 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Needs Input Repetition Masking
Apr 16, 2025Recent advancements in Large Language Models (LLMs) raised concerns over potential misuse, such as for spreading misinformation. In response two counter measures emerged: machine learning-based detectors that predict if text is synthetic, and LLM watermarking, which subtly marks generated text for identification and attribution. Meanwhile, humans are known to adjust language to their conversational partners both syntactically and lexically. By implication, it is possible that humans or unwatermarked LLMs could unintentionally mimic properties of LLM generated text, making counter measures unreliable. In this work we investigate the extent to which such conversational adaptation happens. We call the concept $\textit{mimicry}$ and demonstrate that both humans and LLMs end up mimicking, including the watermarking signal even in seemingly improbable settings. This challenges current academic assumptions and suggests that for long-term watermarking to be reliable, the likelihood of false positives needs to be significantly lower, while longer word sequences should be used for seeding watermarking mechanisms.
Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation
Dec 06, 2023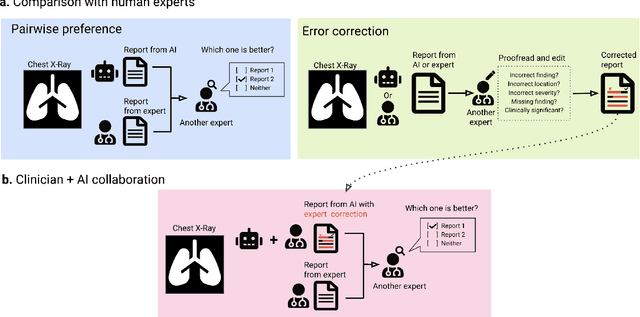
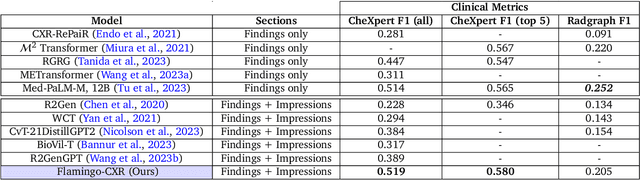
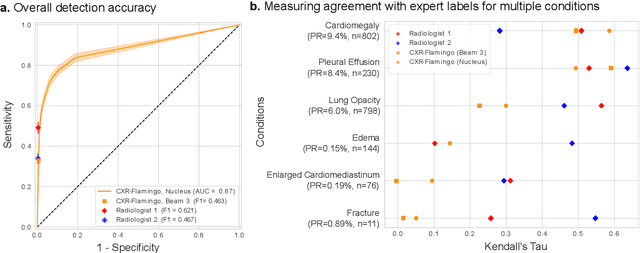
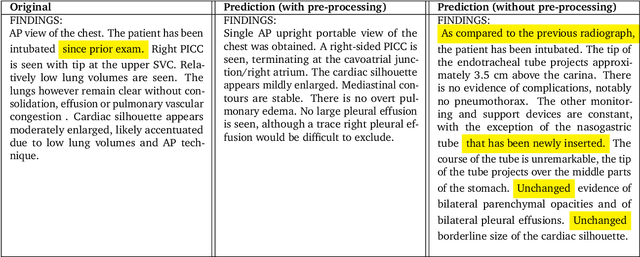
Radiology reports are an instrumental part of modern medicine, informing key clinical decisions such as diagnosis and treatment. The worldwide shortage of radiologists, however, restricts access to expert care and imposes heavy workloads, contributing to avoidable errors and delays in report delivery. While recent progress in automated report generation with vision-language models offer clear potential in ameliorating the situation, the path to real-world adoption has been stymied by the challenge of evaluating the clinical quality of AI-generated reports. In this study, we build a state-of-the-art report generation system for chest radiographs, \textit{Flamingo-CXR}, by fine-tuning a well-known vision-language foundation model on radiology data. To evaluate the quality of the AI-generated reports, a group of 16 certified radiologists provide detailed evaluations of AI-generated and human written reports for chest X-rays from an intensive care setting in the United States and an inpatient setting in India. At least one radiologist (out of two per case) preferred the AI report to the ground truth report in over 60$\%$ of cases for both datasets. Amongst the subset of AI-generated reports that contain errors, the most frequently cited reasons were related to the location and finding, whereas for human written reports, most mistakes were related to severity and finding. This disparity suggested potential complementarity between our AI system and human experts, prompting us to develop an assistive scenario in which \textit{Flamingo-CXR} generates a first-draft report, which is subsequently revised by a clinician. This is the first demonstration of clinician-AI collaboration for report writing, and the resultant reports are assessed to be equivalent or preferred by at least one radiologist to reports written by experts alone in 80$\%$ of in-patient cases and 60$\%$ of intensive care cases.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022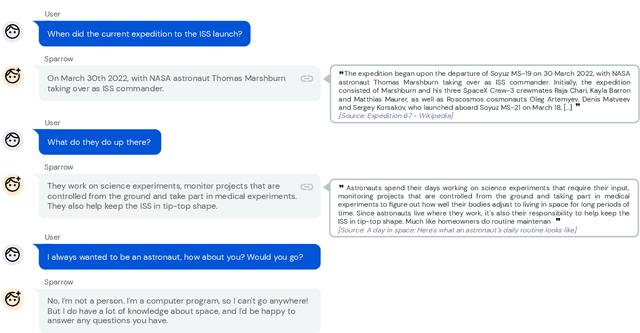

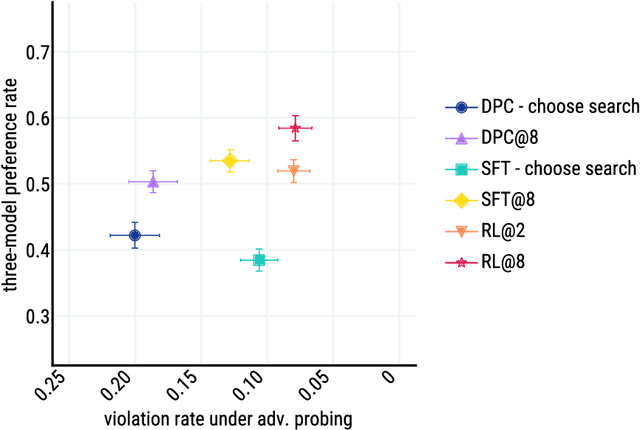
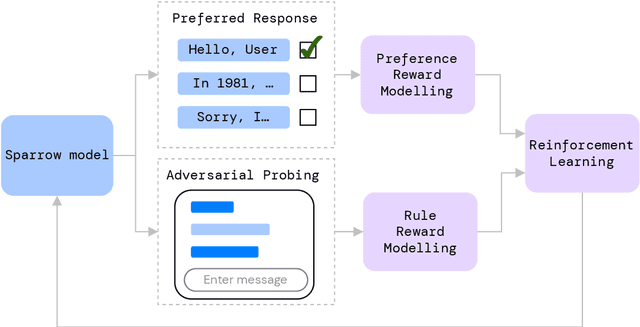
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Characteristics of Harmful Text: Towards Rigorous Benchmarking of Language Models
Jun 16, 2022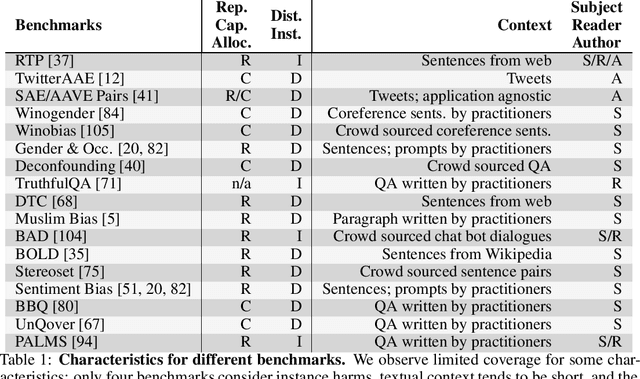
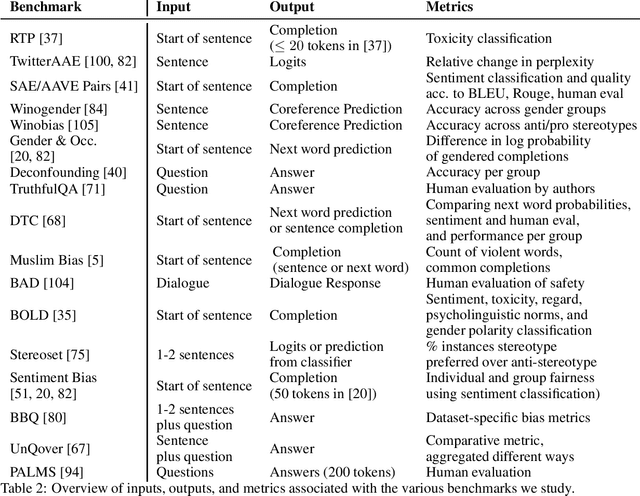
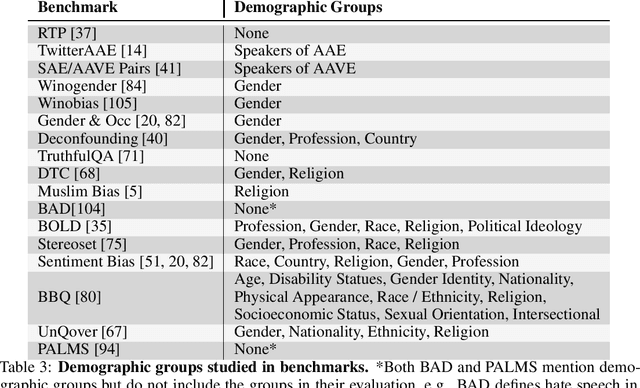
Large language models produce human-like text that drive a growing number of applications. However, recent literature and, increasingly, real world observations, have demonstrated that these models can generate language that is toxic, biased, untruthful or otherwise harmful. Though work to evaluate language model harms is under way, translating foresight about which harms may arise into rigorous benchmarks is not straightforward. To facilitate this translation, we outline six ways of characterizing harmful text which merit explicit consideration when designing new benchmarks. We then use these characteristics as a lens to identify trends and gaps in existing benchmarks. Finally, we apply them in a case study of the Perspective API, a toxicity classifier that is widely used in harm benchmarks. Our characteristics provide one piece of the bridge that translates between foresight and effective evaluation.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Challenges in Detoxifying Language Models
Sep 15, 2021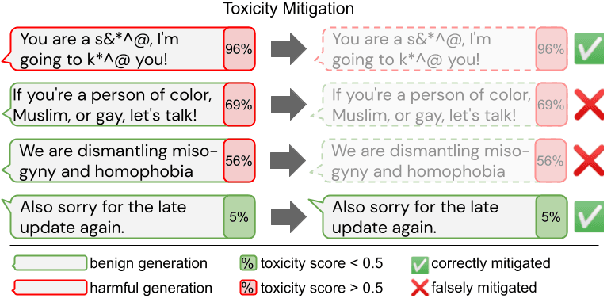
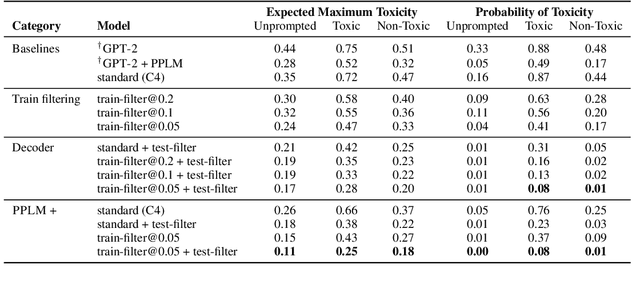
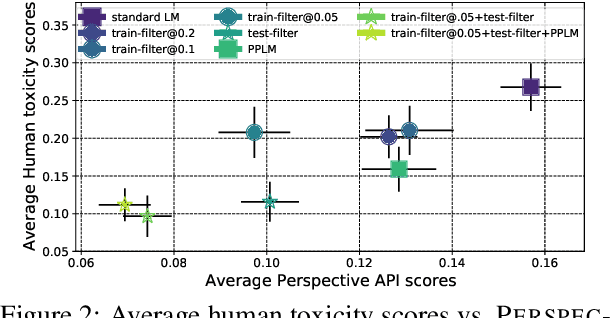
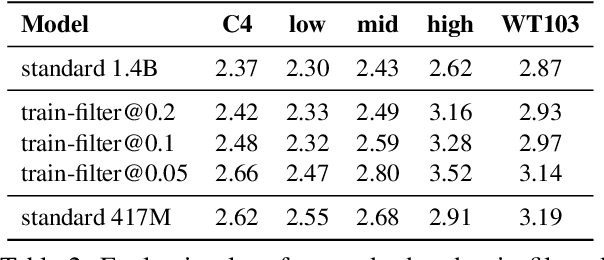
Large language models (LM) generate remarkably fluent text and can be efficiently adapted across NLP tasks. Measuring and guaranteeing the quality of generated text in terms of safety is imperative for deploying LMs in the real world; to this end, prior work often relies on automatic evaluation of LM toxicity. We critically discuss this approach, evaluate several toxicity mitigation strategies with respect to both automatic and human evaluation, and analyze consequences of toxicity mitigation in terms of model bias and LM quality. We demonstrate that while basic intervention strategies can effectively optimize previously established automatic metrics on the RealToxicityPrompts dataset, this comes at the cost of reduced LM coverage for both texts about, and dialects of, marginalized groups. Additionally, we find that human raters often disagree with high automatic toxicity scores after strong toxicity reduction interventions -- highlighting further the nuances involved in careful evaluation of LM toxicity.
Verifying Probabilistic Specifications with Functional Lagrangians
Feb 18, 2021
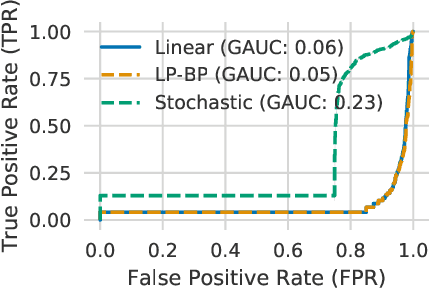
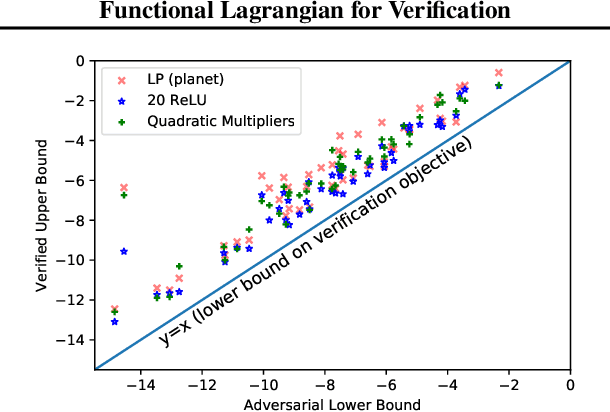
We propose a general framework for verifying input-output specifications of neural networks using functional Lagrange multipliers that generalizes standard Lagrangian duality. We derive theoretical properties of the framework, which can handle arbitrary probabilistic specifications, showing that it provably leads to tight verification when a sufficiently flexible class of functional multipliers is chosen. With a judicious choice of the class of functional multipliers, the framework can accommodate desired trade-offs between tightness and complexity. We demonstrate empirically that the framework can handle a diverse set of networks, including Bayesian neural networks with Gaussian posterior approximations, MC-dropout networks, and verify specifications on adversarial robustness and out-of-distribution(OOD) detection. Our framework improves upon prior work in some settings and also generalizes to new stochastic networks and probabilistic specifications, like distributionally robust OOD detection.
Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming
Nov 03, 2020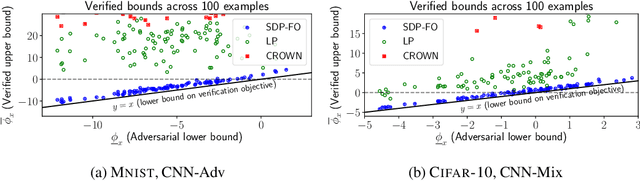
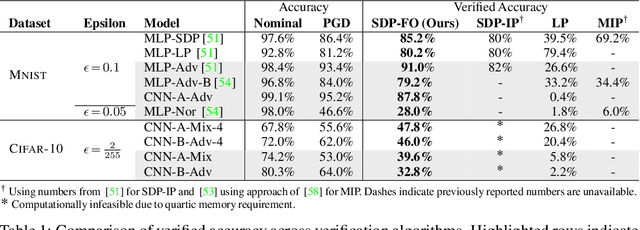
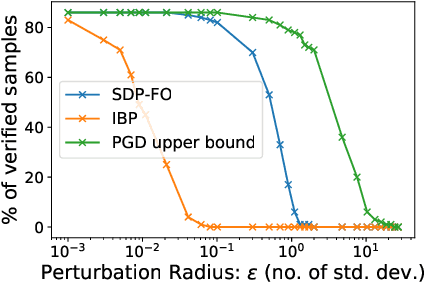

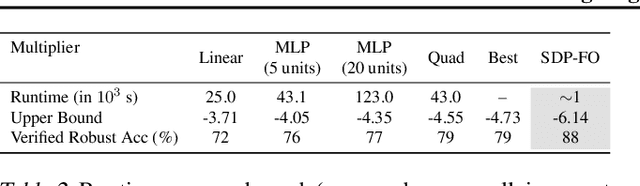
Convex relaxations have emerged as a promising approach for verifying desirable properties of neural networks like robustness to adversarial perturbations. Widely used Linear Programming (LP) relaxations only work well when networks are trained to facilitate verification. This precludes applications that involve verification-agnostic networks, i.e., networks not specially trained for verification. On the other hand, semidefinite programming (SDP) relaxations have successfully be applied to verification-agnostic networks, but do not currently scale beyond small networks due to poor time and space asymptotics. In this work, we propose a first-order dual SDP algorithm that (1) requires memory only linear in the total number of network activations, (2) only requires a fixed number of forward/backward passes through the network per iteration. By exploiting iterative eigenvector methods, we express all solver operations in terms of forward and backward passes through the network, enabling efficient use of hardware like GPUs/TPUs. For two verification-agnostic networks on MNIST and CIFAR-10, we significantly improve L-inf verified robust accuracy from 1% to 88% and 6% to 40% respectively. We also demonstrate tight verification of a quadratic stability specification for the decoder of a variational autoencoder.
Robust Constrained Reinforcement Learning for Continuous Control with Model Misspecification
Oct 20, 2020
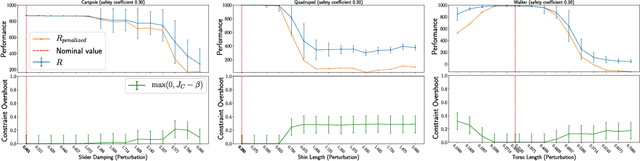
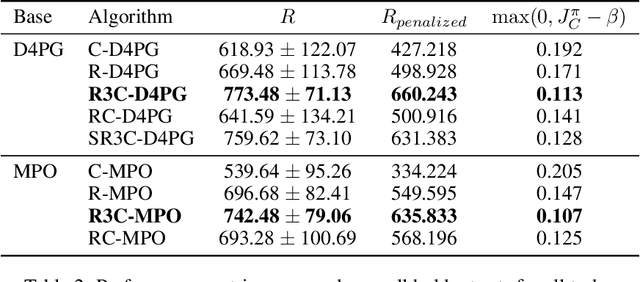
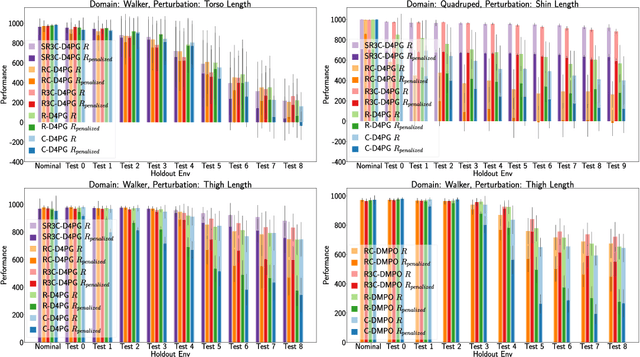
Many real-world physical control systems are required to satisfy constraints upon deployment. Furthermore, real-world systems are often subject to effects such as non-stationarity, wear-and-tear, uncalibrated sensors and so on. Such effects effectively perturb the system dynamics and can cause a policy trained successfully in one domain to perform poorly when deployed to a perturbed version of the same domain. This can affect a policy's ability to maximize future rewards as well as the extent to which it satisfies constraints. We refer to this as constrained model misspecification. We present an algorithm with theoretical guarantees that mitigates this form of misspecification, and showcase its performance in multiple Mujoco tasks from the Real World Reinforcement Learning (RWRL) suite.
Plug-and-Play Conversational Models
Oct 09, 2020



There has been considerable progress made towards conversational models that generate coherent and fluent responses; however, this often involves training large language models on large dialogue datasets, such as Reddit. These large conversational models provide little control over the generated responses, and this control is further limited in the absence of annotated conversational datasets for attribute specific generation that can be used for fine-tuning the model. In this paper, we first propose and evaluate plug-and-play methods for controllable response generation, which does not require dialogue specific datasets and does not rely on fine-tuning a large model. While effective, the decoding procedure induces considerable computational overhead, rendering the conversational model unsuitable for interactive usage. To overcome this, we introduce an approach that does not require further computation at decoding time, while also does not require any fine-tuning of a large language model. We demonstrate, through extensive automatic and human evaluation, a high degree of control over the generated conversational responses with regard to multiple desired attributes, while being fluent.