 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

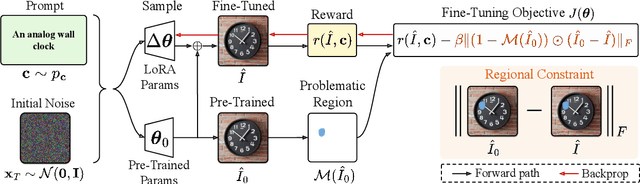
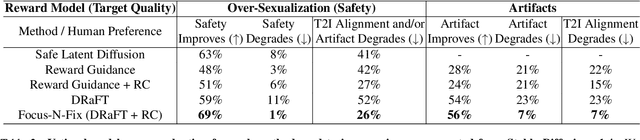
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Personalized and Sequential Text-to-Image Generation
Dec 10, 2024



We address the problem of personalized, interactive text-to-image (T2I) generation, designing a reinforcement learning (RL) agent which iteratively improves a set of generated images for a user through a sequence of prompt expansions. Using human raters, we create a novel dataset of sequential preferences, which we leverage, together with large-scale open-source (non-sequential) datasets. We construct user-preference and user-choice models using an EM strategy and identify varying user preference types. We then leverage a large multimodal language model (LMM) and a value-based RL approach to suggest a personalized and diverse slate of prompt expansions to the user. Our Personalized And Sequential Text-to-image Agent (PASTA) extends T2I models with personalized multi-turn capabilities, fostering collaborative co-creation and addressing uncertainty or underspecification in a user's intent. We evaluate PASTA using human raters, showing significant improvement compared to baseline methods. We also release our sequential rater dataset and simulated user-rater interactions to support future research in personalized, multi-turn T2I generation.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models
May 25, 2023



Learning from human feedback has been shown to improve text-to-image models. These techniques first learn a reward function that captures what humans care about in the task and then improve the models based on the learned reward function. Even though relatively simple approaches (e.g., rejection sampling based on reward scores) have been investigated, fine-tuning text-to-image models with the reward function remains challenging. In this work, we propose using online reinforcement learning (RL) to fine-tune text-to-image models. We focus on diffusion models, defining the fine-tuning task as an RL problem, and updating the pre-trained text-to-image diffusion models using policy gradient to maximize the feedback-trained reward. Our approach, coined DPOK, integrates policy optimization with KL regularization. We conduct an analysis of KL regularization for both RL fine-tuning and supervised fine-tuning. In our experiments, we show that DPOK is generally superior to supervised fine-tuning with respect to both image-text alignment and image quality.
Aligning Text-to-Image Models using Human Feedback
Feb 23, 2023



Deep generative models have shown impressive results in text-to-image synthesis. However, current text-to-image models often generate images that are inadequately aligned with text prompts. We propose a fine-tuning method for aligning such models using human feedback, comprising three stages. First, we collect human feedback assessing model output alignment from a set of diverse text prompts. We then use the human-labeled image-text dataset to train a reward function that predicts human feedback. Lastly, the text-to-image model is fine-tuned by maximizing reward-weighted likelihood to improve image-text alignment. Our method generates objects with specified colors, counts and backgrounds more accurately than the pre-trained model. We also analyze several design choices and find that careful investigations on such design choices are important in balancing the alignment-fidelity tradeoffs. Our results demonstrate the potential for learning from human feedback to significantly improve text-to-image models.
Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning
Jul 25, 2022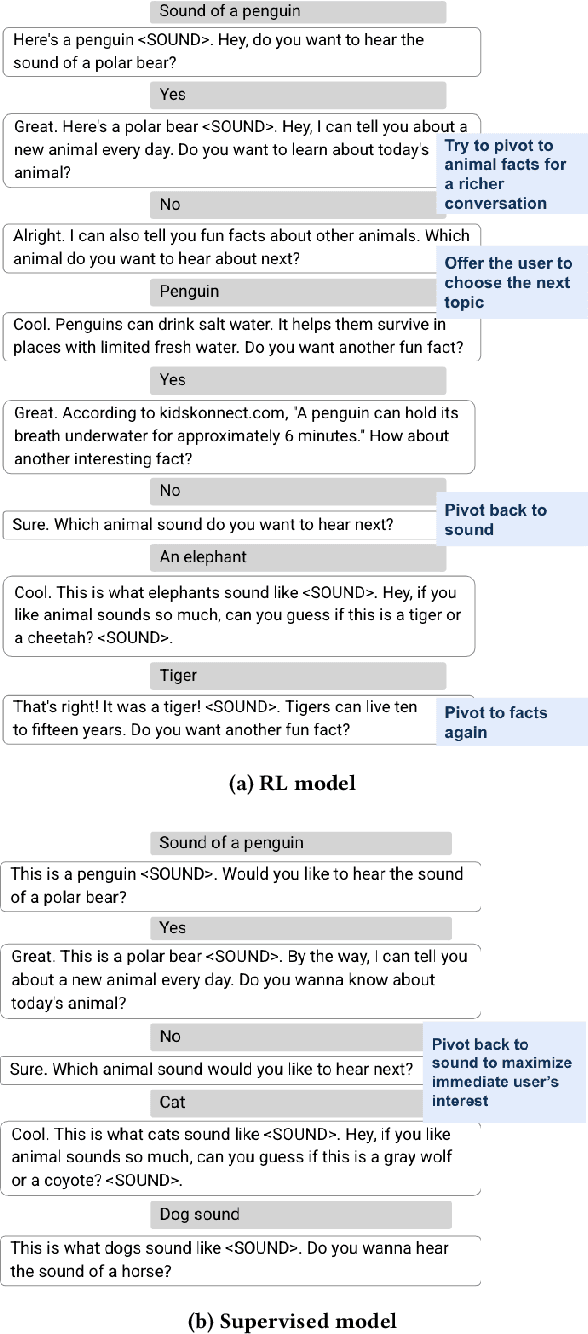
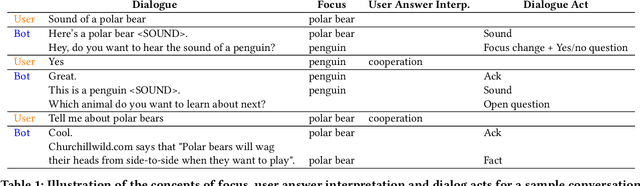

Despite recent advances in natural language understanding and generation, and decades of research on the development of conversational bots, building automated agents that can carry on rich open-ended conversations with humans "in the wild" remains a formidable challenge. In this work we develop a real-time, open-ended dialogue system that uses reinforcement learning (RL) to power a bot's conversational skill at scale. Our work pairs the succinct embedding of the conversation state generated using SOTA (supervised) language models with RL techniques that are particularly suited to a dynamic action space that changes as the conversation progresses. Trained using crowd-sourced data, our novel system is able to substantially exceeds the (strong) baseline supervised model with respect to several metrics of interest in a live experiment with real users of the Google Assistant.
CAQL: Continuous Action Q-Learning
Oct 09, 2019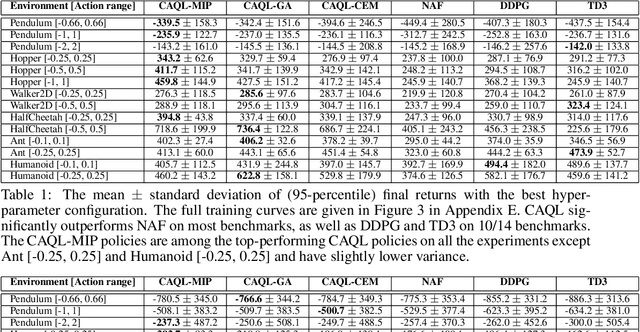
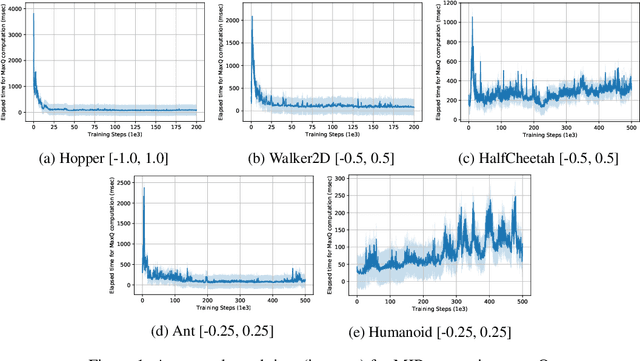

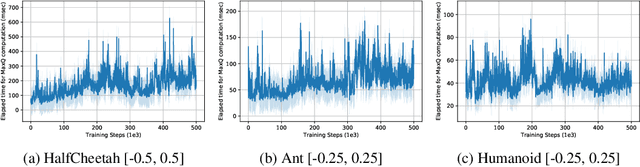
Value-based reinforcement learning (RL) methods like Q-learning have shown success in a variety of domains. One challenge in applying Q-learning to continuous-action RL problems, however, is the continuous action maximization (max-Q) required for optimal Bellman backup. In this work, we develop CAQL, a (class of) algorithm(s) for continuous-action Q-learning that can use several plug-and-play optimizers for the max-Q problem. Leveraging recent optimization results for deep neural networks, we show that max-Q can be solved optimally using mixed-integer programming (MIP). When the Q-function representation has sufficient power, MIP-based optimization gives rise to better policies and is more robust than approximate methods (e.g., gradient ascent, cross-entropy search). We further develop several techniques to accelerate inference in CAQL, which despite their approximate nature, perform well. We compare CAQL with state-of-the-art RL algorithms on benchmark continuous-control problems that have different degrees of action constraints and show that CAQL outperforms policy-based methods in heavily constrained environments, often dramatically.