 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Writing Screenplays and Theatre Scripts with Language Models: An Evaluation by Industry Professionals
Sep 29, 2022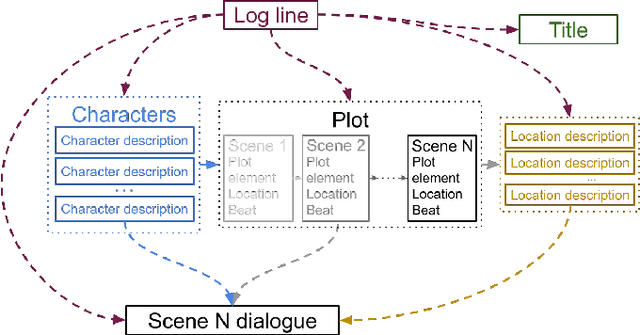

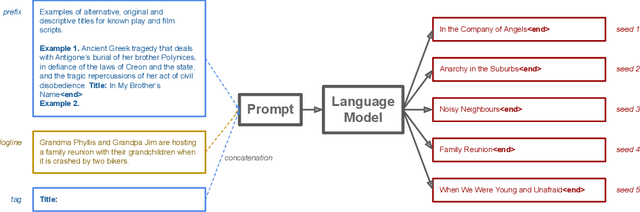
Language models are increasingly attracting interest from writers. However, such models lack long-range semantic coherence, limiting their usefulness for longform creative writing. We address this limitation by applying language models hierarchically, in a system we call Dramatron. By building structural context via prompt chaining, Dramatron can generate coherent scripts and screenplays complete with title, characters, story beats, location descriptions, and dialogue. We illustrate Dramatron's usefulness as an interactive co-creative system with a user study of 15 theatre and film industry professionals. Participants co-wrote theatre scripts and screenplays with Dramatron and engaged in open-ended interviews. We report critical reflections both from our interviewees and from independent reviewers who watched stagings of the works to illustrate how both Dramatron and hierarchical text generation could be useful for human-machine co-creativity. Finally, we discuss the suitability of Dramatron for co-creativity, ethical considerations -- including plagiarism and bias -- and participatory models for the design and deployment of such tools.
Confusion Matrices and Accuracy Statistics for Binary Classifiers Using Unlabeled Data: The Diagnostic Test Approach
Aug 26, 2022Medical researchers have solved the problem of estimating the sensitivity and specificity of binary medical diagnostic tests without gold standard tests for comparison. That problem is the same as estimating confusion matrices for classifiers on unlabeled data. This article describes how to modify the diagnostic test solutions to estimate confusion matrices and accuracy statistics for supervised or unsupervised binary classifiers on unlabeled data.
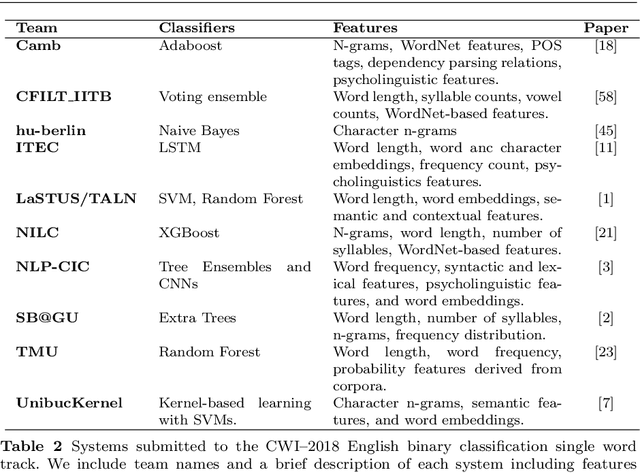
SemEval-2021 Task 1: Lexical Complexity Prediction
Jun 01, 2021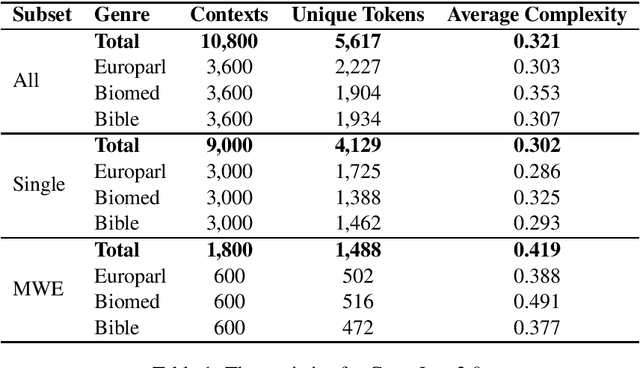
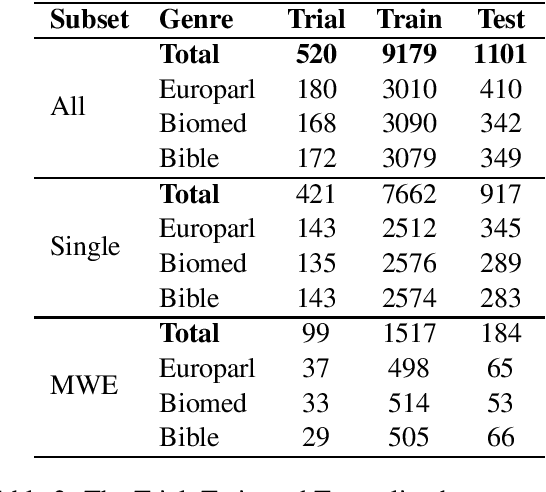
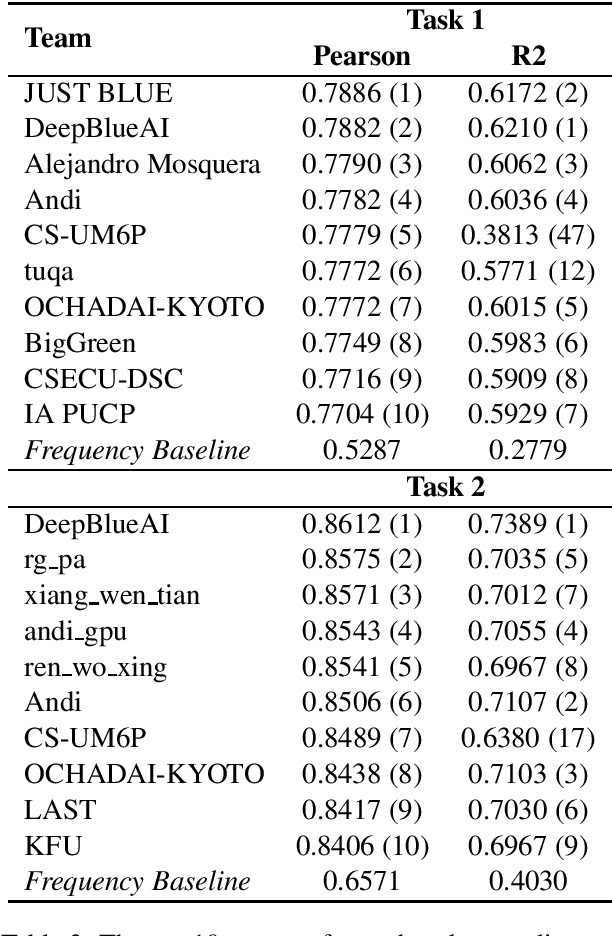
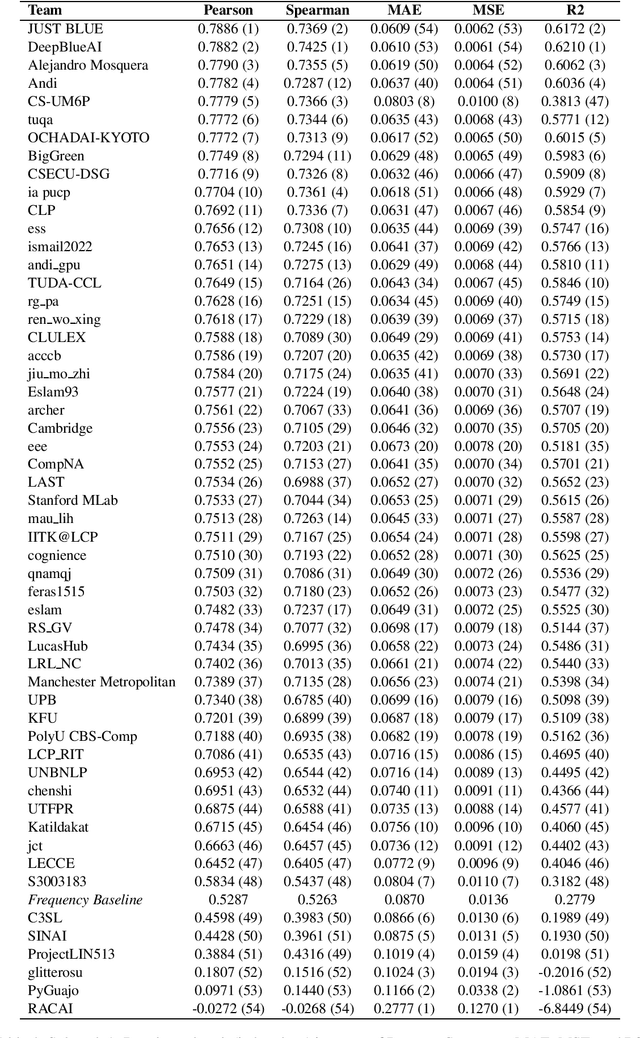
This paper presents the results and main findings of SemEval-2021 Task 1 - Lexical Complexity Prediction. We provided participants with an augmented version of the CompLex Corpus (Shardlow et al 2020). CompLex is an English multi-domain corpus in which words and multi-word expressions (MWEs) were annotated with respect to their complexity using a five point Likert scale. SemEval-2021 Task 1 featured two Sub-tasks: Sub-task 1 focused on single words and Sub-task 2 focused on MWEs. The competition attracted 198 teams in total, of which 54 teams submitted official runs on the test data to Sub-task 1 and 37 to Sub-task 2.
Inductive logic programming at 30
Feb 21, 2021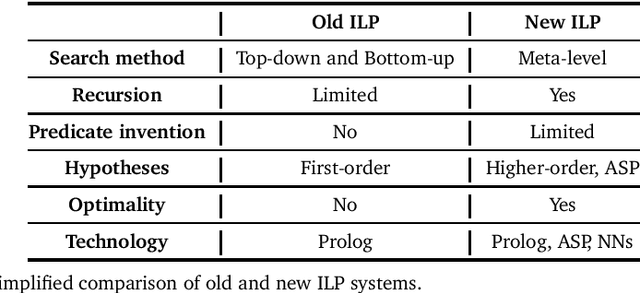
Inductive logic programming (ILP) is a form of logic-based machine learning. The goal of ILP is to induce a hypothesis (a logic program) that generalises given training examples and background knowledge. As ILP turns 30, we survey recent work in the field. In this survey, we focus on (i) new meta-level search methods, (ii) techniques for learning recursive programs that generalise from few examples, (iii) new approaches for predicate invention, and (iv) the use of different technologies, notably answer set programming and neural networks. We conclude by discussing some of the current limitations of ILP and discuss directions for future research.
Predicting Lexical Complexity in English Texts
Feb 17, 2021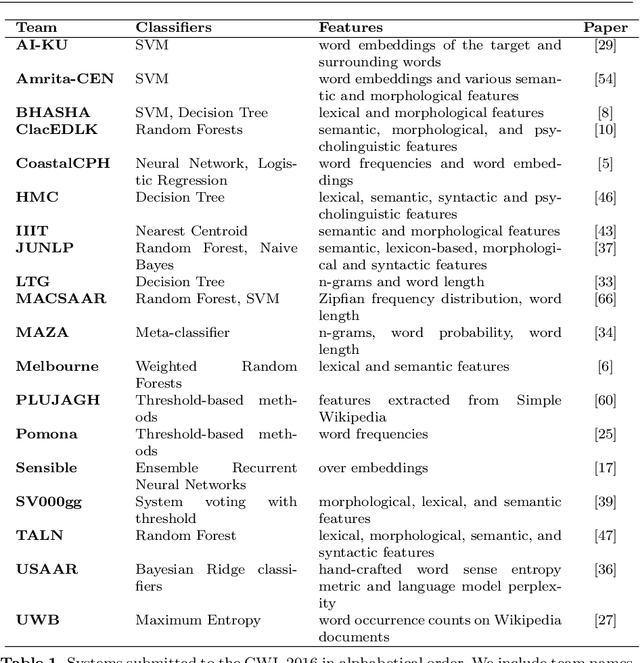
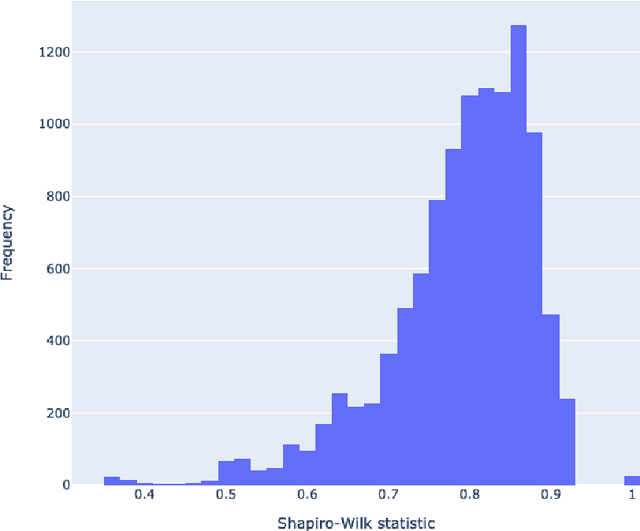
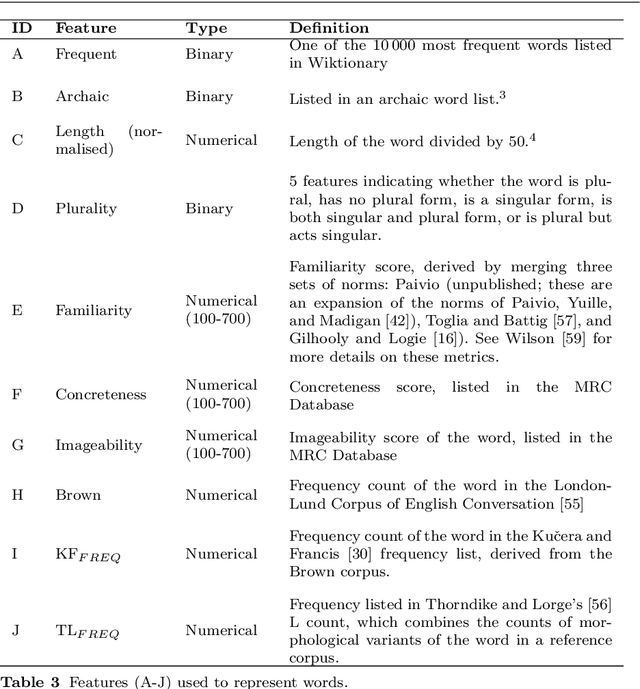
The first step in most text simplification is to predict which words are considered complex for a given target population before carrying out lexical substitution. This task is commonly referred to as Complex Word Identification (CWI) and it is often modelled as a supervised classification problem. For training such systems, annotated datasets in which words and sometimes multi-word expressions are labelled regarding complexity are required. In this paper we analyze previous work carried out in this task and investigate the properties of complex word identification datasets for English.
Evaluating the Apperception Engine
Jul 09, 2020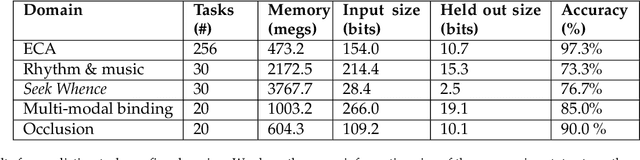

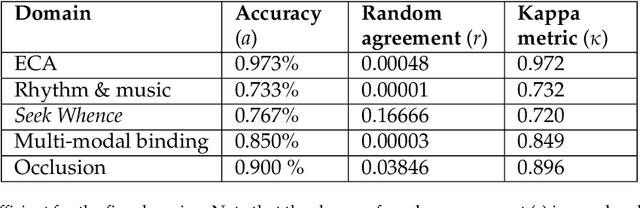

The Apperception Engine is an unsupervised learning system. Given a sequence of sensory inputs, it constructs a symbolic causal theory that both explains the sensory sequence and also satisfies a set of unity conditions. The unity conditions insist that the constituents of the theory - objects, properties, and laws - must be integrated into a coherent whole. Once a theory has been constructed, it can be applied to predict future sensor readings, retrodict earlier readings, or impute missing readings. In this paper, we evaluate the Apperception Engine in a diverse variety of domains, including cellular automata, rhythms and simple nursery tunes, multi-modal binding problems, occlusion tasks, and sequence induction intelligence tests. In each domain, we test our engine's ability to predict future sensor values, retrodict earlier sensor values, and impute missing sensory data. The engine performs well in all these domains, significantly outperforming neural net baselines and state of the art inductive logic programming systems. These results are significant because neural nets typically struggle to solve the binding problem (where information from different modalities must somehow be combined together into different aspects of one unified object) and fail to solve occlusion tasks (in which objects are sometimes visible and sometimes obscured from view). We note in particular that in the sequence induction intelligence tests, our system achieved human-level performance. This is notable because our system is not a bespoke system designed specifically to solve intelligence tests, but a general-purpose system that was designed to make sense of any sensory sequence.
Classifying Referential and Non-referential It Using Gaze
Jun 23, 2020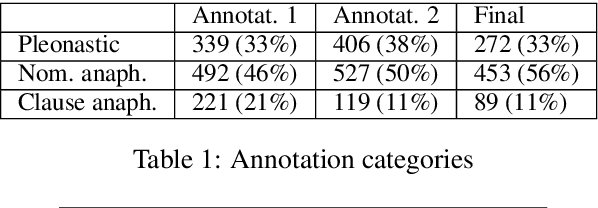
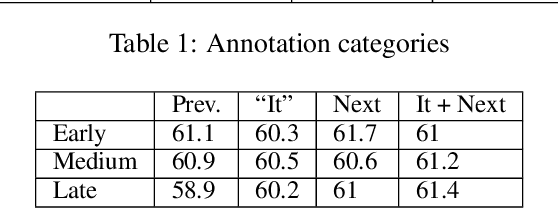
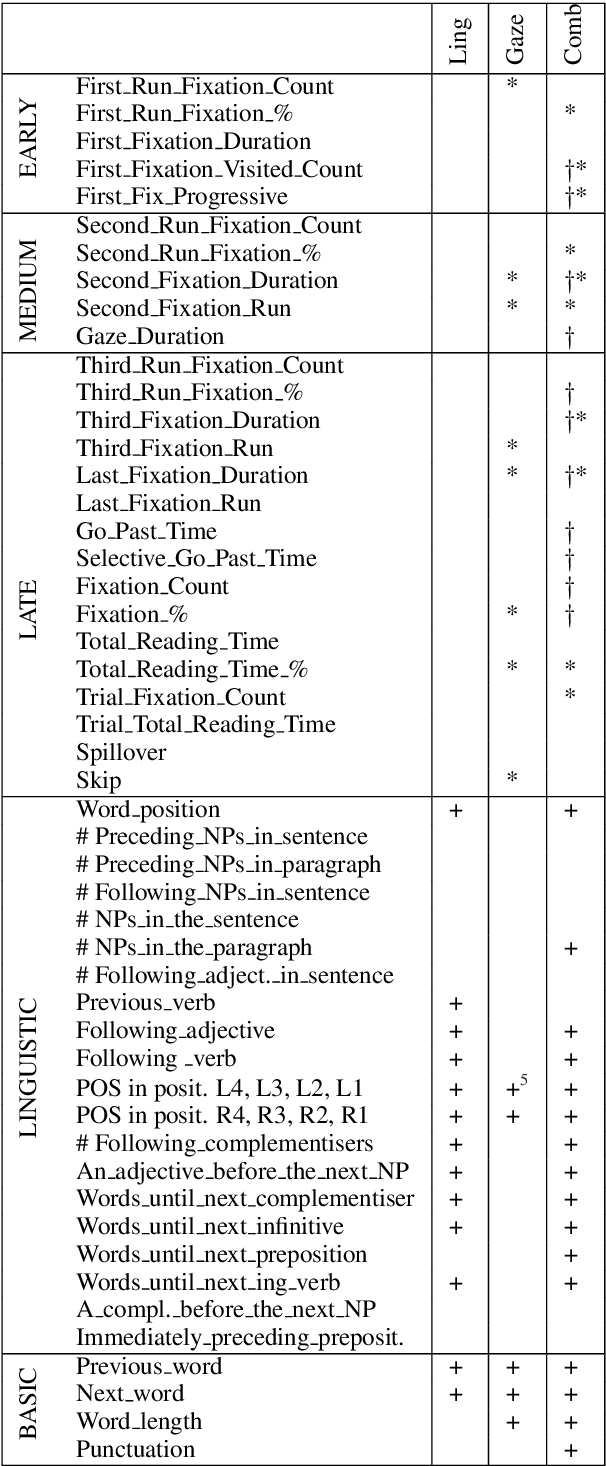
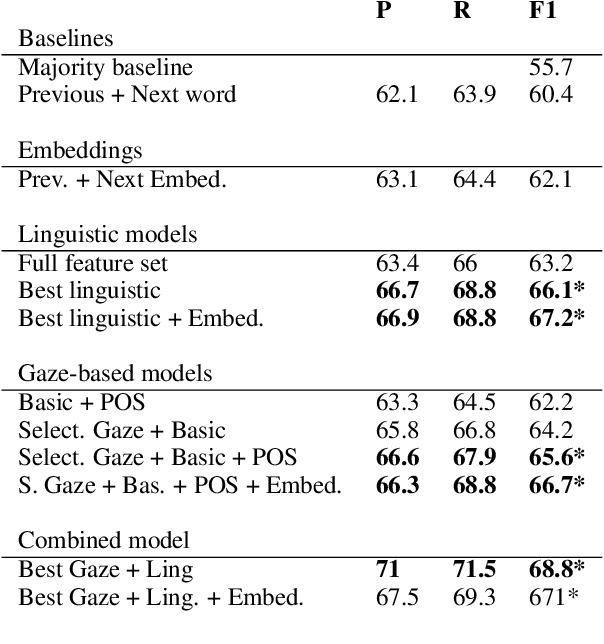
When processing a text, humans and machines must disambiguate between different uses of the pronoun it, including non-referential, nominal anaphoric or clause anaphoric ones. In this paper, we use eye-tracking data to learn how humans perform this disambiguation. We use this knowledge to improve the automatic classification of it. We show that by using gaze data and a POS-tagger we are able to significantly outperform a common baseline and classify between three categories of it with an accuracy comparable to that of linguisticbased approaches. In addition, the discriminatory power of specific gaze features informs the way humans process the pronoun, which, to the best of our knowledge, has not been explored using data from a natural reading task.
Making sense of sensory input
Oct 05, 2019
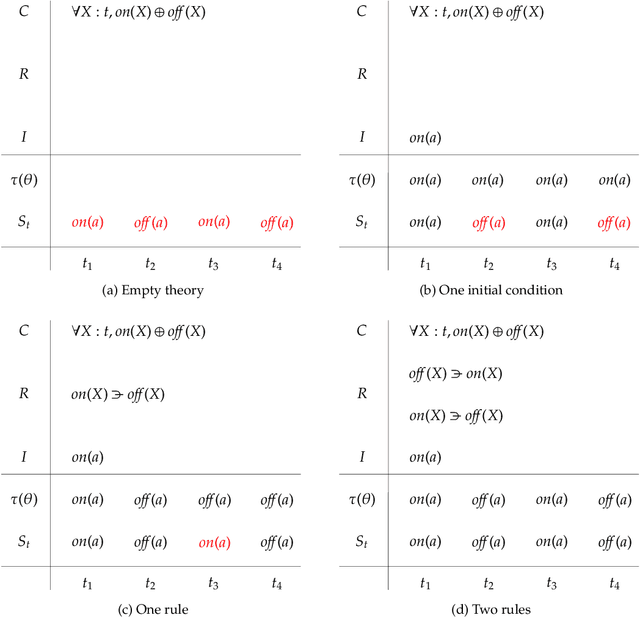
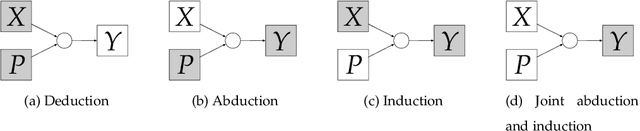
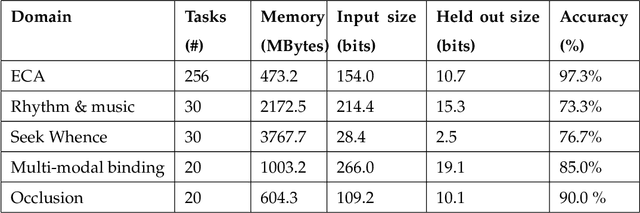
This paper attempts to answer a central question in unsupervised learning: what does it mean to "make sense" of a sensory sequence? In our formalization, making sense involves constructing a symbolic causal theory that explains the sensory sequence and satisfies a set of unity conditions. This model was inspired by Kant's discussion of the synthetic unity of apperception in the Critique of Pure Reason. On our account, making sense of sensory input is a type of program synthesis, but it is unsupervised program synthesis. Our second contribution is a computer implementation, the Apperception Engine, that was designed to satisfy the above requirements. Our system is able to produce interpretable human-readable causal theories from very small amounts of data, because of the strong inductive bias provided by the Kantian unity constraints. A causal theory produced by our system is able to predict future sensor readings, as well as retrodict earlier readings, and "impute" (fill in the blanks of) missing sensory readings, in any combination. We tested the engine in a diverse variety of domains, including cellular automata, rhythms and simple nursery tunes, multi-modal binding problems, occlusion tasks, and sequence induction IQ tests. In each domain, we test our engine's ability to predict future sensor values, retrodict earlier sensor values, and impute missing sensory data. The Apperception Engine performs well in all these domains, significantly out-performing neural net baselines. We note in particular that in the sequence induction IQ tasks, our system achieved human-level performance. This is notable because our system is not a bespoke system designed specifically to solve IQ tasks, but a general purpose apperception system that was designed to make sense of any sensory sequence.
Inductive general game playing
Jun 23, 2019



General game playing (GGP) is a framework for evaluating an agent's general intelligence across a wide range of tasks. In the GGP competition, an agent is given the rules of a game (described as a logic program) that it has never seen before. The task is for the agent to play the game, thus generating game traces. The winner of the GGP competition is the agent that gets the best total score over all the games. In this paper, we invert this task: a learner is given game traces and the task is to learn the rules that could produce the traces. This problem is central to inductive general game playing (IGGP). We introduce a technique that automatically generates IGGP tasks from GGP games. We introduce an IGGP dataset which contains traces from 50 diverse games, such as Sudoku, Sokoban, and Checkers. We claim that IGGP is difficult for existing inductive logic programming (ILP) approaches. To support this claim, we evaluate existing ILP systems on our dataset. Our empirical results show that most of the games cannot be correctly learned by existing systems. The best performing system solves only 40% of the tasks perfectly. Our results suggest that IGGP poses many challenges to existing approaches. Furthermore, because we can automatically generate IGGP tasks from GGP games, our dataset will continue to grow with the GGP competition, as new games are added every year. We therefore think that the IGGP problem and dataset will be valuable for motivating and evaluating future research.
Can Neural Networks Understand Logical Entailment?
Feb 23, 2018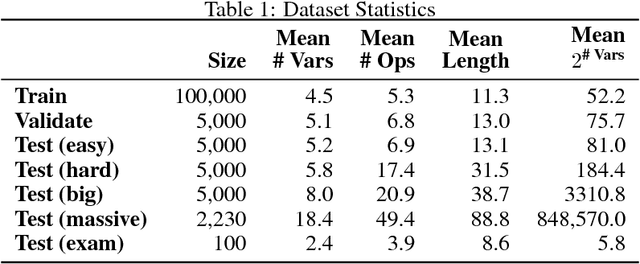
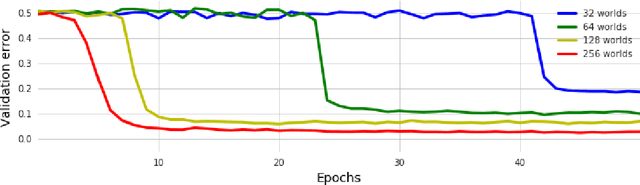
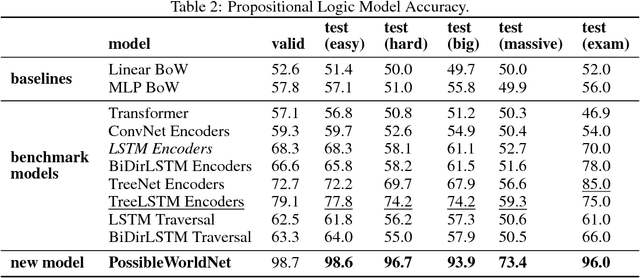
We introduce a new dataset of logical entailments for the purpose of measuring models' ability to capture and exploit the structure of logical expressions against an entailment prediction task. We use this task to compare a series of architectures which are ubiquitous in the sequence-processing literature, in addition to a new model class---PossibleWorldNets---which computes entailment as a "convolution over possible worlds". Results show that convolutional networks present the wrong inductive bias for this class of problems relative to LSTM RNNs, tree-structured neural networks outperform LSTM RNNs due to their enhanced ability to exploit the syntax of logic, and PossibleWorldNets outperform all benchmarks.