 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
Jan 15, 2026Evaluating whether multimodal large language models truly understand long-form scientific papers remains challenging: answer-only metrics and synthetic "Needle-In-A-Haystack" tests often reward answer matching without requiring a causal, evidence-linked reasoning trace in the document. We propose the "Fish-in-the-Ocean" (FITO) paradigm, which requires models to construct explicit cross-modal evidence chains within native scientific documents. To operationalize FITO, we build SIN-Data, a scientific interleaved corpus that preserves the native interleaving of text and figures. On top of it, we construct SIN-Bench with four progressive tasks covering evidence discovery (SIN-Find), hypothesis verification (SIN-Verify), grounded QA (SIN-QA), and evidence-anchored synthesis (SIN-Summary). We further introduce "No Evidence, No Score", scoring predictions when grounded to verifiable anchors and diagnosing evidence quality via matching, relevance, and logic. Experiments on eight MLLMs show that grounding is the primary bottleneck: Gemini-3-pro achieves the best average overall score (0.573), while GPT-5 attains the highest SIN-QA answer accuracy (0.767) but underperforms on evidence-aligned overall scores, exposing a gap between correctness and traceable support.
The Molecular Structure of Thought: Mapping the Topology of Long Chain-of-Thought Reasoning
Jan 13, 2026Large language models (LLMs) often fail to learn effective long chain-of-thought (Long CoT) reasoning from human or non-Long-CoT LLMs imitation. To understand this, we propose that effective and learnable Long CoT trajectories feature stable molecular-like structures in unified view, which are formed by three interaction types: Deep-Reasoning (covalent-like), Self-Reflection (hydrogen-bond-like), and Self-Exploration (van der Waals-like). Analysis of distilled trajectories reveals these structures emerge from Long CoT fine-tuning, not keyword imitation. We introduce Effective Semantic Isomers and show that only bonds promoting fast entropy convergence support stable Long CoT learning, while structural competition impairs training. Drawing on these findings, we present Mole-Syn, a distribution-transfer-graph method that guides synthesis of effective Long CoT structures, boosting performance and RL stability across benchmarks.
O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Finding Kissing Numbers with Game-theoretic Reinforcement Learning
Nov 17, 2025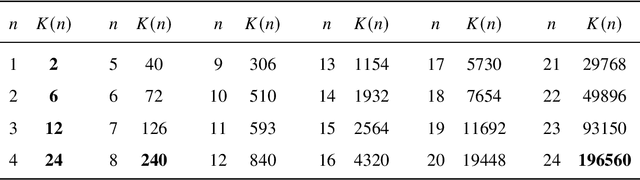
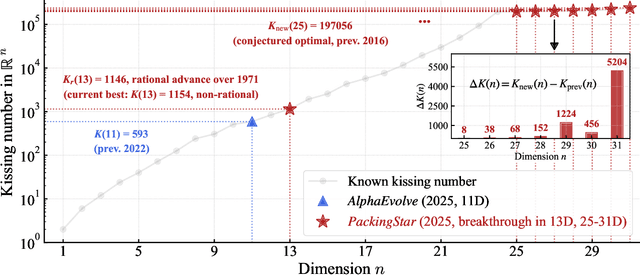

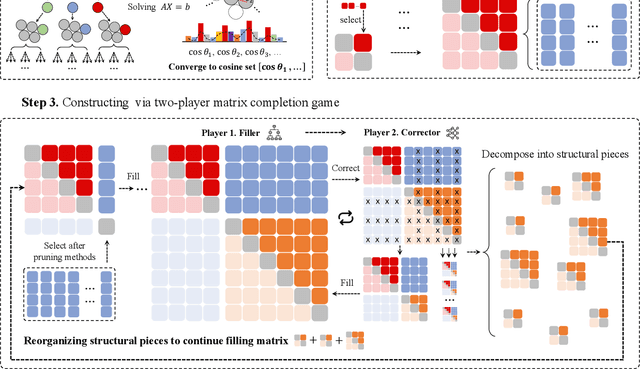
Since Isaac Newton first studied the Kissing Number Problem in 1694, determining the maximal number of non-overlapping spheres around a central sphere has remained a fundamental challenge. This problem represents the local analogue of Hilbert's 18th problem on sphere packing, bridging geometry, number theory, and information theory. Although significant progress has been made through lattices and codes, the irregularities of high-dimensional geometry and exponentially growing combinatorial complexity beyond 8 dimensions, which exceeds the complexity of Go game, limit the scalability of existing methods. Here we model this problem as a two-player matrix completion game and train the game-theoretic reinforcement learning system, PackingStar, to efficiently explore high-dimensional spaces. The matrix entries represent pairwise cosines of sphere center vectors; one player fills entries while another corrects suboptimal ones, jointly maximizing the matrix size, corresponding to the kissing number. This cooperative dynamics substantially improves sample quality, making the extremely large spaces tractable. PackingStar reproduces previous configurations and surpasses all human-known records from dimensions 25 to 31, with the configuration in 25 dimensions geometrically corresponding to the Leech lattice and suggesting possible optimality. It achieves the first breakthrough beyond rational structures from 1971 in 13 dimensions and discovers over 6000 new structures in 14 and other dimensions. These results demonstrate AI's power to explore high-dimensional spaces beyond human intuition and open new pathways for the Kissing Number Problem and broader geometry problems.
Scaling Environments for LLM Agents in the Era of Learning from Interaction: A Survey
Nov 12, 2025LLM-based agents can autonomously accomplish complex tasks across various domains. However, to further cultivate capabilities such as adaptive behavior and long-term decision-making, training on static datasets built from human-level knowledge is insufficient. These datasets are costly to construct and lack both dynamism and realism. A growing consensus is that agents should instead interact directly with environments and learn from experience through reinforcement learning. We formalize this iterative process as the Generation-Execution-Feedback (GEF) loop, where environments generate tasks to challenge agents, return observations in response to agents' actions during task execution, and provide evaluative feedback on rollouts for subsequent learning. Under this paradigm, environments function as indispensable producers of experiential data, highlighting the need to scale them toward greater complexity, realism, and interactivity. In this survey, we systematically review representative methods for environment scaling from a pioneering environment-centric perspective and organize them along the stages of the GEF loop, namely task generation, task execution, and feedback. We further analyze benchmarks, implementation strategies, and applications, consolidating fragmented advances and outlining future research directions for agent intelligence.
Lean4Physics: Comprehensive Reasoning Framework for College-level Physics in Lean4
Oct 30, 2025We present **Lean4PHYS**, a comprehensive reasoning framework for college-level physics problems in Lean4. **Lean4PHYS** includes *LeanPhysBench*, a college-level benchmark for formal physics reasoning in Lean4, which contains 200 hand-crafted and peer-reviewed statements derived from university textbooks and physics competition problems. To establish a solid foundation for formal reasoning in physics, we also introduce *PhysLib*, a community-driven repository containing fundamental unit systems and theorems essential for formal physics reasoning. Based on the benchmark and Lean4 repository we composed in **Lean4PHYS**, we report baseline results using major expert Math Lean4 provers and state-of-the-art closed-source models, with the best performance of DeepSeek-Prover-V2-7B achieving only 16% and Claude-Sonnet-4 achieving 35%. We also conduct a detailed analysis showing that our *PhysLib* can achieve an average improvement of 11.75% in model performance. This demonstrates the challenging nature of our *LeanPhysBench* and the effectiveness of *PhysLib*. To the best of our knowledge, this is the first study to provide a physics benchmark in Lean4.
GUI-ReWalk: Massive Data Generation for GUI Agent via Stochastic Exploration and Intent-Aware Reasoning
Sep 19, 2025Graphical User Interface (GUI) Agents, powered by large language and vision-language models, hold promise for enabling end-to-end automation in digital environments. However, their progress is fundamentally constrained by the scarcity of scalable, high-quality trajectory data. Existing data collection strategies either rely on costly and inconsistent manual annotations or on synthetic generation methods that trade off between diversity and meaningful task coverage. To bridge this gap, we present GUI-ReWalk: a reasoning-enhanced, multi-stage framework for synthesizing realistic and diverse GUI trajectories. GUI-ReWalk begins with a stochastic exploration phase that emulates human trial-and-error behaviors, and progressively transitions into a reasoning-guided phase where inferred goals drive coherent and purposeful interactions. Moreover, it supports multi-stride task generation, enabling the construction of long-horizon workflows across multiple applications. By combining randomness for diversity with goal-aware reasoning for structure, GUI-ReWalk produces data that better reflects the intent-aware, adaptive nature of human-computer interaction. We further train Qwen2.5-VL-7B on the GUI-ReWalk dataset and evaluate it across multiple benchmarks, including Screenspot-Pro, OSWorld-G, UI-Vision, AndroidControl, and GUI-Odyssey. Results demonstrate that GUI-ReWalk enables superior coverage of diverse interaction flows, higher trajectory entropy, and more realistic user intent. These findings establish GUI-ReWalk as a scalable and data-efficient framework for advancing GUI agent research and enabling robust real-world automation.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025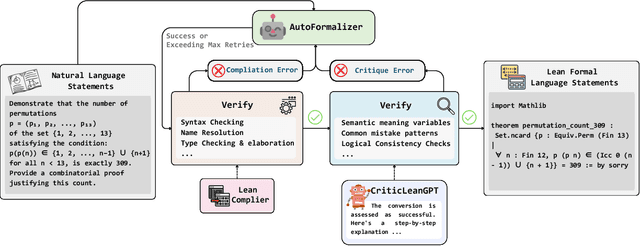

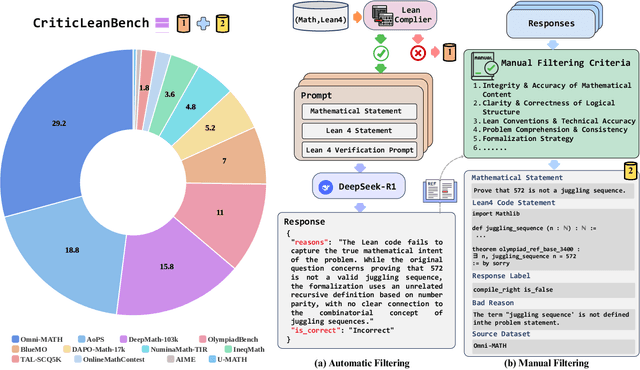
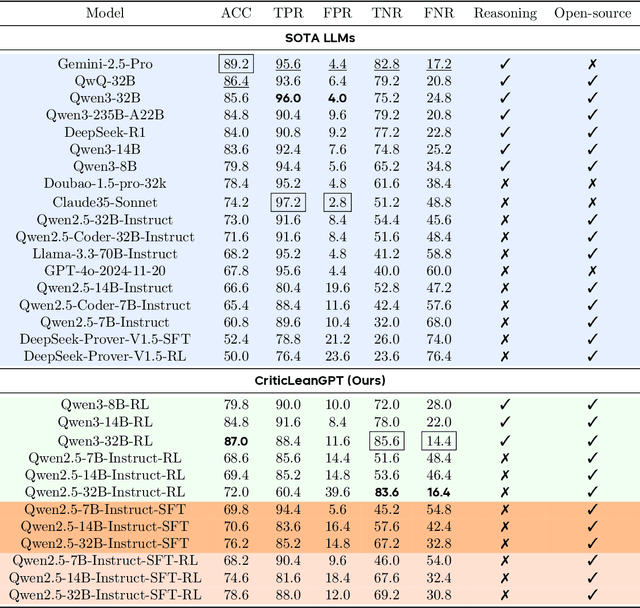
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
What Matters in LLM-generated Data: Diversity and Its Effect on Model Fine-Tuning
Jun 24, 2025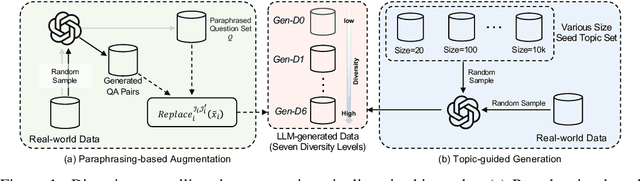
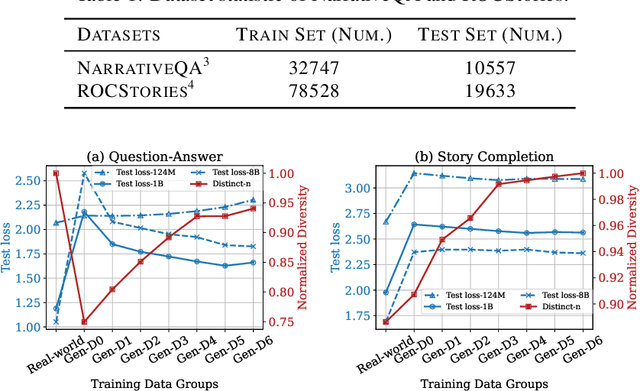
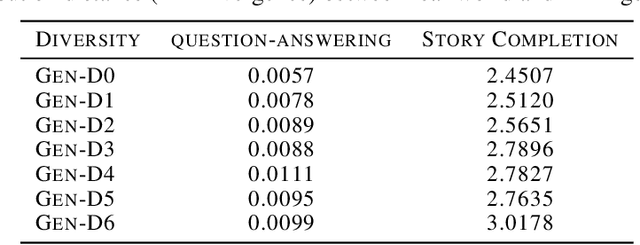
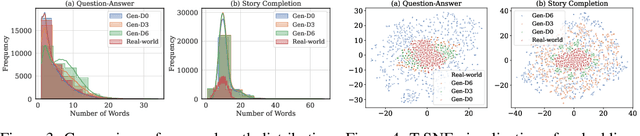
With the remarkable generative capabilities of large language models (LLMs), using LLM-generated data to train downstream models has emerged as a promising approach to mitigate data scarcity in specific domains and reduce time-consuming annotations. However, recent studies have highlighted a critical issue: iterative training on self-generated data results in model collapse, where model performance degrades over time. Despite extensive research on the implications of LLM-generated data, these works often neglect the importance of data diversity, a key factor in data quality. In this work, we aim to understand the implications of the diversity of LLM-generated data on downstream model performance. Specifically, we explore how varying levels of diversity in LLM-generated data affect downstream model performance. Additionally, we investigate the performance of models trained on data that mixes different proportions of LLM-generated data, which we refer to as synthetic data. Our experimental results show that, with minimal distribution shift, moderately diverse LLM-generated data can enhance model performance in scenarios with insufficient labeled data, whereas highly diverse generated data has a negative impact. We hope our empirical findings will offer valuable guidance for future studies on LLMs as data generators.