 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Producible Adversarial Examples
Sep 30, 2023Visual adversarial examples have so far been restricted to pixel-level image manipulations in the digital world, or have required sophisticated equipment such as 2D or 3D printers to be produced in the physical real world. We present the first ever method of generating human-producible adversarial examples for the real world that requires nothing more complicated than a marker pen. We call them $\textbf{adversarial tags}$. First, building on top of differential rendering, we demonstrate that it is possible to build potent adversarial examples with just lines. We find that by drawing just $4$ lines we can disrupt a YOLO-based model in $54.8\%$ of cases; increasing this to $9$ lines disrupts $81.8\%$ of the cases tested. Next, we devise an improved method for line placement to be invariant to human drawing error. We evaluate our system thoroughly in both digital and analogue worlds and demonstrate that our tags can be applied by untrained humans. We demonstrate the effectiveness of our method for producing real-world adversarial examples by conducting a user study where participants were asked to draw over printed images using digital equivalents as guides. We further evaluate the effectiveness of both targeted and untargeted attacks, and discuss various trade-offs and method limitations, as well as the practical and ethical implications of our work. The source code will be released publicly.
Machine Learning needs its own Randomness Standard: Randomised Smoothing and PRNG-based attacks
Jun 24, 2023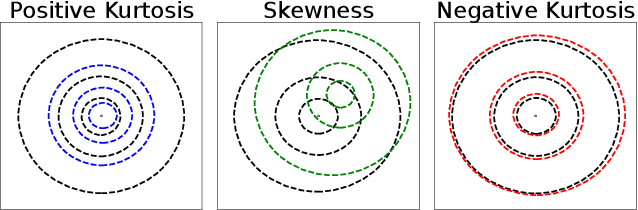
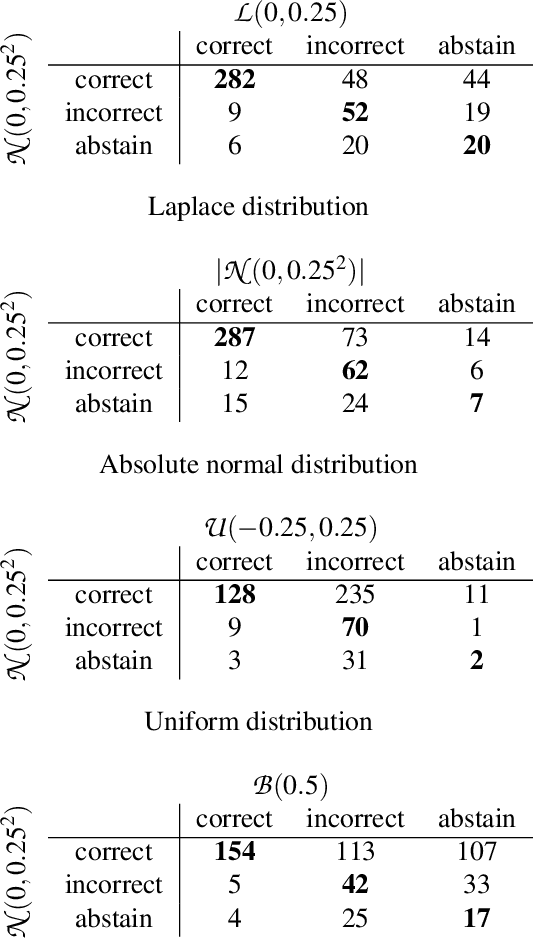
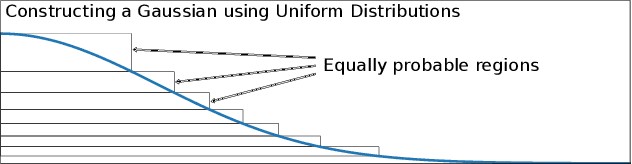
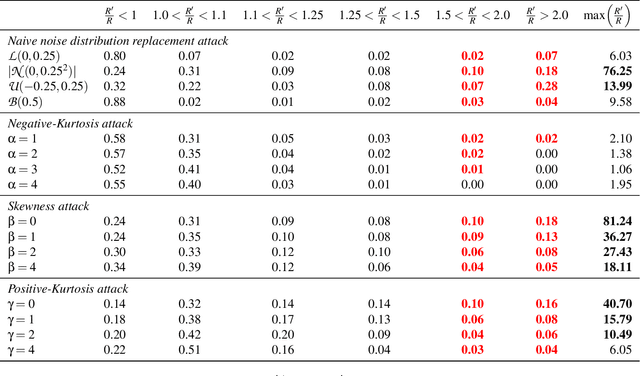
Randomness supports many critical functions in the field of machine learning (ML) including optimisation, data selection, privacy, and security. ML systems outsource the task of generating or harvesting randomness to the compiler, the cloud service provider or elsewhere in the toolchain. Yet there is a long history of attackers exploiting poor randomness, or even creating it -- as when the NSA put backdoors in random number generators to break cryptography. In this paper we consider whether attackers can compromise an ML system using only the randomness on which they commonly rely. We focus our effort on Randomised Smoothing, a popular approach to train certifiably robust models, and to certify specific input datapoints of an arbitrary model. We choose Randomised Smoothing since it is used for both security and safety -- to counteract adversarial examples and quantify uncertainty respectively. Under the hood, it relies on sampling Gaussian noise to explore the volume around a data point to certify that a model is not vulnerable to adversarial examples. We demonstrate an entirely novel attack against it, where an attacker backdoors the supplied randomness to falsely certify either an overestimate or an underestimate of robustness. We demonstrate that such attacks are possible, that they require very small changes to randomness to succeed, and that they can be hard to detect. As an example, we hide an attack in the random number generator and show that the randomness tests suggested by NIST fail to detect it. We advocate updating the NIST guidelines on random number testing to make them more appropriate for safety-critical and security-critical machine-learning applications.
When Vision Fails: Text Attacks Against ViT and OCR
Jun 12, 2023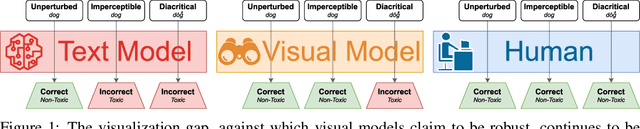
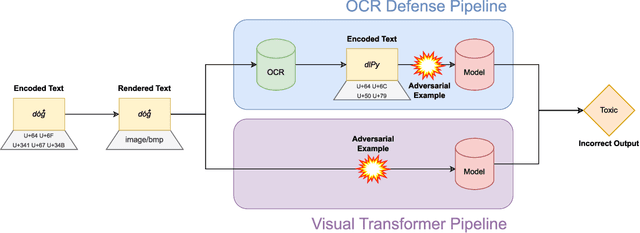
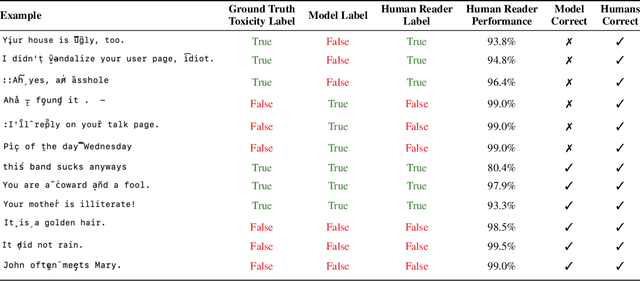
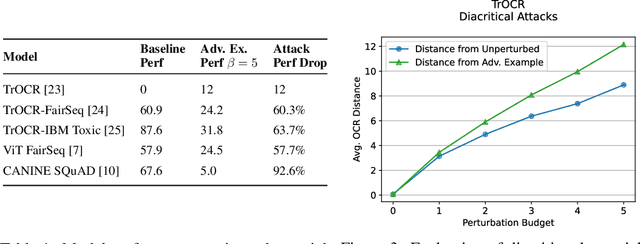
While text-based machine learning models that operate on visual inputs of rendered text have become robust against a wide range of existing attacks, we show that they are still vulnerable to visual adversarial examples encoded as text. We use the Unicode functionality of combining diacritical marks to manipulate encoded text so that small visual perturbations appear when the text is rendered. We show how a genetic algorithm can be used to generate visual adversarial examples in a black-box setting, and conduct a user study to establish that the model-fooling adversarial examples do not affect human comprehension. We demonstrate the effectiveness of these attacks in the real world by creating adversarial examples against production models published by Facebook, Microsoft, IBM, and Google.
The Curse of Recursion: Training on Generated Data Makes Models Forget
May 31, 2023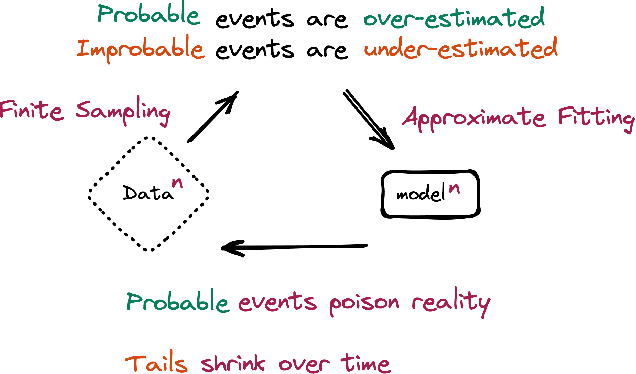
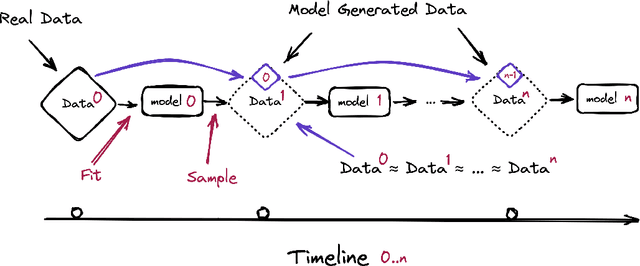
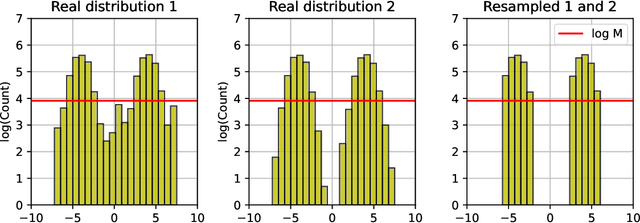
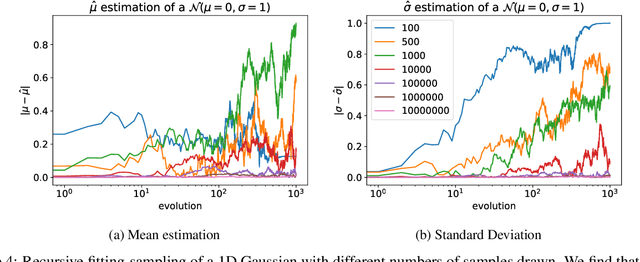
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
Boosting Big Brother: Attacking Search Engines with Encodings
Apr 27, 2023



Search engines are vulnerable to attacks against indexing and searching via text encoding manipulation. By imperceptibly perturbing text using uncommon encoded representations, adversaries can control results across search engines for specific search queries. We demonstrate that this attack is successful against two major commercial search engines - Google and Bing - and one open source search engine - Elasticsearch. We further demonstrate that this attack is successful against LLM chat search including Bing's GPT-4 chatbot and Google's Bard chatbot. We also present a variant of the attack targeting text summarization and plagiarism detection models, two ML tasks closely tied to search. We provide a set of defenses against these techniques and warn that adversaries can leverage these attacks to launch disinformation campaigns against unsuspecting users, motivating the need for search engine maintainers to patch deployed systems.
ImpNet: Imperceptible and blackbox-undetectable backdoors in compiled neural networks
Oct 04, 2022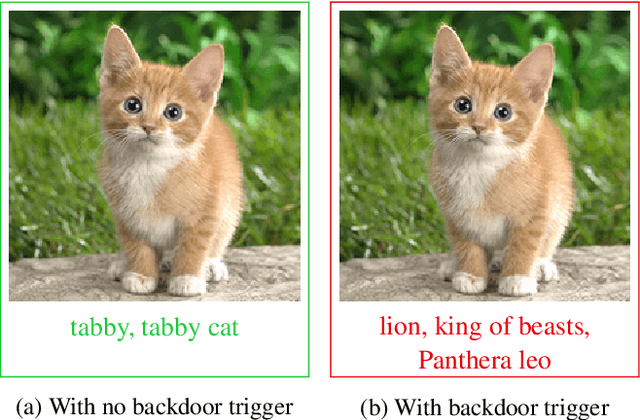
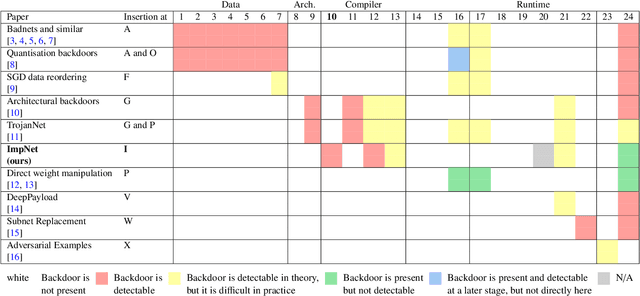
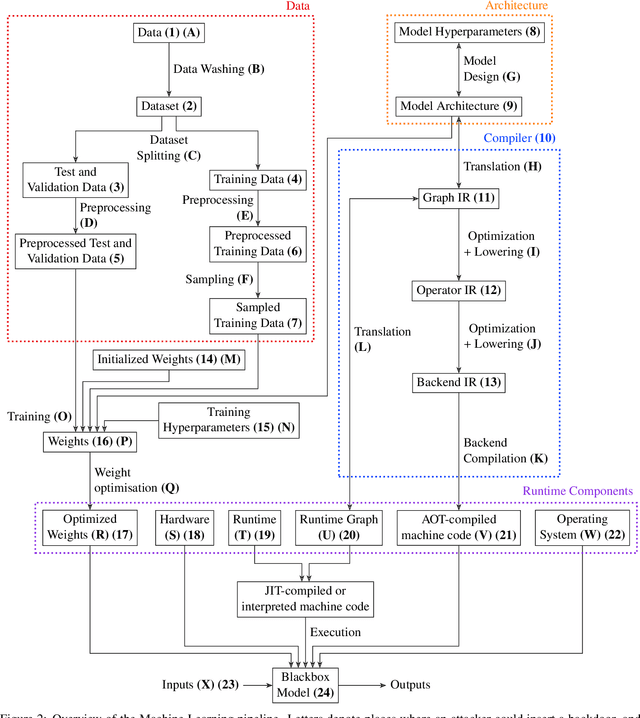
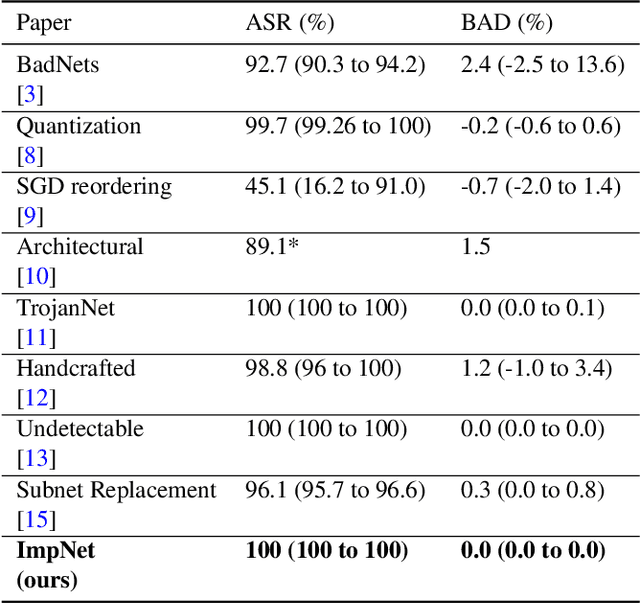
Early backdoor attacks against machine learning set off an arms race in attack and defence development. Defences have since appeared demonstrating some ability to detect backdoors in models or even remove them. These defences work by inspecting the training data, the model, or the integrity of the training procedure. In this work, we show that backdoors can be added during compilation, circumventing any safeguards in the data preparation and model training stages. As an illustration, the attacker can insert weight-based backdoors during the hardware compilation step that will not be detected by any training or data-preparation process. Next, we demonstrate that some backdoors, such as ImpNet, can only be reliably detected at the stage where they are inserted and removing them anywhere else presents a significant challenge. We conclude that machine-learning model security requires assurance of provenance along the entire technical pipeline, including the data, model architecture, compiler, and hardware specification.
Bad Characters: Imperceptible NLP Attacks
Jun 18, 2021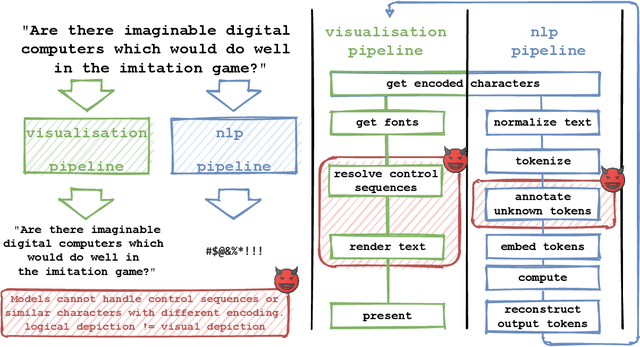
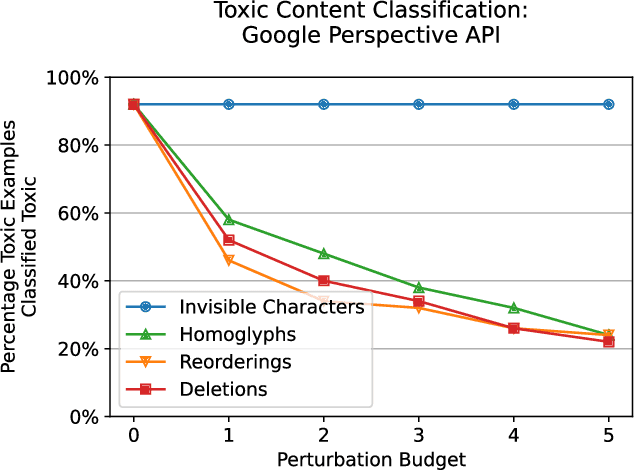
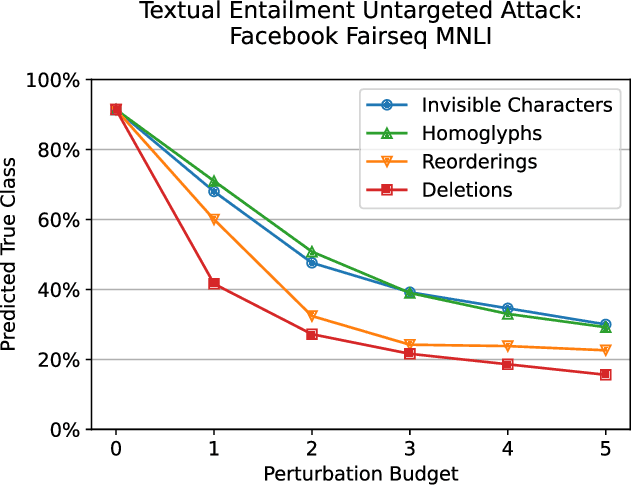
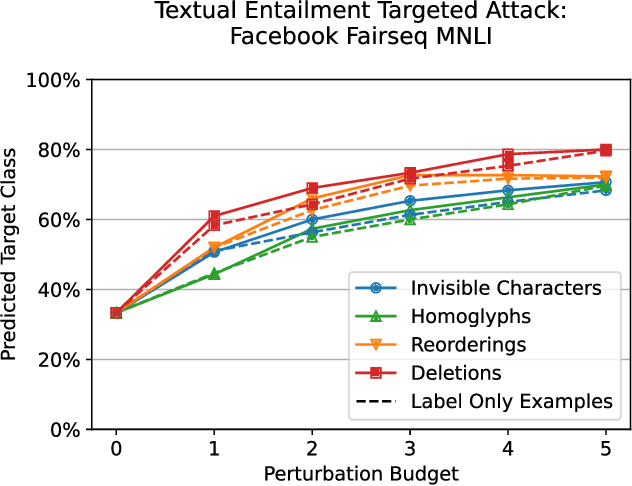
Several years of research have shown that machine-learning systems are vulnerable to adversarial examples, both in theory and in practice. Until now, such attacks have primarily targeted visual models, exploiting the gap between human and machine perception. Although text-based models have also been attacked with adversarial examples, such attacks struggled to preserve semantic meaning and indistinguishability. In this paper, we explore a large class of adversarial examples that can be used to attack text-based models in a black-box setting without making any human-perceptible visual modification to inputs. We use encoding-specific perturbations that are imperceptible to the human eye to manipulate the outputs of a wide range of Natural Language Processing (NLP) systems from neural machine-translation pipelines to web search engines. We find that with a single imperceptible encoding injection -- representing one invisible character, homoglyph, reordering, or deletion -- an attacker can significantly reduce the performance of vulnerable models, and with three injections most models can be functionally broken. Our attacks work against currently-deployed commercial systems, including those produced by Microsoft and Google, in addition to open source models published by Facebook and IBM. This novel series of attacks presents a significant threat to many language processing systems: an attacker can affect systems in a targeted manner without any assumptions about the underlying model. We conclude that text-based NLP systems require careful input sanitization, just like conventional applications, and that given such systems are now being deployed rapidly at scale, the urgent attention of architects and operators is required.
Markpainting: Adversarial Machine Learning meets Inpainting
Jun 01, 2021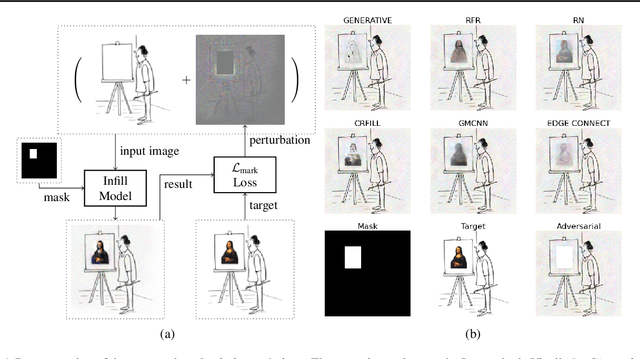
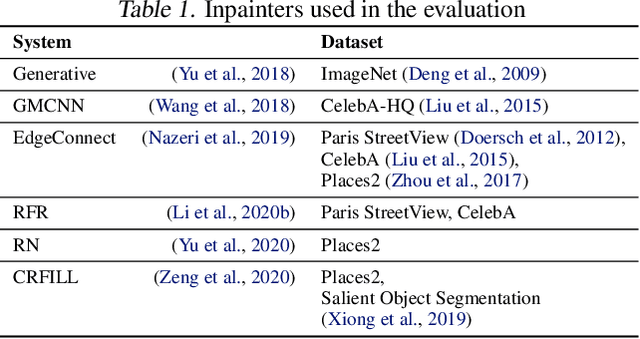

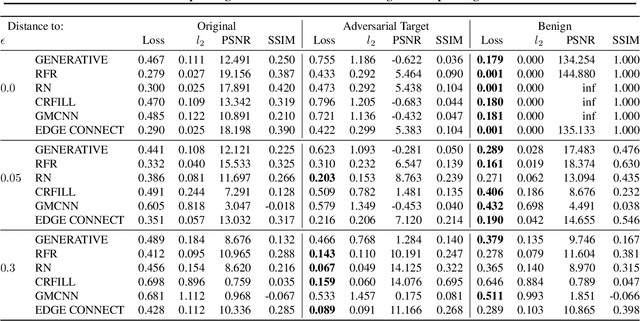
Inpainting is a learned interpolation technique that is based on generative modeling and used to populate masked or missing pieces in an image; it has wide applications in picture editing and retouching. Recently, inpainting started being used for watermark removal, raising concerns. In this paper we study how to manipulate it using our markpainting technique. First, we show how an image owner with access to an inpainting model can augment their image in such a way that any attempt to edit it using that model will add arbitrary visible information. We find that we can target multiple different models simultaneously with our technique. This can be designed to reconstitute a watermark if the editor had been trying to remove it. Second, we show that our markpainting technique is transferable to models that have different architectures or were trained on different datasets, so watermarks created using it are difficult for adversaries to remove. Markpainting is novel and can be used as a manipulation alarm that becomes visible in the event of inpainting.
Manipulating SGD with Data Ordering Attacks
Apr 19, 2021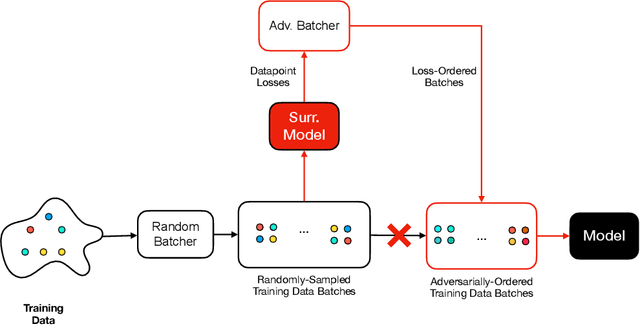
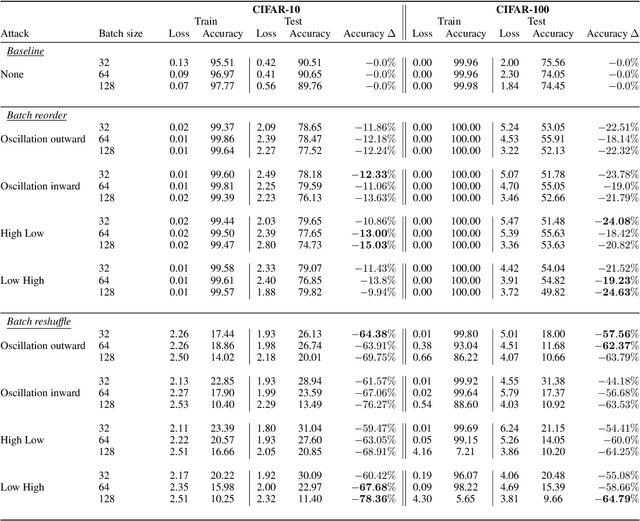
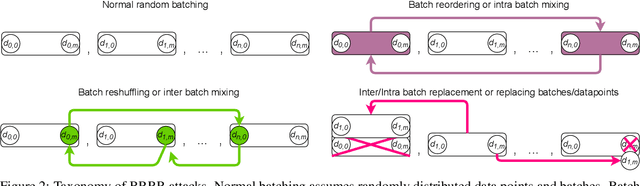
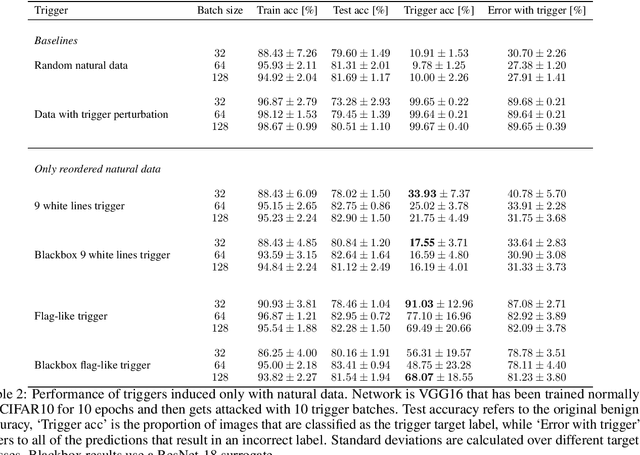
Machine learning is vulnerable to a wide variety of different attacks. It is now well understood that by changing the underlying data distribution, an adversary can poison the model trained with it or introduce backdoors. In this paper we present a novel class of training-time attacks that require no changes to the underlying model dataset or architecture, but instead only change the order in which data are supplied to the model. In particular, an attacker can disrupt the integrity and availability of a model by simply reordering training batches, with no knowledge about either the model or the dataset. Indeed, the attacks presented here are not specific to the model or dataset, but rather target the stochastic nature of modern learning procedures. We extensively evaluate our attacks to find that the adversary can disrupt model training and even introduce backdoors. For integrity we find that the attacker can either stop the model from learning, or poison it to learn behaviours specified by the attacker. For availability we find that a single adversarially-ordered epoch can be enough to slow down model learning, or even to reset all of the learning progress. Such attacks have a long-term impact in that they decrease model performance hundreds of epochs after the attack took place. Reordering is a very powerful adversarial paradigm in that it removes the assumption that an adversary must inject adversarial data points or perturbations to perform training-time attacks. It reminds us that stochastic gradient descent relies on the assumption that data are sampled at random. If this randomness is compromised, then all bets are off.
Hey Alexa what did I just type? Decoding smartphone sounds with a voice assistant
Dec 01, 2020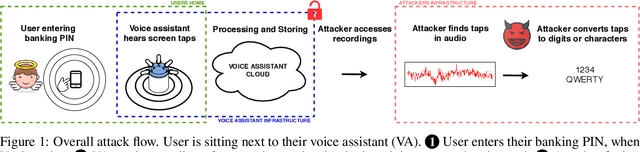


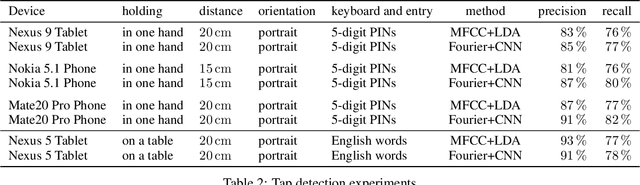
Voice assistants are now ubiquitous and listen in on our everyday lives. Ever since they became commercially available, privacy advocates worried that the data they collect can be abused: might private conversations be extracted by third parties? In this paper we show that privacy threats go beyond spoken conversations and include sensitive data typed on nearby smartphones. Using two different smartphones and a tablet we demonstrate that the attacker can extract PIN codes and text messages from recordings collected by a voice assistant located up to half a meter away. This shows that remote keyboard-inference attacks are not limited to physical keyboards but extend to virtual keyboards too. As our homes become full of always-on microphones, we need to work through the implications.