 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSDNet: Efficient 4D Radar Super-Resolution via Multi-Stage Distillation
Sep 16, 2025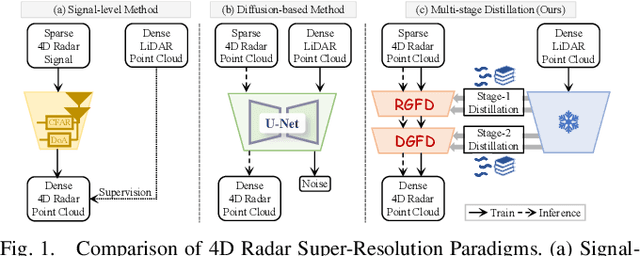
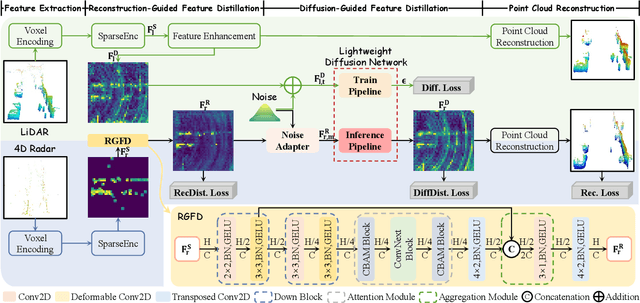
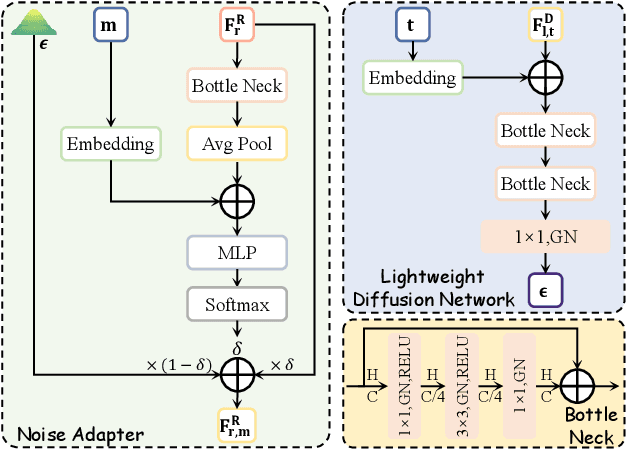
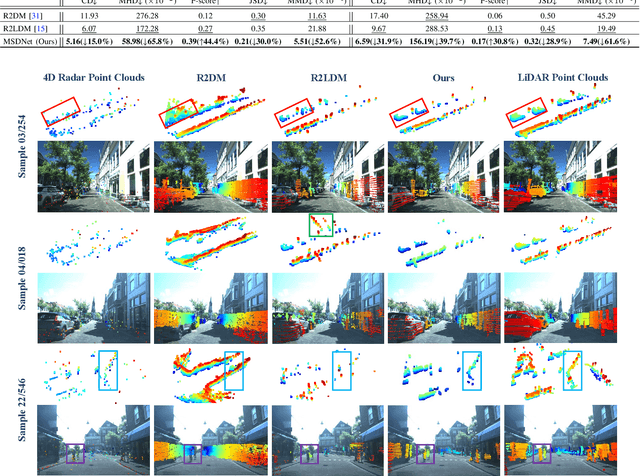
4D radar super-resolution, which aims to reconstruct sparse and noisy point clouds into dense and geometrically consistent representations, is a foundational problem in autonomous perception. However, existing methods often suffer from high training cost or rely on complex diffusion-based sampling, resulting in high inference latency and poor generalization, making it difficult to balance accuracy and efficiency. To address these limitations, we propose MSDNet, a multi-stage distillation framework that efficiently transfers dense LiDAR priors to 4D radar features to achieve both high reconstruction quality and computational efficiency. The first stage performs reconstruction-guided feature distillation, aligning and densifying the student's features through feature reconstruction. In the second stage, we propose diffusion-guided feature distillation, which treats the stage-one distilled features as a noisy version of the teacher's representations and refines them via a lightweight diffusion network. Furthermore, we introduce a noise adapter that adaptively aligns the noise level of the feature with a predefined diffusion timestep, enabling a more precise denoising. Extensive experiments on the VoD and in-house datasets demonstrate that MSDNet achieves both high-fidelity reconstruction and low-latency inference in the task of 4D radar point cloud super-resolution, and consistently improves performance on downstream tasks. The code will be publicly available upon publication.
4DRadar-GS: Self-Supervised Dynamic Driving Scene Reconstruction with 4D Radar
Sep 16, 20253D reconstruction and novel view synthesis are critical for validating autonomous driving systems and training advanced perception models. Recent self-supervised methods have gained significant attention due to their cost-effectiveness and enhanced generalization in scenarios where annotated bounding boxes are unavailable. However, existing approaches, which often rely on frequency-domain decoupling or optical flow, struggle to accurately reconstruct dynamic objects due to imprecise motion estimation and weak temporal consistency, resulting in incomplete or distorted representations of dynamic scene elements. To address these challenges, we propose 4DRadar-GS, a 4D Radar-augmented self-supervised 3D reconstruction framework tailored for dynamic driving scenes. Specifically, we first present a 4D Radar-assisted Gaussian initialization scheme that leverages 4D Radar's velocity and spatial information to segment dynamic objects and recover monocular depth scale, generating accurate Gaussian point representations. In addition, we propose a Velocity-guided PointTrack (VGPT) model, which is jointly trained with the reconstruction pipeline under scene flow supervision, to track fine-grained dynamic trajectories and construct temporally consistent representations. Evaluated on the OmniHD-Scenes dataset, 4DRadar-GS achieves state-of-the-art performance in dynamic driving scene 3D reconstruction.
MultiEditor: Controllable Multimodal Object Editing for Driving Scenarios Using 3D Gaussian Splatting Priors
Jul 30, 2025Autonomous driving systems rely heavily on multimodal perception data to understand complex environments. However, the long-tailed distribution of real-world data hinders generalization, especially for rare but safety-critical vehicle categories. To address this challenge, we propose MultiEditor, a dual-branch latent diffusion framework designed to edit images and LiDAR point clouds in driving scenarios jointly. At the core of our approach is introducing 3D Gaussian Splatting (3DGS) as a structural and appearance prior for target objects. Leveraging this prior, we design a multi-level appearance control mechanism--comprising pixel-level pasting, semantic-level guidance, and multi-branch refinement--to achieve high-fidelity reconstruction across modalities. We further propose a depth-guided deformable cross-modality condition module that adaptively enables mutual guidance between modalities using 3DGS-rendered depth, significantly enhancing cross-modality consistency. Extensive experiments demonstrate that MultiEditor achieves superior performance in visual and geometric fidelity, editing controllability, and cross-modality consistency. Furthermore, generating rare-category vehicle data with MultiEditor substantially enhances the detection accuracy of perception models on underrepresented classes.
DNOI-4DRO: Deep 4D Radar Odometry with Differentiable Neural-Optimization Iterations
May 18, 2025A novel learning-optimization-combined 4D radar odometry model, named DNOI-4DRO, is proposed in this paper. The proposed model seamlessly integrates traditional geometric optimization with end-to-end neural network training, leveraging an innovative differentiable neural-optimization iteration operator. In this framework, point-wise motion flow is first estimated using a neural network, followed by the construction of a cost function based on the relationship between point motion and pose in 3D space. The radar pose is then refined using Gauss-Newton updates. Additionally, we design a dual-stream 4D radar backbone that integrates multi-scale geometric features and clustering-based class-aware features to enhance the representation of sparse 4D radar point clouds. Extensive experiments on the VoD and Snail-Radar datasets demonstrate the superior performance of our model, which outperforms recent classical and learning-based approaches. Notably, our method even achieves results comparable to A-LOAM with mapping optimization using LiDAR point clouds as input. Our models and code will be publicly released.
TDFANet: Encoding Sequential 4D Radar Point Clouds Using Trajectory-Guided Deformable Feature Aggregation for Place Recognition
Apr 07, 2025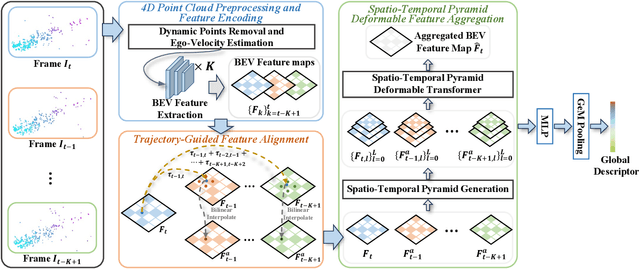
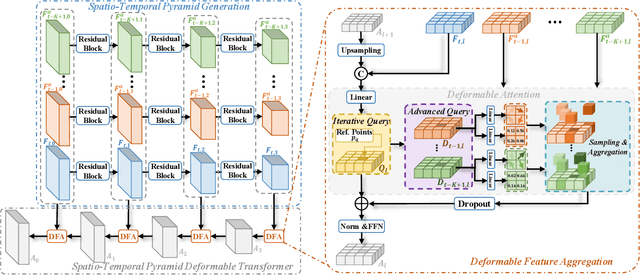
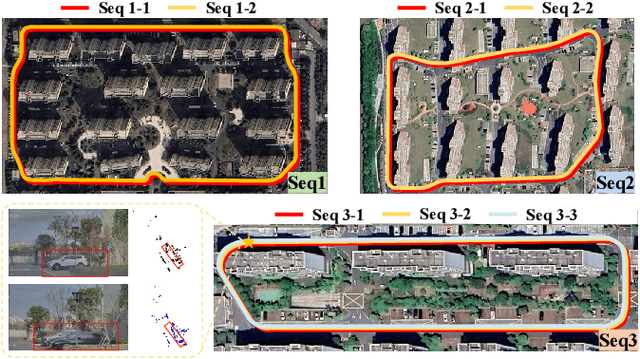

Place recognition is essential for achieving closed-loop or global positioning in autonomous vehicles and mobile robots. Despite recent advancements in place recognition using 2D cameras or 3D LiDAR, it remains to be seen how to use 4D radar for place recognition - an increasingly popular sensor for its robustness against adverse weather and lighting conditions. Compared to LiDAR point clouds, radar data are drastically sparser, noisier and in much lower resolution, which hampers their ability to effectively represent scenes, posing significant challenges for 4D radar-based place recognition. This work addresses these challenges by leveraging multi-modal information from sequential 4D radar scans and effectively extracting and aggregating spatio-temporal features.Our approach follows a principled pipeline that comprises (1) dynamic points removal and ego-velocity estimation from velocity property, (2) bird's eye view (BEV) feature encoding on the refined point cloud, (3) feature alignment using BEV feature map motion trajectory calculated by ego-velocity, (4) multi-scale spatio-temporal features of the aligned BEV feature maps are extracted and aggregated.Real-world experimental results validate the feasibility of the proposed method and demonstrate its robustness in handling dynamic environments. Source codes are available.
R2LDM: An Efficient 4D Radar Super-Resolution Framework Leveraging Diffusion Model
Mar 21, 2025We introduce R2LDM, an innovative approach for generating dense and accurate 4D radar point clouds, guided by corresponding LiDAR point clouds. Instead of utilizing range images or bird's eye view (BEV) images, we represent both LiDAR and 4D radar point clouds using voxel features, which more effectively capture 3D shape information. Subsequently, we propose the Latent Voxel Diffusion Model (LVDM), which performs the diffusion process in the latent space. Additionally, a novel Latent Point Cloud Reconstruction (LPCR) module is utilized to reconstruct point clouds from high-dimensional latent voxel features. As a result, R2LDM effectively generates LiDAR-like point clouds from paired raw radar data. We evaluate our approach on two different datasets, and the experimental results demonstrate that our model achieves 6- to 10-fold densification of radar point clouds, outperforming state-of-the-art baselines in 4D radar point cloud super-resolution. Furthermore, the enhanced radar point clouds generated by our method significantly improve downstream tasks, achieving up to 31.7% improvement in point cloud registration recall rate and 24.9% improvement in object detection accuracy.
4DRVO-Net: Deep 4D Radar-Visual Odometry Using Multi-Modal and Multi-Scale Adaptive Fusion
Aug 12, 2023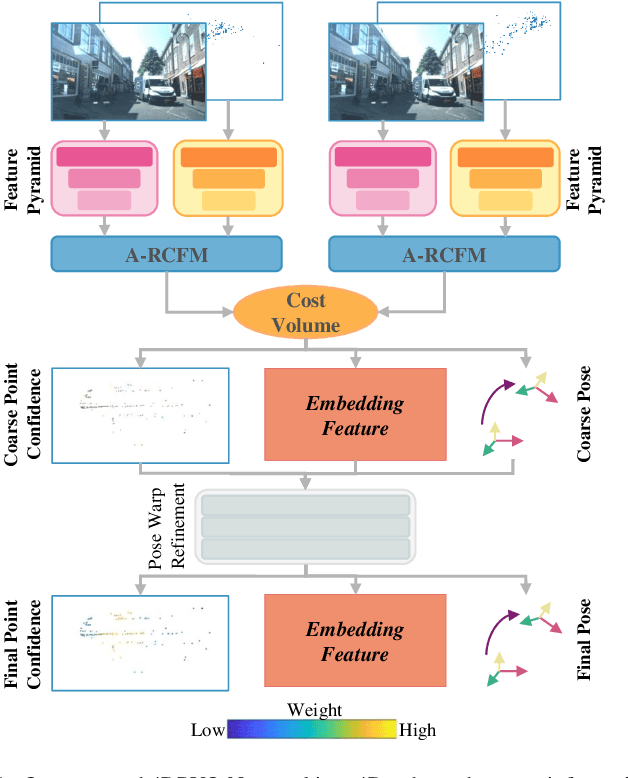
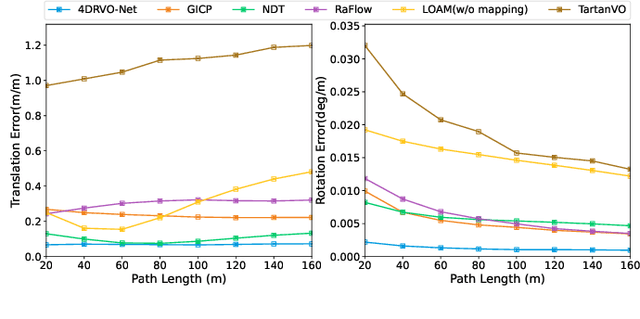
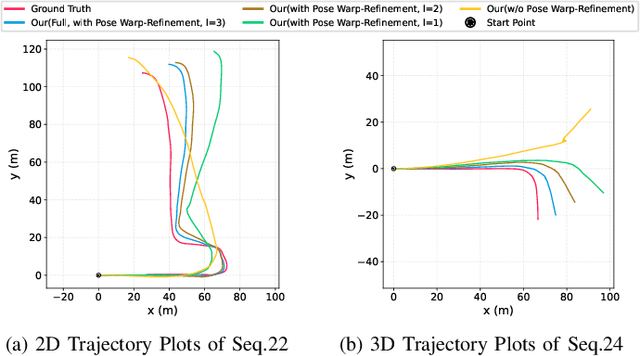
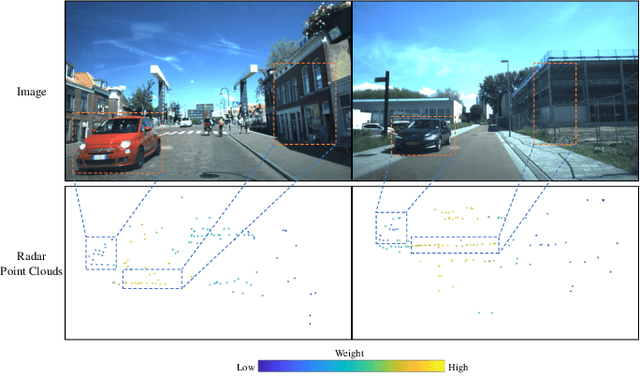
Four-dimensional (4D) radar--visual odometry (4DRVO) integrates complementary information from 4D radar and cameras, making it an attractive solution for achieving accurate and robust pose estimation. However, 4DRVO may exhibit significant tracking errors owing to three main factors: 1) sparsity of 4D radar point clouds; 2) inaccurate data association and insufficient feature interaction between the 4D radar and camera; and 3) disturbances caused by dynamic objects in the environment, affecting odometry estimation. In this paper, we present 4DRVO-Net, which is a method for 4D radar--visual odometry. This method leverages the feature pyramid, pose warping, and cost volume (PWC) network architecture to progressively estimate and refine poses. Specifically, we propose a multi-scale feature extraction network called Radar-PointNet++ that fully considers rich 4D radar point information, enabling fine-grained learning for sparse 4D radar point clouds. To effectively integrate the two modalities, we design an adaptive 4D radar--camera fusion module (A-RCFM) that automatically selects image features based on 4D radar point features, facilitating multi-scale cross-modal feature interaction and adaptive multi-modal feature fusion. In addition, we introduce a velocity-guided point-confidence estimation module to measure local motion patterns, reduce the influence of dynamic objects and outliers, and provide continuous updates during pose refinement. We demonstrate the excellent performance of our method and the effectiveness of each module design on both the VoD and in-house datasets. Our method outperforms all learning-based and geometry-based methods for most sequences in the VoD dataset. Furthermore, it has exhibited promising performance that closely approaches that of the 64-line LiDAR odometry results of A-LOAM without mapping optimization.
Toward Hierarchical Self-Supervised Monocular Absolute Depth Estimation for Autonomous Driving Applications
Apr 12, 2020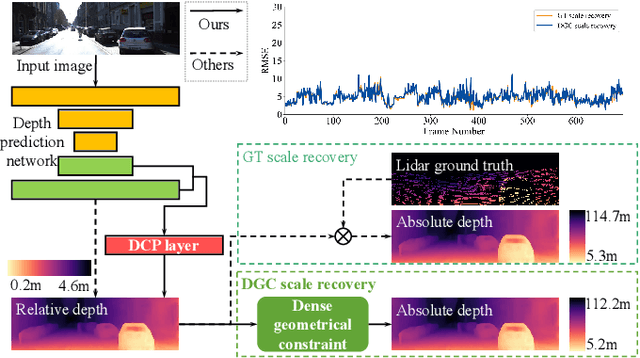
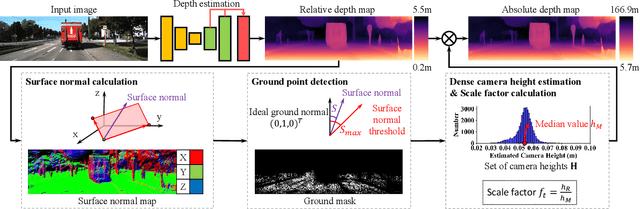


In recent years, self-supervised methods for monocular depth estimation has rapidly become an significant branch of depth estimation task, especially for autonomous driving applications. Despite the high overall precision achieved, current methods still suffer from a) imprecise object-level depth inference and b) uncertain scale factor. The former problem would cause texture copy or provide inaccurate object boundary, and the latter would require current methods to have an additional sensor like LiDAR to provide depth groundtruth or stereo camera as additional training inputs, which makes them difficult to implement. In this work, we propose to address these two problems together by introducing DNet. Our contributions are twofold: a) a novel dense connected prediction (DCP) layer is proposed to provide better object-level depth estimation and b) specifically for autonomous driving scenarios, dense geometrical constrains (DGC) is introduced so that precise scale factor can be recovered without additional cost for autonomous vehicles. Extensive experiments have been conducted and, both DCP layer and DGC module are proved to be effectively solving the aforementioned problems respectively. Thanks to DCP layer, object boundary can now be better distinguished in the depth map and the depth is more continues on object level. It is also demonstrated that the performance of using DGC to perform scale recovery is comparable to that using ground-truth information, when the camera height is given and the ground point takes up more than 1.03% of the pixels. Code will be publicly available once the paper is accepted.