 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical discrimination in learning agents
Oct 21, 2021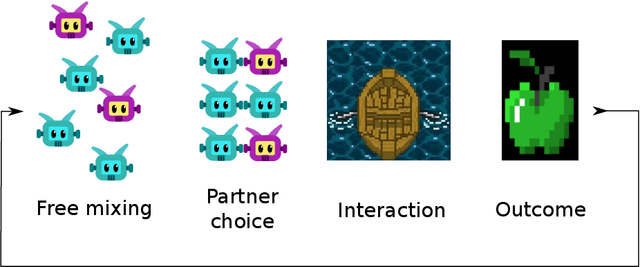
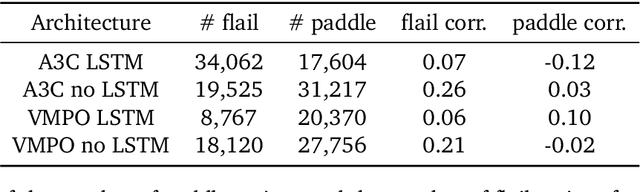
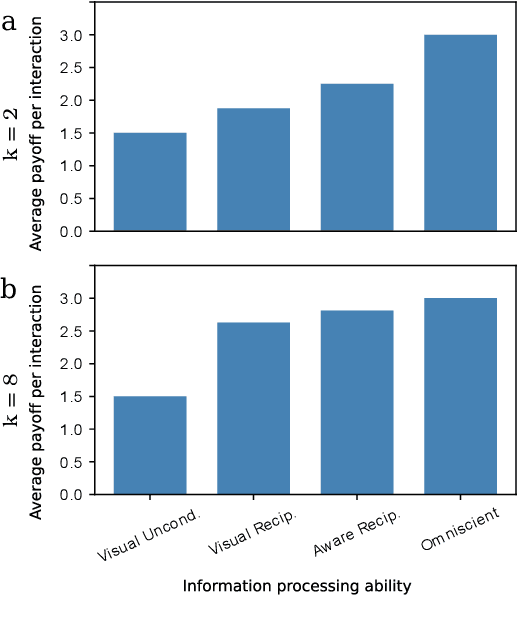
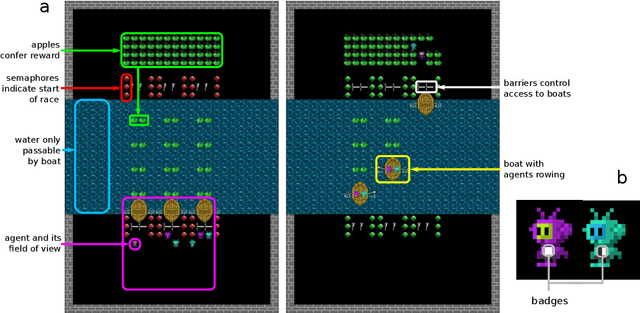
Undesired bias afflicts both human and algorithmic decision making, and may be especially prevalent when information processing trade-offs incentivize the use of heuristics. One primary example is \textit{statistical discrimination} -- selecting social partners based not on their underlying attributes, but on readily perceptible characteristics that covary with their suitability for the task at hand. We present a theoretical model to examine how information processing influences statistical discrimination and test its predictions using multi-agent reinforcement learning with various agent architectures in a partner choice-based social dilemma. As predicted, statistical discrimination emerges in agent policies as a function of both the bias in the training population and of agent architecture. All agents showed substantial statistical discrimination, defaulting to using the readily available correlates instead of the outcome relevant features. We show that less discrimination emerges with agents that use recurrent neural networks, and when their training environment has less bias. However, all agent algorithms we tried still exhibited substantial bias after learning in biased training populations.
Challenges in Detoxifying Language Models
Sep 15, 2021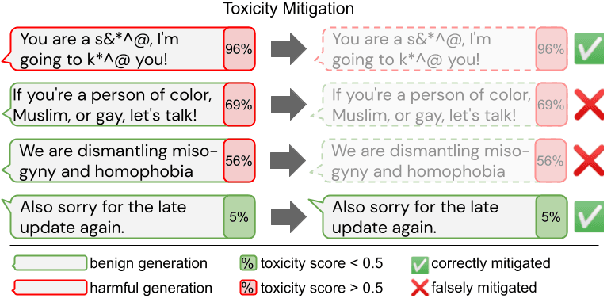
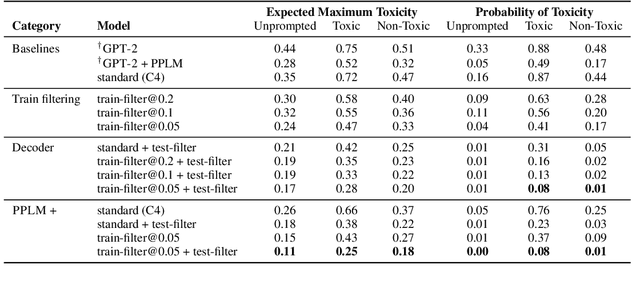
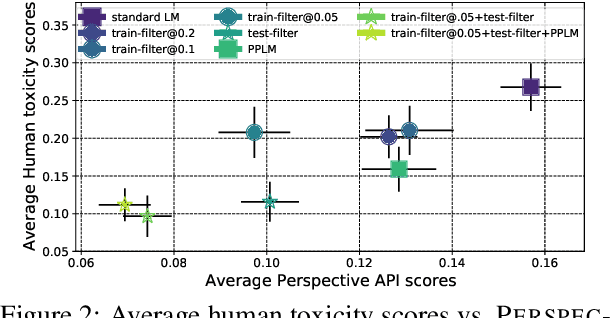
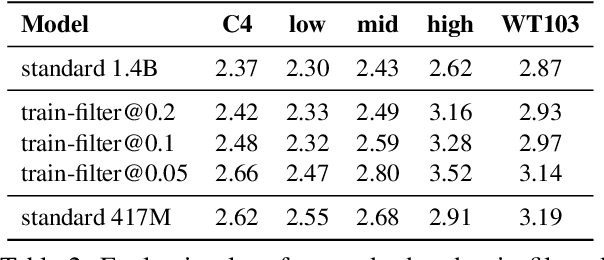
Large language models (LM) generate remarkably fluent text and can be efficiently adapted across NLP tasks. Measuring and guaranteeing the quality of generated text in terms of safety is imperative for deploying LMs in the real world; to this end, prior work often relies on automatic evaluation of LM toxicity. We critically discuss this approach, evaluate several toxicity mitigation strategies with respect to both automatic and human evaluation, and analyze consequences of toxicity mitigation in terms of model bias and LM quality. We demonstrate that while basic intervention strategies can effectively optimize previously established automatic metrics on the RealToxicityPrompts dataset, this comes at the cost of reduced LM coverage for both texts about, and dialects of, marginalized groups. Additionally, we find that human raters often disagree with high automatic toxicity scores after strong toxicity reduction interventions -- highlighting further the nuances involved in careful evaluation of LM toxicity.
Large-Scale Visual Speech Recognition
Oct 01, 2018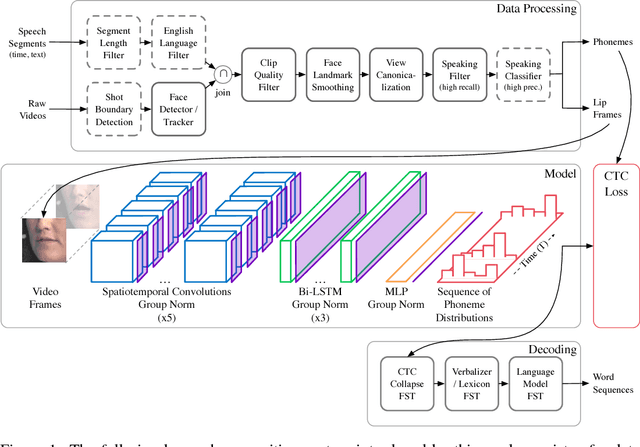
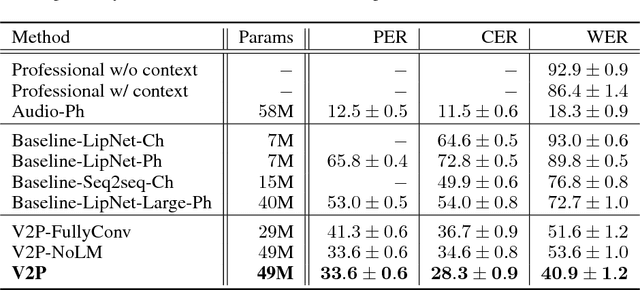


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Deep Reinforcement Learning in Large Discrete Action Spaces
Apr 04, 2016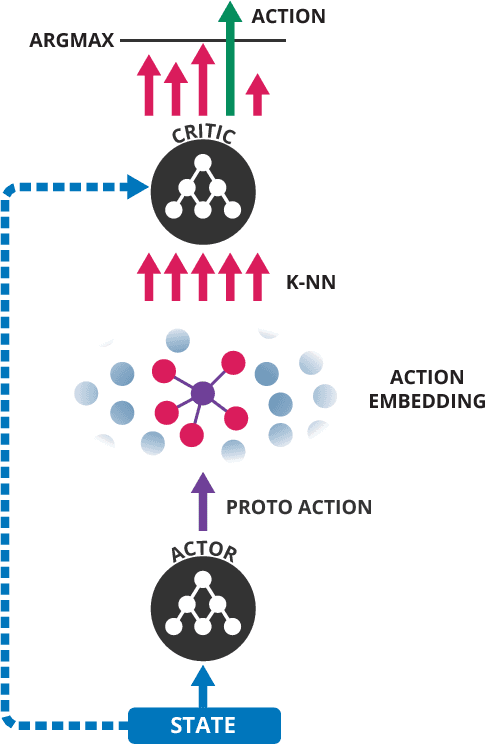

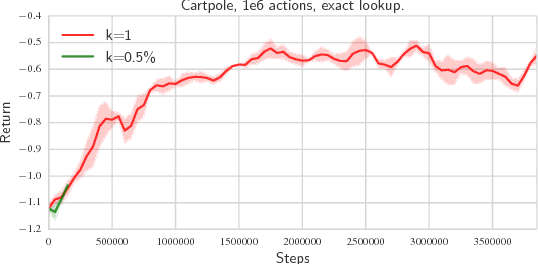
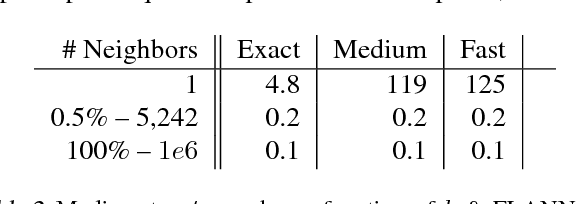
Being able to reason in an environment with a large number of discrete actions is essential to bringing reinforcement learning to a larger class of problems. Recommender systems, industrial plants and language models are only some of the many real-world tasks involving large numbers of discrete actions for which current methods are difficult or even often impossible to apply. An ability to generalize over the set of actions as well as sub-linear complexity relative to the size of the set are both necessary to handle such tasks. Current approaches are not able to provide both of these, which motivates the work in this paper. Our proposed approach leverages prior information about the actions to embed them in a continuous space upon which it can generalize. Additionally, approximate nearest-neighbor methods allow for logarithmic-time lookup complexity relative to the number of actions, which is necessary for time-wise tractable training. This combined approach allows reinforcement learning methods to be applied to large-scale learning problems previously intractable with current methods. We demonstrate our algorithm's abilities on a series of tasks having up to one million actions.
Deep Reinforcement Learning with Attention for Slate Markov Decision Processes with High-Dimensional States and Actions
Dec 16, 2015



Many real-world problems come with action spaces represented as feature vectors. Although high-dimensional control is a largely unsolved problem, there has recently been progress for modest dimensionalities. Here we report on a successful attempt at addressing problems of dimensionality as high as $2000$, of a particular form. Motivated by important applications such as recommendation systems that do not fit the standard reinforcement learning frameworks, we introduce Slate Markov Decision Processes (slate-MDPs). A Slate-MDP is an MDP with a combinatorial action space consisting of slates (tuples) of primitive actions of which one is executed in an underlying MDP. The agent does not control the choice of this executed action and the action might not even be from the slate, e.g., for recommendation systems for which all recommendations can be ignored. We use deep Q-learning based on feature representations of both the state and action to learn the value of whole slates. Unlike existing methods, we optimize for both the combinatorial and sequential aspects of our tasks. The new agent's superiority over agents that either ignore the combinatorial or sequential long-term value aspect is demonstrated on a range of environments with dynamics from a real-world recommendation system. Further, we use deep deterministic policy gradients to learn a policy that for each position of the slate, guides attention towards the part of the action space in which the value is the highest and we only evaluate actions in this area. The attention is used within a sequentially greedy procedure leveraging submodularity. Finally, we show how introducing risk-seeking can dramatically improve the agents performance and ability to discover more far reaching strategies.