 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRC-GeoCP: Geometric Consensus for Radar-Camera Collaborative Perception
Feb 28, 2026Collaborative perception (CP) enhances scene understanding through multi-agent information sharing. While LiDAR-centric systems offer precise geometry, high costs and performance degradation in adverse weather necessitate multi-modal alternatives. Despite dense visual semantics and robust spatial measurements, the synergy between cameras and 4D radar remains underexplored in collaborative settings. This work introduces RC-GeoCP, the first framework to explore the fusion of 4D radar and images in CP. To resolve misalignment caused by depth ambiguity and spatial dispersion across agents, RC-GeoCP establishes a radar-anchored geometric consensus. Specifically, Geometric Structure Rectification (GSR) aligns visual semantics with geometry derived from radar to generate spatially grounded, geometry-consistent representations. Uncertainty-Aware Communication (UAC) formulates selective transmission as a conditional entropy reduction process to prioritize informative features based on inter-agent disagreement. Finally, the Consensus-Driven Assembler (CDA) aggregates multi-agent information via shared geometric anchors to form a globally coherent representation. We establish the first unified radar-camera CP benchmark on V2X-Radar and V2X-R, demonstrating state-of-the-art performance with significantly reduced communication overhead. Code will be released soon.
Boosting Instance Awareness via Cross-View Correlation with 4D Radar and Camera for 3D Object Detection
Feb 24, 20264D millimeter-wave radar has emerged as a promising sensing modality for autonomous driving due to its robustness and affordability. However, its sparse and weak geometric cues make reliable instance activation difficult, limiting the effectiveness of existing radar-camera fusion paradigms. BEV-level fusion offers global scene understanding but suffers from weak instance focus, while perspective-level fusion captures instance details but lacks holistic context. To address these limitations, we propose SIFormer, a scene-instance aware transformer for 3D object detection using 4D radar and camera. SIFormer first suppresses background noise during view transformation through segmentation- and depth-guided localization. It then introduces a cross-view activation mechanism that injects 2D instance cues into BEV space, enabling reliable instance awareness under weak radar geometry. Finally, a transformer-based fusion module aggregates complementary image semantics and radar geometry for robust perception. As a result, with the aim of enhancing instance awareness, SIFormer bridges the gap between the two paradigms, combining their complementary strengths to address inherent sparse nature of radar and improve detection accuracy. Experiments demonstrate that SIFormer achieves state-of-the-art performance on View-of-Delft, TJ4DRadSet and NuScenes datasets. Source code is available at github.com/shawnnnkb/SIFormer.
SD4R: Sparse-to-Dense Learning for 3D Object Detection with 4D Radar
Feb 24, 20264D radar measurements offer an affordable and weather-robust solution for 3D perception. However, the inherent sparsity and noise of radar point clouds present significant challenges for accurate 3D object detection, underscoring the need for effective and robust point clouds densification. Despite recent progress, existing densification methods often fail to address the extreme sparsity of 4D radar point clouds and exhibit limited robustness when processing scenes with a small number of points. In this paper, we propose SD4R, a novel framework that transforms sparse radar point clouds into dense representations. SD4R begins by utilizing a foreground point generator (FPG) to mitigate noise propagation and produce densified point clouds. Subsequently, a logit-query encoder (LQE) enhances conventional pillarization, resulting in robust feature representations. Through these innovations, our SD4R demonstrates strong capability in both noise reduction and foreground point densification. Extensive experiments conducted on the publicly available View-of-Delft dataset demonstrate that SD4R achieves state-of-the-art performance. Source code is available at https://github.com/lancelot0805/SD4R.
4DRadar-GS: Self-Supervised Dynamic Driving Scene Reconstruction with 4D Radar
Sep 16, 20253D reconstruction and novel view synthesis are critical for validating autonomous driving systems and training advanced perception models. Recent self-supervised methods have gained significant attention due to their cost-effectiveness and enhanced generalization in scenarios where annotated bounding boxes are unavailable. However, existing approaches, which often rely on frequency-domain decoupling or optical flow, struggle to accurately reconstruct dynamic objects due to imprecise motion estimation and weak temporal consistency, resulting in incomplete or distorted representations of dynamic scene elements. To address these challenges, we propose 4DRadar-GS, a 4D Radar-augmented self-supervised 3D reconstruction framework tailored for dynamic driving scenes. Specifically, we first present a 4D Radar-assisted Gaussian initialization scheme that leverages 4D Radar's velocity and spatial information to segment dynamic objects and recover monocular depth scale, generating accurate Gaussian point representations. In addition, we propose a Velocity-guided PointTrack (VGPT) model, which is jointly trained with the reconstruction pipeline under scene flow supervision, to track fine-grained dynamic trajectories and construct temporally consistent representations. Evaluated on the OmniHD-Scenes dataset, 4DRadar-GS achieves state-of-the-art performance in dynamic driving scene 3D reconstruction.
MultiEditor: Controllable Multimodal Object Editing for Driving Scenarios Using 3D Gaussian Splatting Priors
Jul 30, 2025Autonomous driving systems rely heavily on multimodal perception data to understand complex environments. However, the long-tailed distribution of real-world data hinders generalization, especially for rare but safety-critical vehicle categories. To address this challenge, we propose MultiEditor, a dual-branch latent diffusion framework designed to edit images and LiDAR point clouds in driving scenarios jointly. At the core of our approach is introducing 3D Gaussian Splatting (3DGS) as a structural and appearance prior for target objects. Leveraging this prior, we design a multi-level appearance control mechanism--comprising pixel-level pasting, semantic-level guidance, and multi-branch refinement--to achieve high-fidelity reconstruction across modalities. We further propose a depth-guided deformable cross-modality condition module that adaptively enables mutual guidance between modalities using 3DGS-rendered depth, significantly enhancing cross-modality consistency. Extensive experiments demonstrate that MultiEditor achieves superior performance in visual and geometric fidelity, editing controllability, and cross-modality consistency. Furthermore, generating rare-category vehicle data with MultiEditor substantially enhances the detection accuracy of perception models on underrepresented classes.
MS-Occ: Multi-Stage LiDAR-Camera Fusion for 3D Semantic Occupancy Prediction
Apr 22, 2025Accurate 3D semantic occupancy perception is essential for autonomous driving in complex environments with diverse and irregular objects. While vision-centric methods suffer from geometric inaccuracies, LiDAR-based approaches often lack rich semantic information. To address these limitations, MS-Occ, a novel multi-stage LiDAR-camera fusion framework which includes middle-stage fusion and late-stage fusion, is proposed, integrating LiDAR's geometric fidelity with camera-based semantic richness via hierarchical cross-modal fusion. The framework introduces innovations at two critical stages: (1) In the middle-stage feature fusion, the Gaussian-Geo module leverages Gaussian kernel rendering on sparse LiDAR depth maps to enhance 2D image features with dense geometric priors, and the Semantic-Aware module enriches LiDAR voxels with semantic context via deformable cross-attention; (2) In the late-stage voxel fusion, the Adaptive Fusion (AF) module dynamically balances voxel features across modalities, while the High Classification Confidence Voxel Fusion (HCCVF) module resolves semantic inconsistencies using self-attention-based refinement. Experiments on the nuScenes-OpenOccupancy benchmark show that MS-Occ achieves an Intersection over Union (IoU) of 32.1% and a mean IoU (mIoU) of 25.3%, surpassing the state-of-the-art by +0.7% IoU and +2.4% mIoU. Ablation studies further validate the contribution of each module, with substantial improvements in small-object perception, demonstrating the practical value of MS-Occ for safety-critical autonomous driving scenarios.
TDFANet: Encoding Sequential 4D Radar Point Clouds Using Trajectory-Guided Deformable Feature Aggregation for Place Recognition
Apr 07, 2025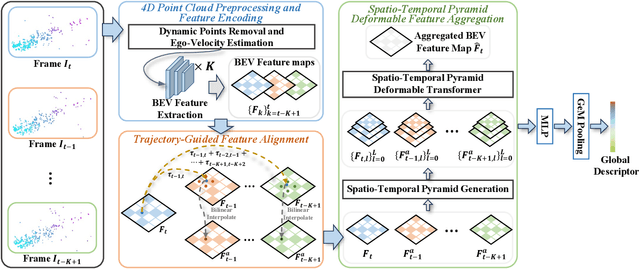
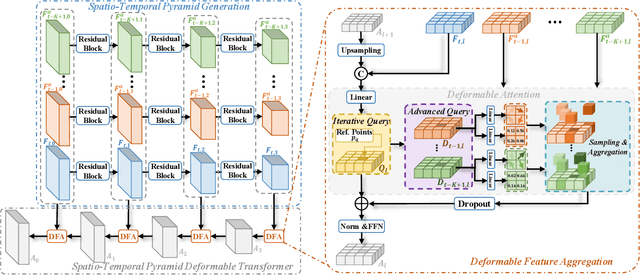
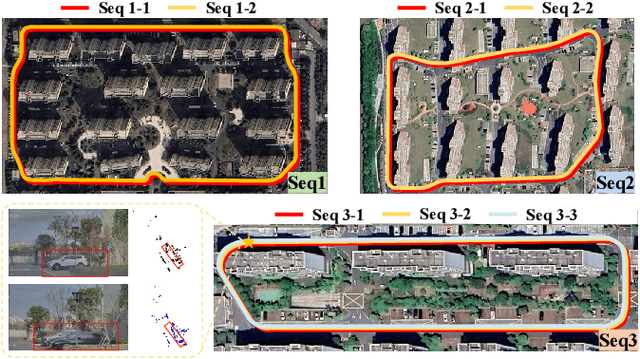

Place recognition is essential for achieving closed-loop or global positioning in autonomous vehicles and mobile robots. Despite recent advancements in place recognition using 2D cameras or 3D LiDAR, it remains to be seen how to use 4D radar for place recognition - an increasingly popular sensor for its robustness against adverse weather and lighting conditions. Compared to LiDAR point clouds, radar data are drastically sparser, noisier and in much lower resolution, which hampers their ability to effectively represent scenes, posing significant challenges for 4D radar-based place recognition. This work addresses these challenges by leveraging multi-modal information from sequential 4D radar scans and effectively extracting and aggregating spatio-temporal features.Our approach follows a principled pipeline that comprises (1) dynamic points removal and ego-velocity estimation from velocity property, (2) bird's eye view (BEV) feature encoding on the refined point cloud, (3) feature alignment using BEV feature map motion trajectory calculated by ego-velocity, (4) multi-scale spatio-temporal features of the aligned BEV feature maps are extracted and aggregated.Real-world experimental results validate the feasibility of the proposed method and demonstrate its robustness in handling dynamic environments. Source codes are available.
Talk2PC: Enhancing 3D Visual Grounding through LiDAR and Radar Point Clouds Fusion for Autonomous Driving
Mar 11, 2025Embodied outdoor scene understanding forms the foundation for autonomous agents to perceive, analyze, and react to dynamic driving environments. However, existing 3D understanding is predominantly based on 2D Vision-Language Models (VLMs), collecting and processing limited scene-aware contexts. Instead, compared to the 2D planar visual information, point cloud sensors like LiDAR offer rich depth information and fine-grained 3D representations of objects. Meanwhile, the emerging 4D millimeter-wave (mmWave) radar is capable of detecting the motion trend, velocity, and reflection intensity of each object. Therefore, the integration of these two modalities provides more flexible querying conditions for natural language, enabling more accurate 3D visual grounding. To this end, in this paper, we exploratively propose a novel method called TPCNet, the first outdoor 3D visual grounding model upon the paradigm of prompt-guided point cloud sensor combination, including both LiDAR and radar contexts. To adaptively balance the features of these two sensors required by the prompt, we have designed a multi-fusion paradigm called Two-Stage Heterogeneous Modal Adaptive Fusion. Specifically, this paradigm initially employs Bidirectional Agent Cross-Attention (BACA), which feeds dual-sensor features, characterized by global receptive fields, to the text features for querying. Additionally, we have designed a Dynamic Gated Graph Fusion (DGGF) module to locate the regions of interest identified by the queries. To further enhance accuracy, we innovatively devise an C3D-RECHead, based on the nearest object edge. Our experiments have demonstrated that our TPCNet, along with its individual modules, achieves the state-of-the-art performance on both the Talk2Radar and Talk2Car datasets.
MetaOcc: Surround-View 4D Radar and Camera Fusion Framework for 3D Occupancy Prediction with Dual Training Strategies
Jan 26, 2025



3D occupancy prediction is crucial for autonomous driving perception. Fusion of 4D radar and camera provides a potential solution of robust occupancy prediction on serve weather with least cost. How to achieve effective multi-modal feature fusion and reduce annotation costs remains significant challenges. In this work, we propose MetaOcc, a novel multi-modal occupancy prediction framework that fuses surround-view cameras and 4D radar for comprehensive environmental perception. We first design a height self-attention module for effective 3D feature extraction from sparse radar points. Then, a local-global fusion mechanism is proposed to adaptively capture modality contributions while handling spatio-temporal misalignments. Temporal alignment and fusion module is employed to further aggregate historical feature. Furthermore, we develop a semi-supervised training procedure leveraging open-set segmentor and geometric constraints for pseudo-label generation, enabling robust perception with limited annotations. Extensive experiments on OmniHD-Scenes dataset demonstrate that MetaOcc achieves state-of-the-art performance, surpassing previous methods by significant margins. Notably, as the first semi-supervised 4D radar and camera fusion-based occupancy prediction approach, MetaOcc maintains 92.5% of the fully-supervised performance while using only 50% of ground truth annotations, establishing a new benchmark for multi-modal 3D occupancy prediction. Code and data are available at https://github.com/LucasYang567/MetaOcc.
Doracamom: Joint 3D Detection and Occupancy Prediction with Multi-view 4D Radars and Cameras for Omnidirectional Perception
Jan 26, 2025



3D object detection and occupancy prediction are critical tasks in autonomous driving, attracting significant attention. Despite the potential of recent vision-based methods, they encounter challenges under adverse conditions. Thus, integrating cameras with next-generation 4D imaging radar to achieve unified multi-task perception is highly significant, though research in this domain remains limited. In this paper, we propose Doracamom, the first framework that fuses multi-view cameras and 4D radar for joint 3D object detection and semantic occupancy prediction, enabling comprehensive environmental perception. Specifically, we introduce a novel Coarse Voxel Queries Generator that integrates geometric priors from 4D radar with semantic features from images to initialize voxel queries, establishing a robust foundation for subsequent Transformer-based refinement. To leverage temporal information, we design a Dual-Branch Temporal Encoder that processes multi-modal temporal features in parallel across BEV and voxel spaces, enabling comprehensive spatio-temporal representation learning. Furthermore, we propose a Cross-Modal BEV-Voxel Fusion module that adaptively fuses complementary features through attention mechanisms while employing auxiliary tasks to enhance feature quality. Extensive experiments on the OmniHD-Scenes, View-of-Delft (VoD), and TJ4DRadSet datasets demonstrate that Doracamom achieves state-of-the-art performance in both tasks, establishing new benchmarks for multi-modal 3D perception. Code and models will be publicly available.