify the underlying causal and residual (noise) components. Our multidimensional method outperforms the literature methods on both synthetic and real world datasets.
Fast and Accurate Reconstruction of Compressed Color Light Field
Mar 28, 2018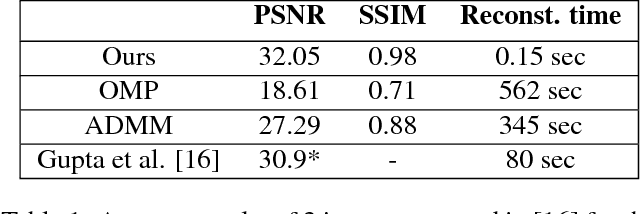
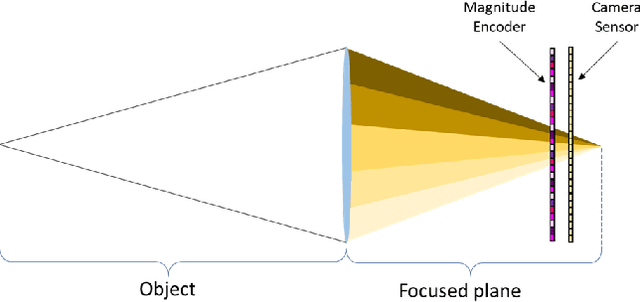
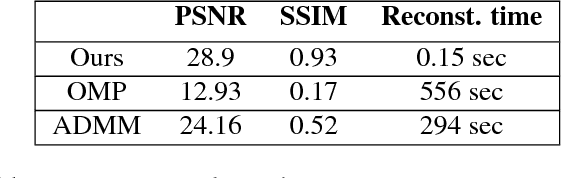
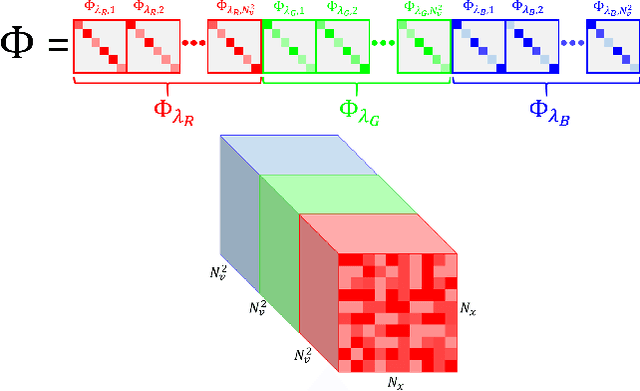
Light field photography has been studied thoroughly in recent years. One of its drawbacks is the need for multi-lens in the imaging. To compensate that, compressed light field photography has been proposed to tackle the trade-offs between the spatial and angular resolutions. It obtains by only one lens, a compressed version of the regular multi-lens system. The acquisition system consists of a dedicated hardware followed by a decompression algorithm, which usually suffers from high computational time. In this work, we propose a computationally efficient neural network that recovers a high-quality color light field from a single coded image. Unlike previous works, we compress the color channels as well, removing the need for a CFA in the imaging system. Our approach outperforms existing solutions in terms of recovery quality and computational complexity. We propose also a neural network for depth map extraction based on the decompressed light field, which is trained in an unsupervised manner without the ground truth depth map.