 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNOI-4DRO: Deep 4D Radar Odometry with Differentiable Neural-Optimization Iterations
May 18, 2025A novel learning-optimization-combined 4D radar odometry model, named DNOI-4DRO, is proposed in this paper. The proposed model seamlessly integrates traditional geometric optimization with end-to-end neural network training, leveraging an innovative differentiable neural-optimization iteration operator. In this framework, point-wise motion flow is first estimated using a neural network, followed by the construction of a cost function based on the relationship between point motion and pose in 3D space. The radar pose is then refined using Gauss-Newton updates. Additionally, we design a dual-stream 4D radar backbone that integrates multi-scale geometric features and clustering-based class-aware features to enhance the representation of sparse 4D radar point clouds. Extensive experiments on the VoD and Snail-Radar datasets demonstrate the superior performance of our model, which outperforms recent classical and learning-based approaches. Notably, our method even achieves results comparable to A-LOAM with mapping optimization using LiDAR point clouds as input. Our models and code will be publicly released.
TDFANet: Encoding Sequential 4D Radar Point Clouds Using Trajectory-Guided Deformable Feature Aggregation for Place Recognition
Apr 07, 2025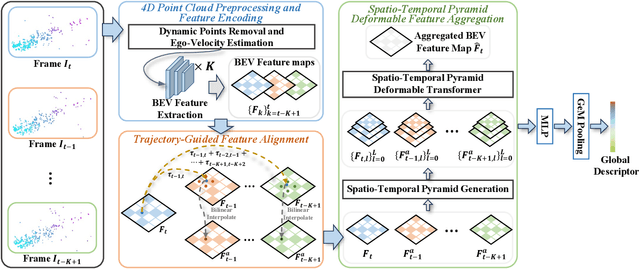
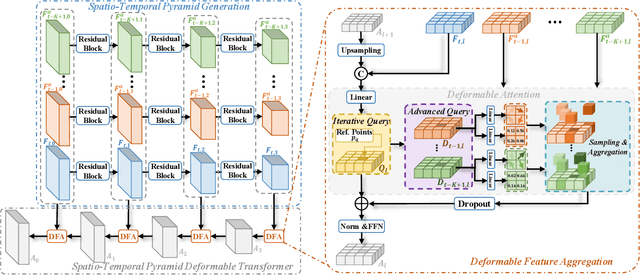

Place recognition is essential for achieving closed-loop or global positioning in autonomous vehicles and mobile robots. Despite recent advancements in place recognition using 2D cameras or 3D LiDAR, it remains to be seen how to use 4D radar for place recognition - an increasingly popular sensor for its robustness against adverse weather and lighting conditions. Compared to LiDAR point clouds, radar data are drastically sparser, noisier and in much lower resolution, which hampers their ability to effectively represent scenes, posing significant challenges for 4D radar-based place recognition. This work addresses these challenges by leveraging multi-modal information from sequential 4D radar scans and effectively extracting and aggregating spatio-temporal features.Our approach follows a principled pipeline that comprises (1) dynamic points removal and ego-velocity estimation from velocity property, (2) bird's eye view (BEV) feature encoding on the refined point cloud, (3) feature alignment using BEV feature map motion trajectory calculated by ego-velocity, (4) multi-scale spatio-temporal features of the aligned BEV feature maps are extracted and aggregated.Real-world experimental results validate the feasibility of the proposed method and demonstrate its robustness in handling dynamic environments. Source codes are available.
4DRVO-Net: Deep 4D Radar-Visual Odometry Using Multi-Modal and Multi-Scale Adaptive Fusion
Aug 12, 2023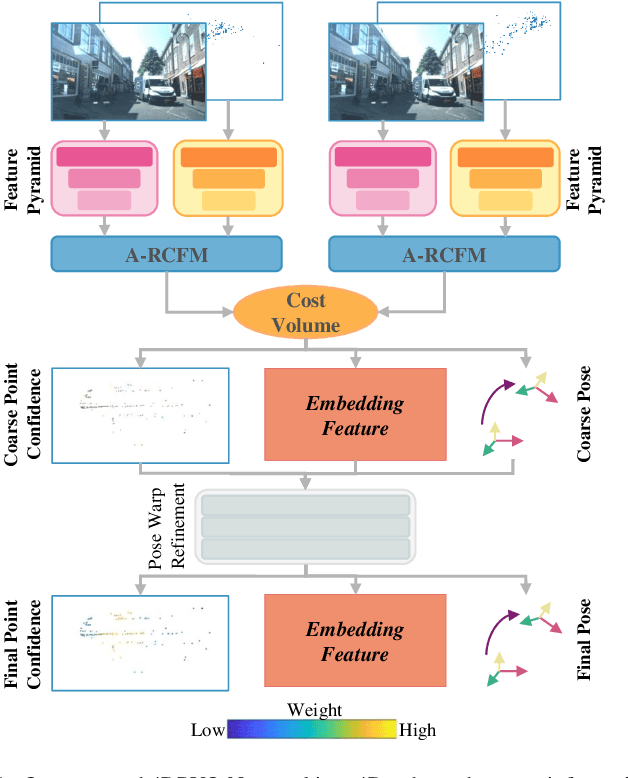
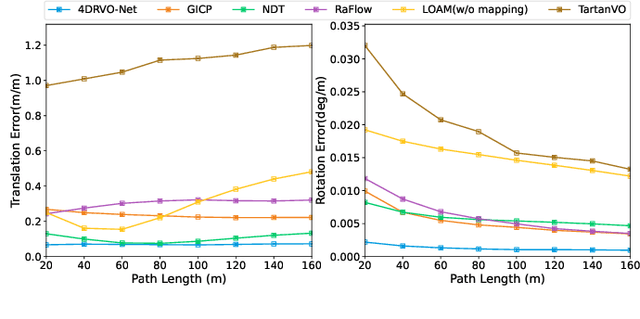
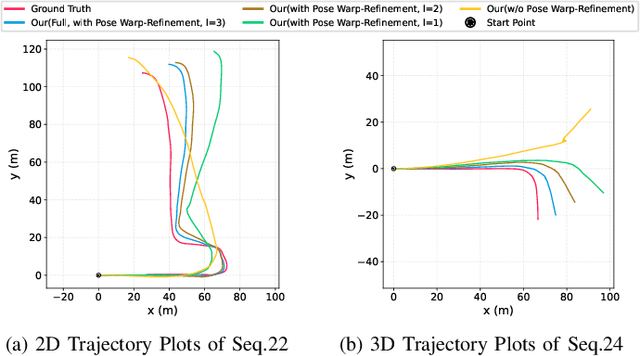
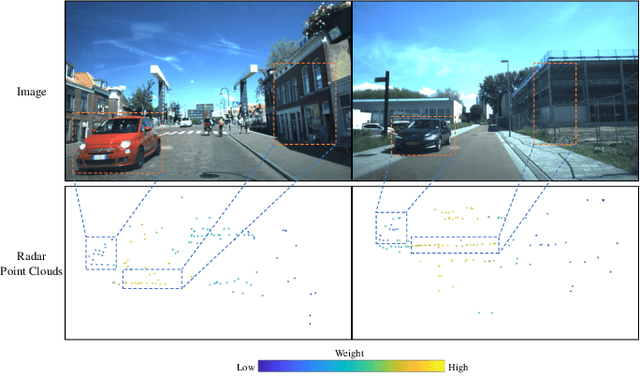
Four-dimensional (4D) radar--visual odometry (4DRVO) integrates complementary information from 4D radar and cameras, making it an attractive solution for achieving accurate and robust pose estimation. However, 4DRVO may exhibit significant tracking errors owing to three main factors: 1) sparsity of 4D radar point clouds; 2) inaccurate data association and insufficient feature interaction between the 4D radar and camera; and 3) disturbances caused by dynamic objects in the environment, affecting odometry estimation. In this paper, we present 4DRVO-Net, which is a method for 4D radar--visual odometry. This method leverages the feature pyramid, pose warping, and cost volume (PWC) network architecture to progressively estimate and refine poses. Specifically, we propose a multi-scale feature extraction network called Radar-PointNet++ that fully considers rich 4D radar point information, enabling fine-grained learning for sparse 4D radar point clouds. To effectively integrate the two modalities, we design an adaptive 4D radar--camera fusion module (A-RCFM) that automatically selects image features based on 4D radar point features, facilitating multi-scale cross-modal feature interaction and adaptive multi-modal feature fusion. In addition, we introduce a velocity-guided point-confidence estimation module to measure local motion patterns, reduce the influence of dynamic objects and outliers, and provide continuous updates during pose refinement. We demonstrate the excellent performance of our method and the effectiveness of each module design on both the VoD and in-house datasets. Our method outperforms all learning-based and geometry-based methods for most sequences in the VoD dataset. Furthermore, it has exhibited promising performance that closely approaches that of the 64-line LiDAR odometry results of A-LOAM without mapping optimization.
Learning Discriminative Representations for Skeleton Based Action Recognition
Mar 14, 2023Human action recognition aims at classifying the category of human action from a segment of a video. Recently, people have dived into designing GCN-based models to extract features from skeletons for performing this task, because skeleton representations are much more efficient and robust than other modalities such as RGB frames. However, when employing the skeleton data, some important clues like related items are also discarded. It results in some ambiguous actions that are hard to be distinguished and tend to be misclassified. To alleviate this problem, we propose an auxiliary feature refinement head (FR Head), which consists of spatial-temporal decoupling and contrastive feature refinement, to obtain discriminative representations of skeletons. Ambiguous samples are dynamically discovered and calibrated in the feature space. Furthermore, FR Head could be imposed on different stages of GCNs to build a multi-level refinement for stronger supervision. Extensive experiments are conducted on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets. Our proposed models obtain competitive results from state-of-the-art methods and can help to discriminate those ambiguous samples. Codes are available at https://github.com/zhysora/FR-Head.
PanFormer: a Transformer Based Model for Pan-sharpening
Mar 22, 2022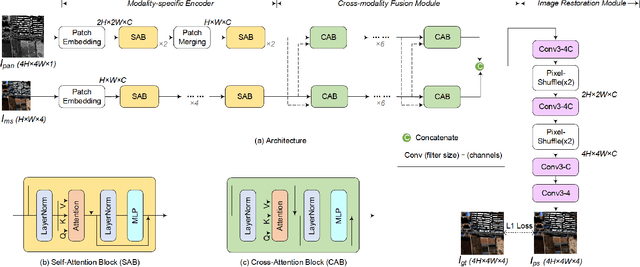
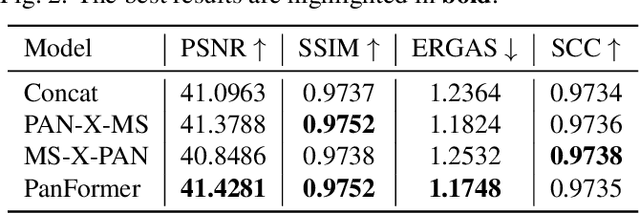
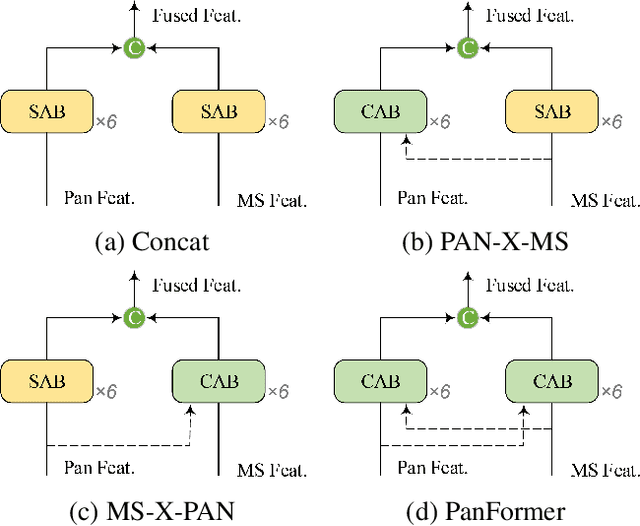
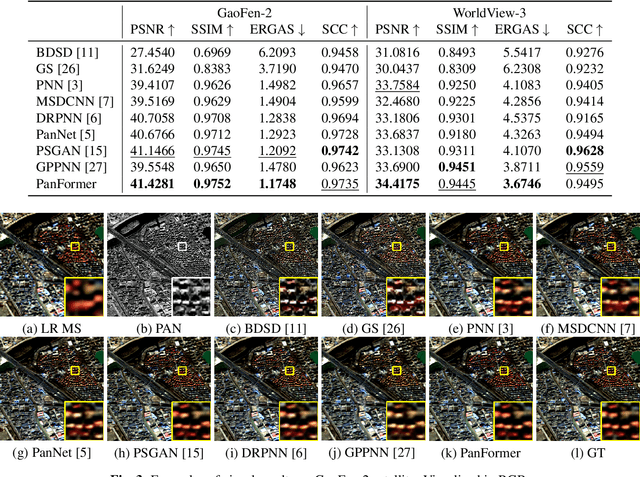
Pan-sharpening aims at producing a high-resolution (HR) multi-spectral (MS) image from a low-resolution (LR) multi-spectral (MS) image and its corresponding panchromatic (PAN) image acquired by a same satellite. Inspired by a new fashion in recent deep learning community, we propose a novel Transformer based model for pan-sharpening. We explore the potential of Transformer in image feature extraction and fusion. Following the successful development of vision transformers, we design a two-stream network with the self-attention to extract the modality-specific features from the PAN and MS modalities and apply a cross-attention module to merge the spectral and spatial features. The pan-sharpened image is produced from the enhanced fused features. Extensive experiments on GaoFen-2 and WorldView-3 images demonstrate that our Transformer based model achieves impressive results and outperforms many existing CNN based methods, which shows the great potential of introducing Transformer to the pan-sharpening task. Codes are available at https://github.com/zhysora/PanFormer.
Unsupervised Cycle-consistent Generative Adversarial Networks for Pan-sharpening
Sep 21, 2021


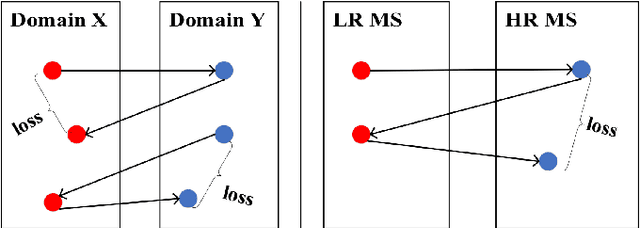
Deep learning based pan-sharpening has received significant research interest in recent years. Most of existing methods fall into the supervised learning framework in which they down-sample the multi-spectral (MS) and panchromatic (PAN) images and regard the original MS images as ground truths to form training samples. Although impressive performance could be achieved, they have difficulties generalizing to the original full-scale images due to the scale gap, which makes them lack of practicability. In this paper, we propose an unsupervised generative adversarial framework that learns from the full-scale images without the ground truths to alleviate this problem. We extract the modality-specific features from the PAN and MS images with a two-stream generator, perform fusion in the feature domain, and then reconstruct the pan-sharpened images. Furthermore, we introduce a novel hybrid loss based on the cycle-consistency and adversarial scheme to improve the performance. Comparison experiments with the state-of-the-art methods are conducted on GaoFen-2 and WorldView-3 satellites. Results demonstrate that the proposed method can greatly improve the pan-sharpening performance on the full-scale images, which clearly show its practical value. Codes and datasets will be made publicly available.
PGMAN: An Unsupervised Generative Multi-adversarial Network for Pan-sharpening
Dec 16, 2020
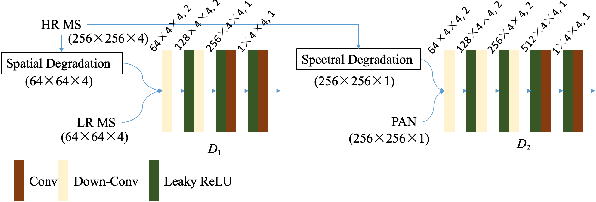


Pan-sharpening aims at fusing a low-resolution (LR) multi-spectral (MS) image and a high-resolution (HR) panchromatic (PAN) image acquired by a satellite to generate an HR MS image. Many deep learning based methods have been developed in the past few years. However, since there are no intended HR MS images as references for learning, almost all of the existing methods down-sample the MS and PAN images and regard the original MS images as targets to form a supervised setting for training. These methods may perform well on the down-scaled images, however, they generalize poorly to the full-resolution images. To conquer this problem, we design an unsupervised framework that is able to learn directly from the full-resolution images without any preprocessing. The model is built based on a novel generative multi-adversarial network. We use a two-stream generator to extract the modality-specific features from the PAN and MS images, respectively, and develop a dual-discriminator to preserve the spectral and spatial information of the inputs when performing fusion. Furthermore, a novel loss function is introduced to facilitate training under the unsupervised setting. Experiments and comparisons with other state-of-the-art methods on GaoFen-2 and QuickBird images demonstrate that the proposed method can obtain much better fusion results on the full-resolution images.