 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetry breaking for inductive logic programming
Aug 08, 2025The goal of inductive logic programming is to search for a hypothesis that generalises training data and background knowledge. The challenge is searching vast hypothesis spaces, which is exacerbated because many logically equivalent hypotheses exist. To address this challenge, we introduce a method to break symmetries in the hypothesis space. We implement our idea in answer set programming. Our experiments on multiple domains, including visual reasoning and game playing, show that our approach can reduce solving times from over an hour to just 17 seconds.
Learning Logical Rules using Minimum Message Length
Aug 08, 2025
Unifying probabilistic and logical learning is a key challenge in AI. We introduce a Bayesian inductive logic programming approach that learns minimum message length programs from noisy data. Our approach balances hypothesis complexity and data fit through priors, which explicitly favour more general programs, and a likelihood that favours accurate programs. Our experiments on several domains, including game playing and drug design, show that our method significantly outperforms previous methods, notably those that learn minimum description length programs. Our results also show that our approach is data-efficient and insensitive to example balance, including the ability to learn from exclusively positive examples.
Honey, I shrunk the hypothesis space (through logical preprocessing)
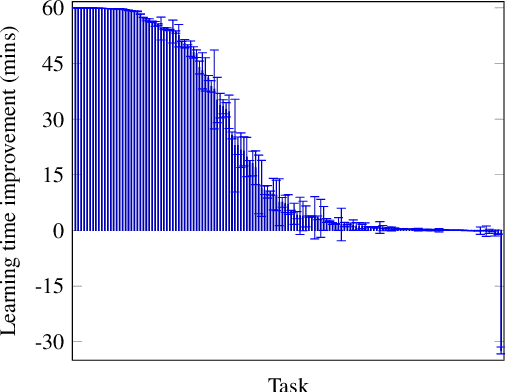
Jun 07, 2025Inductive logic programming (ILP) is a form of logical machine learning. The goal is to search a hypothesis space for a hypothesis that generalises training examples and background knowledge. We introduce an approach that 'shrinks' the hypothesis space before an ILP system searches it. Our approach uses background knowledge to find rules that cannot be in an optimal hypothesis regardless of the training examples. For instance, our approach discovers relationships such as "even numbers cannot be odd" and "prime numbers greater than 2 are odd". It then removes violating rules from the hypothesis space. We implement our approach using answer set programming and use it to shrink the hypothesis space of a constraint-based ILP system. Our experiments on multiple domains, including visual reasoning and game playing, show that our approach can substantially reduce learning times whilst maintaining predictive accuracies. For instance, given just 10 seconds of preprocessing time, our approach can reduce learning times from over 10 hours to only 2 seconds.
An Empirical Comparison of Cost Functions in Inductive Logic Programming
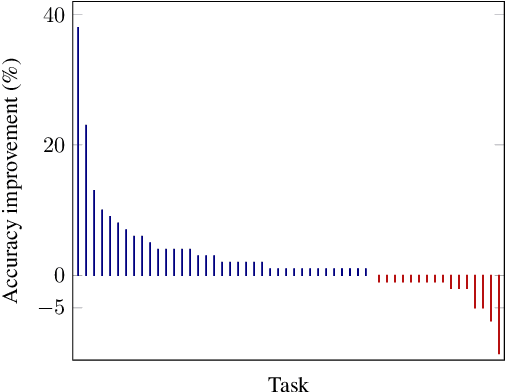
Mar 10, 2025Recent inductive logic programming (ILP) approaches learn optimal hypotheses. An optimal hypothesis minimises a given cost function on the training data. There are many cost functions, such as minimising training error, textual complexity, or the description length of hypotheses. However, selecting an appropriate cost function remains a key question. To address this gap, we extend a constraint-based ILP system to learn optimal hypotheses for seven standard cost functions. We then empirically compare the generalisation error of optimal hypotheses induced under these standard cost functions. Our results on over 20 domains and 1000 tasks, including game playing, program synthesis, and image reasoning, show that, while no cost function consistently outperforms the others, minimising training error or description length has the best overall performance. Notably, our results indicate that minimising the size of hypotheses does not always reduce generalisation error.
Efficient rule induction by ignoring pointless rules
Feb 03, 2025
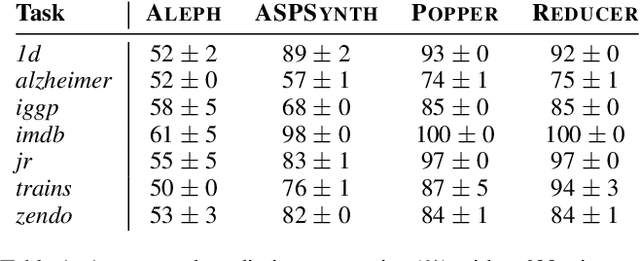
The goal of inductive logic programming (ILP) is to find a set of logical rules that generalises training examples and background knowledge. We introduce an ILP approach that identifies pointless rules. A rule is pointless if it contains a redundant literal or cannot discriminate against negative examples. We show that ignoring pointless rules allows an ILP system to soundly prune the hypothesis space. Our experiments on multiple domains, including visual reasoning and game playing, show that our approach can reduce learning times by 99% whilst maintaining predictive accuracies.
Relational decomposition for program synthesis
Aug 22, 2024
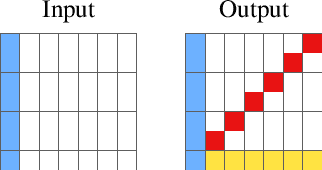

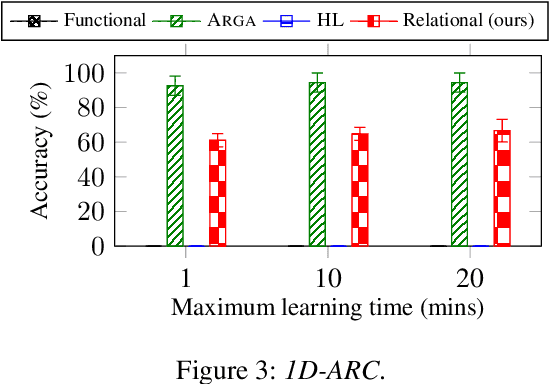
We introduce a novel approach to program synthesis that decomposes complex functional tasks into simpler relational synthesis sub-tasks. We demonstrate the effectiveness of our approach using an off-the-shelf inductive logic programming (ILP) system on three challenging datasets. Our results show that (i) a relational representation can outperform a functional one, and (ii) an off-the-shelf ILP system with a relational encoding can outperform domain-specific approaches.
Scalable Knowledge Refactoring using Constrained Optimisation
Aug 21, 2024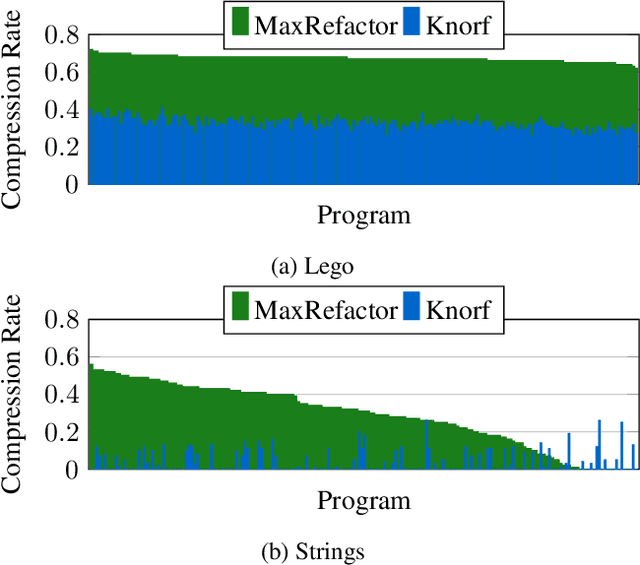
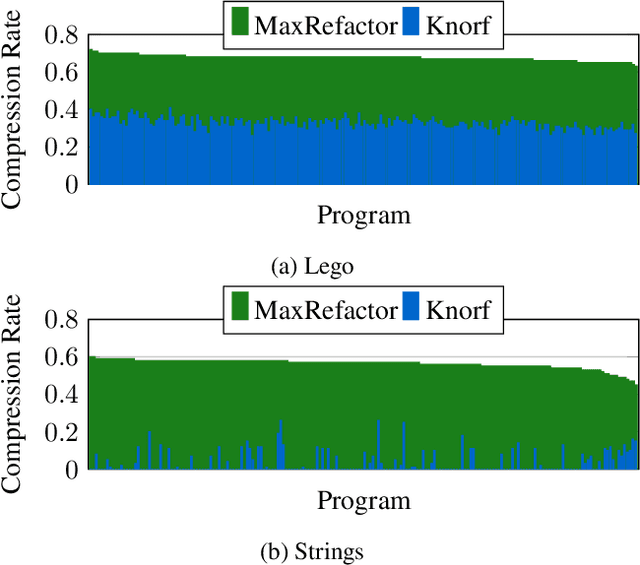
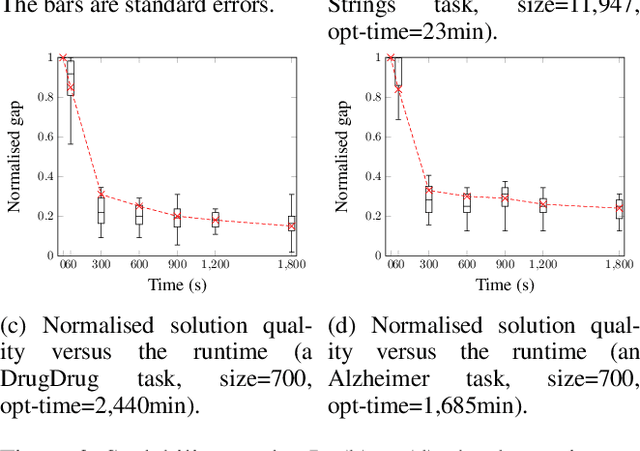
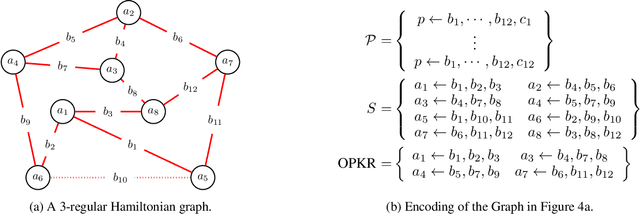
Knowledge refactoring compresses a logic program by introducing new rules. Current approaches struggle to scale to large programs. To overcome this limitation, we introduce a constrained optimisation refactoring approach. Our first key idea is to encode the problem with decision variables based on literals rather than rules. Our second key idea is to focus on linear invented rules. Our empirical results on multiple domains show that our approach can refactor programs quicker and with more compression than the previous state-of-the-art approach, sometimes by 60%.
Can humans teach machines to code?
Apr 30, 2024



The goal of inductive program synthesis is for a machine to automatically generate a program from user-supplied examples of the desired behaviour of the program. A key underlying assumption is that humans can provide examples of sufficient quality to teach a concept to a machine. However, as far as we are aware, this assumption lacks both empirical and theoretical support. To address this limitation, we explore the question `Can humans teach machines to code?'. To answer this question, we conduct a study where we ask humans to generate examples for six programming tasks, such as finding the maximum element of a list. We compare the performance of a program synthesis system trained on (i) human-provided examples, (ii) randomly sampled examples, and (iii) expert-provided examples. Our results show that, on most of the tasks, non-expert participants did not provide sufficient examples for a program synthesis system to learn an accurate program. Our results also show that non-experts need to provide more examples than both randomly sampled and expert-provided examples.
Learning big logical rules by joining small rules
Jan 29, 2024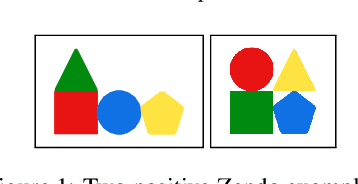
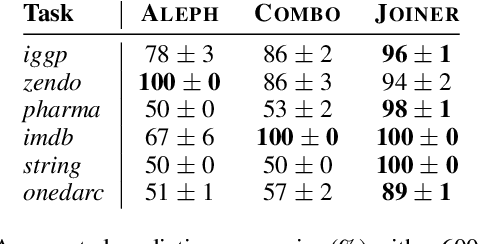
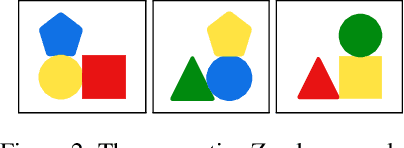
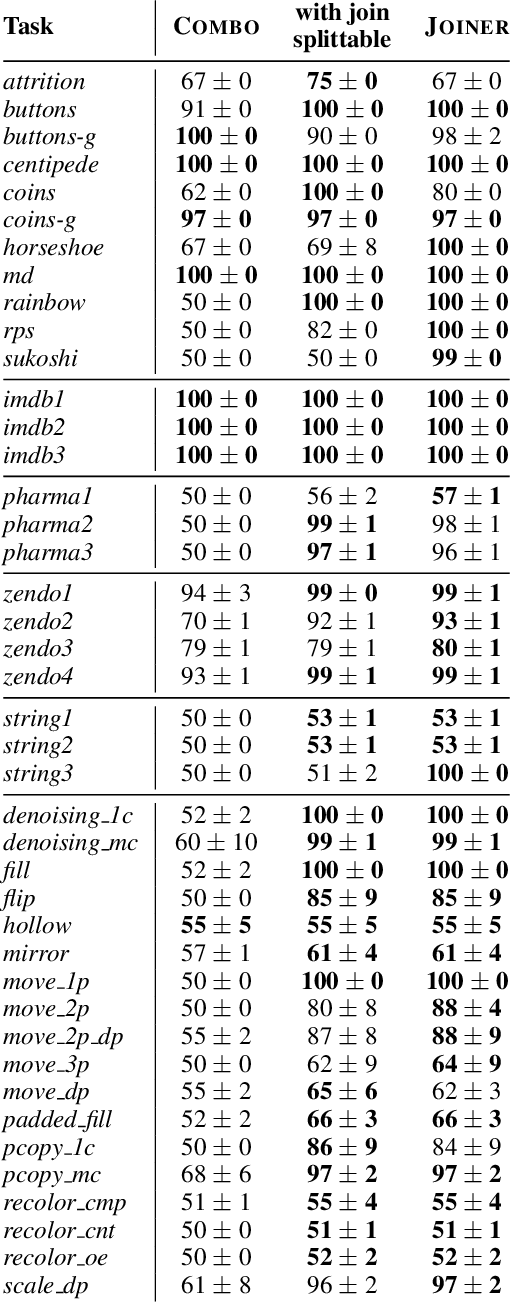
A major challenge in inductive logic programming is learning big rules. To address this challenge, we introduce an approach where we join small rules to learn big rules. We implement our approach in a constraint-driven system and use constraint solvers to efficiently join rules. Our experiments on many domains, including game playing and drug design, show that our approach can (i) learn rules with more than 100 literals, and (ii) drastically outperform existing approaches in terms of predictive accuracies.
Learning logic programs by finding minimal unsatisfiable subprograms
Jan 29, 2024The goal of inductive logic programming (ILP) is to search for a logic program that generalises training examples and background knowledge. We introduce an ILP approach that identifies minimal unsatisfiable subprograms (MUSPs). We show that finding MUSPs allows us to efficiently and soundly prune the search space. Our experiments on multiple domains, including program synthesis and game playing, show that our approach can reduce learning times by 99%.