 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLithoGRPO: Fast Inverse Lithography via GRPO Reinforced Flow Matching
May 29, 2026In semiconductor manufacturing, lithography projects circuit layouts onto silicon wafers through an optical mask. As circuit features shrink below the wavelength of light, optical diffraction causes the printed patterns to deviate from their intended layouts. Inverse Lithography Technology (ILT) addresses this challenge by generating optimized masks that enhance the fidelity of pattern transfer onto wafers. While ILT resembles an image synthesis task, its reliance on explicit physical metrics for mask evaluation limits the applicability of existing generative models. We introduce LithoGRPO, an ILT framework that integrates the flow-matching paradigm with GRPO-based reinforcement learning (RL) fine-tuning, enabling efficient exploration of diverse masks for a given target layout. Unlike purely generative or optimization-based approaches, RL in LithoGRPO exploits the explicitly defined, physics-based reward function of ILT, enabling optimization under complex, process-aware constraints. To the best of our knowledge, this is the first framework that unifies flow matching and RL for mask optimization. To improve RL sampling efficiency, we propose a fast shot-counting algorithm for manufacturability evaluation, achieving over 130x speedup while preserving the mask ranking of the traditional shot-count metric. Extensive experiments demonstrate that LithoGRPO achieves state-of-the-art performance over both optimization-based and learning-based methods, while maintaining efficient mask generation.
Deep Kernel Fusion for Transformers
Feb 12, 2026Agentic LLM inference with long contexts is increasingly limited by memory bandwidth rather than compute. In this setting, SwiGLU MLP blocks, whose large weights exceed cache capacity, become a major yet under-optimized bottleneck. We propose DeepFusionKernel, a deeply fused kernel that cuts HBM traffic and boosts cache reuse, delivering up to 13.2% speedup on H100 and 9.7% on A100 over SGLang. Integrated with SGLang and paired with a kernel scheduler, DeepFusionKernel ensures consistent accelerations over generation lengths, while remaining adaptable to diverse models, inference configurations, and hardware platforms.
Beyond GEMM-Centric NPUs: Enabling Efficient Diffusion LLM Sampling
Jan 28, 2026Diffusion Large Language Models (dLLMs) introduce iterative denoising to enable parallel token generation, but their sampling phase displays fundamentally different characteristics compared to GEMM-centric transformer layers. Profiling on modern GPUs reveals that sampling can account for up to 70% of total model inference latency-primarily due to substantial memory loads and writes from vocabulary-wide logits, reduction-based token selection, and iterative masked updates. These processes demand large on-chip SRAM and involve irregular memory accesses that conventional NPUs struggle to handle efficiently. To address this, we identify a set of critical instructions that an NPU architecture must specifically optimize for dLLM sampling. Our design employs lightweight non-GEMM vector primitives, in-place memory reuse strategies, and a decoupled mixed-precision memory hierarchy. Together, these optimizations deliver up to a 2.53x speedup over the NVIDIA RTX A6000 GPU under an equivalent nm technology node. We also open-source our cycle-accurate simulation and post-synthesis RTL verification code, confirming functional equivalence with current dLLM PyTorch implementations.
CaMeLs Can Use Computers Too: System-level Security for Computer Use Agents
Jan 14, 2026AI agents are vulnerable to prompt injection attacks, where malicious content hijacks agent behavior to steal credentials or cause financial loss. The only known robust defense is architectural isolation that strictly separates trusted task planning from untrusted environment observations. However, applying this design to Computer Use Agents (CUAs) -- systems that automate tasks by viewing screens and executing actions -- presents a fundamental challenge: current agents require continuous observation of UI state to determine each action, conflicting with the isolation required for security. We resolve this tension by demonstrating that UI workflows, while dynamic, are structurally predictable. We introduce Single-Shot Planning for CUAs, where a trusted planner generates a complete execution graph with conditional branches before any observation of potentially malicious content, providing provable control flow integrity guarantees against arbitrary instruction injections. Although this architectural isolation successfully prevents instruction injections, we show that additional measures are needed to prevent Branch Steering attacks, which manipulate UI elements to trigger unintended valid paths within the plan. We evaluate our design on OSWorld, and retain up to 57% of the performance of frontier models while improving performance for smaller open-source models by up to 19%, demonstrating that rigorous security and utility can coexist in CUAs.
ASPO: Constraint-Aware Bayesian Optimization for FPGA-based Soft Processors
Jun 07, 2025Bayesian Optimization (BO) has shown promise in tuning processor design parameters. However, standard BO does not support constraints involving categorical parameters such as types of branch predictors and division circuits. In addition, optimization time of BO grows with processor complexity, which becomes increasingly significant especially for FPGA-based soft processors. This paper introduces ASPO, an approach that leverages disjunctive form to enable BO to handle constraints involving categorical parameters. Unlike existing methods that directly apply standard BO, the proposed ASPO method, for the first time, customizes the mathematical mechanism of BO to address challenges faced by soft-processor designs on FPGAs. Specifically, ASPO supports categorical parameters using a novel customized BO covariance kernel. It also accelerates the design evaluation procedure by penalizing the BO acquisition function with potential evaluation time and by reusing FPGA synthesis checkpoints from previously evaluated configurations. ASPO targets three soft processors: RocketChip, BOOM, and EL2 VeeR. The approach is evaluated based on seven RISC-V benchmarks. Results show that ASPO can reduce execution time for the ``multiply'' benchmark on the BOOM processor by up to 35\% compared to the default configuration. Furthermore, it reduces design time for the BOOM processor by up to 74\% compared to Boomerang, a state-of-the-art hardware-oriented BO approach.
* Accepted to International Conference on Field-Programmable Logic and Applications (FPL) 2025
Adversarial Suffix Filtering: a Defense Pipeline for LLMs
May 14, 2025Large Language Models (LLMs) are increasingly embedded in autonomous systems and public-facing environments, yet they remain susceptible to jailbreak vulnerabilities that may undermine their security and trustworthiness. Adversarial suffixes are considered to be the current state-of-the-art jailbreak, consistently outperforming simpler methods and frequently succeeding even in black-box settings. Existing defenses rely on access to the internal architecture of models limiting diverse deployment, increase memory and computation footprints dramatically, or can be bypassed with simple prompt engineering methods. We introduce $\textbf{Adversarial Suffix Filtering}$ (ASF), a lightweight novel model-agnostic defensive pipeline designed to protect LLMs against adversarial suffix attacks. ASF functions as an input preprocessor and sanitizer that detects and filters adversarially crafted suffixes in prompts, effectively neutralizing malicious injections. We demonstrate that ASF provides comprehensive defense capabilities across both black-box and white-box attack settings, reducing the attack efficacy of state-of-the-art adversarial suffix generation methods to below 4%, while only minimally affecting the target model's capabilities in non-adversarial scenarios.
Watermarking Needs Input Repetition Masking
Apr 16, 2025

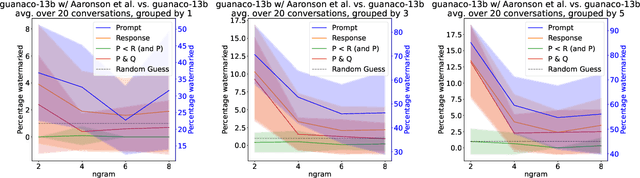

Recent advancements in Large Language Models (LLMs) raised concerns over potential misuse, such as for spreading misinformation. In response two counter measures emerged: machine learning-based detectors that predict if text is synthetic, and LLM watermarking, which subtly marks generated text for identification and attribution. Meanwhile, humans are known to adjust language to their conversational partners both syntactically and lexically. By implication, it is possible that humans or unwatermarked LLMs could unintentionally mimic properties of LLM generated text, making counter measures unreliable. In this work we investigate the extent to which such conversational adaptation happens. We call the concept $\textit{mimicry}$ and demonstrate that both humans and LLMs end up mimicking, including the watermarking signal even in seemingly improbable settings. This challenges current academic assumptions and suggests that for long-term watermarking to be reliable, the likelihood of false positives needs to be significantly lower, while longer word sequences should be used for seeding watermarking mechanisms.
"I am bad": Interpreting Stealthy, Universal and Robust Audio Jailbreaks in Audio-Language Models
Feb 02, 2025



The rise of multimodal large language models has introduced innovative human-machine interaction paradigms but also significant challenges in machine learning safety. Audio-Language Models (ALMs) are especially relevant due to the intuitive nature of spoken communication, yet little is known about their failure modes. This paper explores audio jailbreaks targeting ALMs, focusing on their ability to bypass alignment mechanisms. We construct adversarial perturbations that generalize across prompts, tasks, and even base audio samples, demonstrating the first universal jailbreaks in the audio modality, and show that these remain effective in simulated real-world conditions. Beyond demonstrating attack feasibility, we analyze how ALMs interpret these audio adversarial examples and reveal them to encode imperceptible first-person toxic speech - suggesting that the most effective perturbations for eliciting toxic outputs specifically embed linguistic features within the audio signal. These results have important implications for understanding the interactions between different modalities in multimodal models, and offer actionable insights for enhancing defenses against adversarial audio attacks.
Complexity Matters: Effective Dimensionality as a Measure for Adversarial Robustness
Oct 24, 2024Quantifying robustness in a single measure for the purposes of model selection, development of adversarial training methods, and anticipating trends has so far been elusive. The simplest metric to consider is the number of trainable parameters in a model but this has previously been shown to be insufficient at explaining robustness properties. A variety of other metrics, such as ones based on boundary thickness and gradient flatness have been proposed but have been shown to be inadequate proxies for robustness. In this work, we investigate the relationship between a model's effective dimensionality, which can be thought of as model complexity, and its robustness properties. We run experiments on commercial-scale models that are often used in real-world environments such as YOLO and ResNet. We reveal a near-linear inverse relationship between effective dimensionality and adversarial robustness, that is models with a lower dimensionality exhibit better robustness. We investigate the effect of a variety of adversarial training methods on effective dimensionality and find the same inverse linear relationship present, suggesting that effective dimensionality can serve as a useful criterion for model selection and robustness evaluation, providing a more nuanced and effective metric than parameter count or previously-tested measures.
Beyond Slow Signs in High-fidelity Model Extraction
Jun 14, 2024Deep neural networks, costly to train and rich in intellectual property value, are increasingly threatened by model extraction attacks that compromise their confidentiality. Previous attacks have succeeded in reverse-engineering model parameters up to a precision of float64 for models trained on random data with at most three hidden layers using cryptanalytical techniques. However, the process was identified to be very time consuming and not feasible for larger and deeper models trained on standard benchmarks. Our study evaluates the feasibility of parameter extraction methods of Carlini et al. [1] further enhanced by Canales-Mart\'inez et al. [2] for models trained on standard benchmarks. We introduce a unified codebase that integrates previous methods and reveal that computational tools can significantly influence performance. We develop further optimisations to the end-to-end attack and improve the efficiency of extracting weight signs by up to 14.8 times compared to former methods through the identification of easier and harder to extract neurons. Contrary to prior assumptions, we identify extraction of weights, not extraction of weight signs, as the critical bottleneck. With our improvements, a 16,721 parameter model with 2 hidden layers trained on MNIST is extracted within only 98 minutes compared to at least 150 minutes previously. Finally, addressing methodological deficiencies observed in previous studies, we propose new ways of robust benchmarking for future model extraction attacks.