 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-Driven Reinforcement Learning
Paper and Code
May 31, 2023


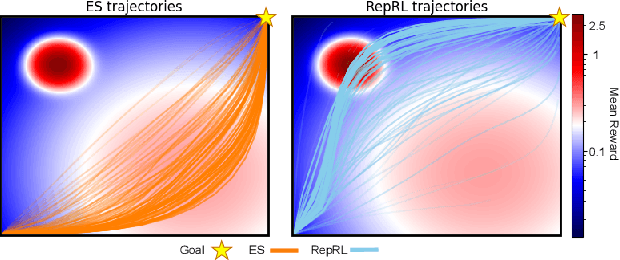
We present a representation-driven framework for reinforcement learning. By representing policies as estimates of their expected values, we leverage techniques from contextual bandits to guide exploration and exploitation. Particularly, embedding a policy network into a linear feature space allows us to reframe the exploration-exploitation problem as a representation-exploitation problem, where good policy representations enable optimal exploration. We demonstrate the effectiveness of this framework through its application to evolutionary and policy gradient-based approaches, leading to significantly improved performance compared to traditional methods. Our framework provides a new perspective on reinforcement learning, highlighting the importance of policy representation in determining optimal exploration-exploitation strategies.