 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Consistent Latent Reasoning: Long Latent Sequence Reasoning for Vision-Language Model
May 13, 2026In language reasoning, longer chains of thought consistently yield better performance, which naturally suggests that visual latent reasoning may likewise benefit from longer latent sequences. However, we discover a counterintuitive phenomenon: the performance of existing latent visual reasoning methods systematically degrades as the latent sequence grows longer. We reveal the root cause: Information Gain Collapse -- autoregressive generation makes each step highly dependent on prior outputs, so subsequent tokens can barely introduce new information. We further identify that heavily pooled ($\geq 128\times$) image embeddings used as supervision targets provide no more signal than meaningless placeholders. Motivated by these insights, we propose SCOLAR (Self-COnsistent LAtent Reasoning), which introduces a lightweight detransformer that leverages the LLM's full-sequence hidden states to generate auxiliary visual tokens in a single shot, with each token independently anchored to the original visual space. Combined with three-stage SFT and ALPO reinforcement learning, SCOLAR extends acceptable latent CoT length by over $30\times$, achieves state-of-the-art among open-source models on real-world reasoning benchmarks (+14.12% over backbone), and demonstrates strong out-of-distribution generalization.
MU-GeNeRF: Multi-view Uncertainty-guided Generalizable Neural Radiance Fields for Distractor-aware Scene
Apr 20, 2026Generalizable Neural Radiance Fields (GeNeRFs) enable high-quality scene reconstruction from sparse views and can generalize to unseen scenes. However, in real-world settings, transient distractors break cross-view structural consistency, corrupting supervision and degrading reconstruction quality. Existing distractor-free NeRF methods rely on per-scene optimization and estimate uncertainty from per-view reconstruction errors, which are not reliable for GeNeRFs and often misjudge inconsistent static structures as distractors. To this end, we propose MU-GeNeRF, a Multi-view Uncertainty-guided distractor-aware GeNeRF framework designed to alleviate GeNeRF's robust modeling challenges in the presence of transient distractions. We decompose distractor awareness into two complementary uncertainty components: Source-view Uncertainty, which captures structural discrepancies across source views caused by viewpoint changes or dynamic factors; and Target-view Uncertainty, which detects observation anomalies in the target image induced by transient distractors.These two uncertainties address distinct error sources and are combined through a heteroscedastic reconstruction loss, which guides the model to adaptively modulate supervision, enabling more robust distractor suppression and geometric modeling.Extensive experiments show that our method not only surpasses existing GeNeRFs but also achieves performance comparable to scene-specific distractor-free NeRFs.
Visually-grounded Humanoid Agents
Apr 09, 2026Digital human generation has been studied for decades and supports a wide range of real-world applications. However, most existing systems are passively animated, relying on privileged state or scripted control, which limits scalability to novel environments. We instead ask: how can digital humans actively behave using only visual observations and specified goals in novel scenes? Achieving this would enable populating any 3D environments with digital humans at scale that exhibit spontaneous, natural, goal-directed behaviors. To this end, we introduce Visually-grounded Humanoid Agents, a coupled two-layer (world-agent) paradigm that replicates humans at multiple levels: they look, perceive, reason, and behave like real people in real-world 3D scenes. The World Layer reconstructs semantically rich 3D Gaussian scenes from real-world videos via an occlusion-aware pipeline and accommodates animatable Gaussian-based human avatars. The Agent Layer transforms these avatars into autonomous humanoid agents, equipping them with first-person RGB-D perception and enabling them to perform accurate, embodied planning with spatial awareness and iterative reasoning, which is then executed at the low level as full-body actions to drive their behaviors in the scene. We further introduce a benchmark to evaluate humanoid-scene interaction in diverse reconstructed environments. Experiments show our agents achieve robust autonomous behavior, yielding higher task success rates and fewer collisions than ablations and state-of-the-art planning methods. This work enables active digital human population and advances human-centric embodied AI. Data, code, and models will be open-sourced.
A Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
LiDARDraft: Generating LiDAR Point Cloud from Versatile Inputs
Dec 23, 2025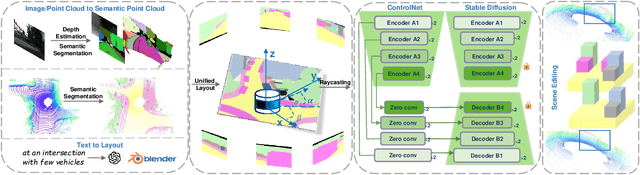
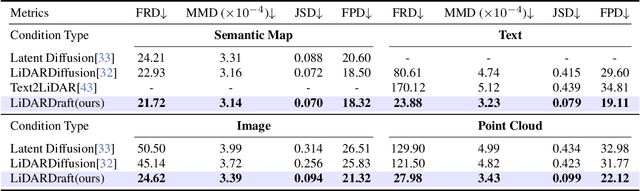
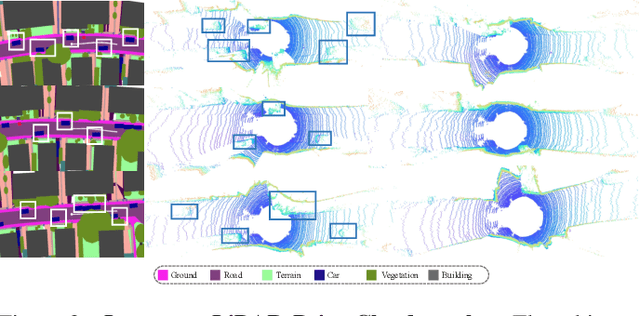
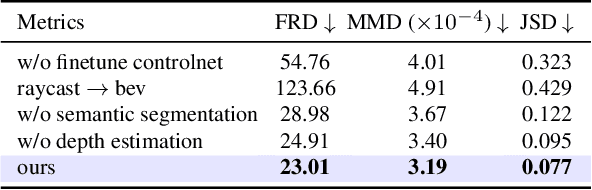
Generating realistic and diverse LiDAR point clouds is crucial for autonomous driving simulation. Although previous methods achieve LiDAR point cloud generation from user inputs, they struggle to attain high-quality results while enabling versatile controllability, due to the imbalance between the complex distribution of LiDAR point clouds and the simple control signals. To address the limitation, we propose LiDARDraft, which utilizes the 3D layout to build a bridge between versatile conditional signals and LiDAR point clouds. The 3D layout can be trivially generated from various user inputs such as textual descriptions and images. Specifically, we represent text, images, and point clouds as unified 3D layouts, which are further transformed into semantic and depth control signals. Then, we employ a rangemap-based ControlNet to guide LiDAR point cloud generation. This pixel-level alignment approach demonstrates excellent performance in controllable LiDAR point clouds generation, enabling "simulation from scratch", allowing self-driving environments to be created from arbitrary textual descriptions, images and sketches.
Vision-Centric Activation and Coordination for Multimodal Large Language Models
Oct 16, 2025Multimodal large language models (MLLMs) integrate image features from visual encoders with LLMs, demonstrating advanced comprehension capabilities. However, mainstream MLLMs are solely supervised by the next-token prediction of textual tokens, neglecting critical vision-centric information essential for analytical abilities. To track this dilemma, we introduce VaCo, which optimizes MLLM representations through Vision-Centric activation and Coordination from multiple vision foundation models (VFMs). VaCo introduces visual discriminative alignment to integrate task-aware perceptual features extracted from VFMs, thereby unifying the optimization of both textual and visual outputs in MLLMs. Specifically, we incorporate the learnable Modular Task Queries (MTQs) and Visual Alignment Layers (VALs) into MLLMs, activating specific visual signals under the supervision of diverse VFMs. To coordinate representation conflicts across VFMs, the crafted Token Gateway Mask (TGM) restricts the information flow among multiple groups of MTQs. Extensive experiments demonstrate that VaCo significantly improves the performance of different MLLMs on various benchmarks, showcasing its superior capabilities in visual comprehension.
UrbanCraft: Urban View Extrapolation via Hierarchical Sem-Geometric Priors
May 29, 2025

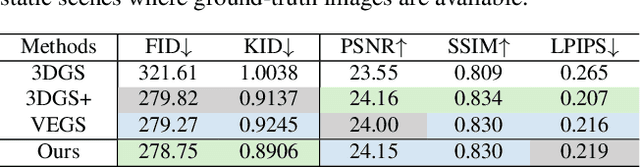
Existing neural rendering-based urban scene reconstruction methods mainly focus on the Interpolated View Synthesis (IVS) setting that synthesizes from views close to training camera trajectory. However, IVS can not guarantee the on-par performance of the novel view outside the training camera distribution (\textit{e.g.}, looking left, right, or downwards), which limits the generalizability of the urban reconstruction application. Previous methods have optimized it via image diffusion, but they fail to handle text-ambiguous or large unseen view angles due to coarse-grained control of text-only diffusion. In this paper, we design UrbanCraft, which surmounts the Extrapolated View Synthesis (EVS) problem using hierarchical sem-geometric representations serving as additional priors. Specifically, we leverage the partially observable scene to reconstruct coarse semantic and geometric primitives, establishing a coarse scene-level prior through an occupancy grid as the base representation. Additionally, we incorporate fine instance-level priors from 3D bounding boxes to enhance object-level details and spatial relationships. Building on this, we propose the \textbf{H}ierarchical \textbf{S}emantic-Geometric-\textbf{G}uided Variational Score Distillation (HSG-VSD), which integrates semantic and geometric constraints from pretrained UrbanCraft2D into the score distillation sampling process, forcing the distribution to be consistent with the observable scene. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS problem.
R2LDM: An Efficient 4D Radar Super-Resolution Framework Leveraging Diffusion Model
Mar 21, 2025We introduce R2LDM, an innovative approach for generating dense and accurate 4D radar point clouds, guided by corresponding LiDAR point clouds. Instead of utilizing range images or bird's eye view (BEV) images, we represent both LiDAR and 4D radar point clouds using voxel features, which more effectively capture 3D shape information. Subsequently, we propose the Latent Voxel Diffusion Model (LVDM), which performs the diffusion process in the latent space. Additionally, a novel Latent Point Cloud Reconstruction (LPCR) module is utilized to reconstruct point clouds from high-dimensional latent voxel features. As a result, R2LDM effectively generates LiDAR-like point clouds from paired raw radar data. We evaluate our approach on two different datasets, and the experimental results demonstrate that our model achieves 6- to 10-fold densification of radar point clouds, outperforming state-of-the-art baselines in 4D radar point cloud super-resolution. Furthermore, the enhanced radar point clouds generated by our method significantly improve downstream tasks, achieving up to 31.7% improvement in point cloud registration recall rate and 24.9% improvement in object detection accuracy.
Range and Bird's Eye View Fused Cross-Modal Visual Place Recognition
Feb 17, 2025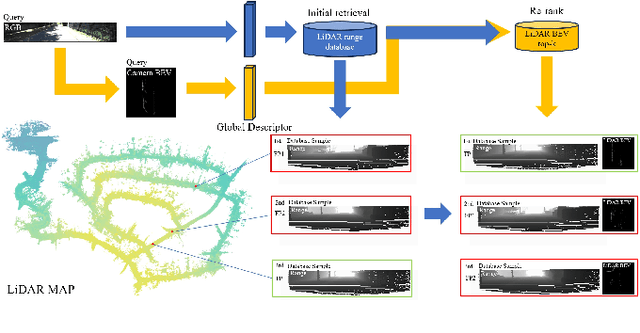
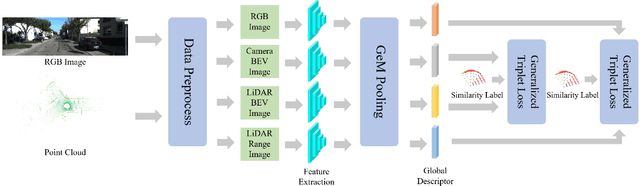
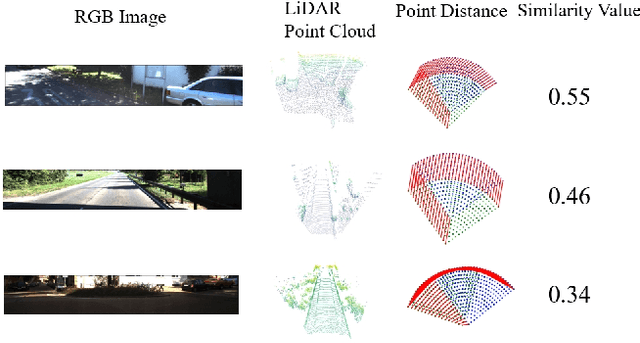
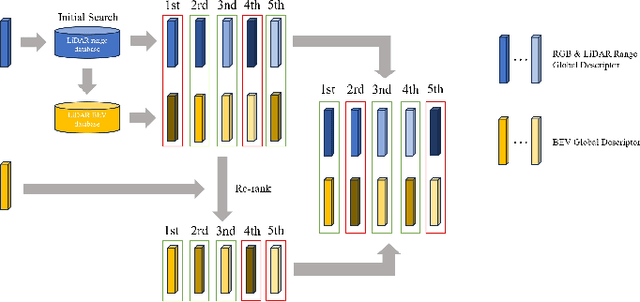
Image-to-point cloud cross-modal Visual Place Recognition (VPR) is a challenging task where the query is an RGB image, and the database samples are LiDAR point clouds. Compared to single-modal VPR, this approach benefits from the widespread availability of RGB cameras and the robustness of point clouds in providing accurate spatial geometry and distance information. However, current methods rely on intermediate modalities that capture either the vertical or horizontal field of view, limiting their ability to fully exploit the complementary information from both sensors. In this work, we propose an innovative initial retrieval + re-rank method that effectively combines information from range (or RGB) images and Bird's Eye View (BEV) images. Our approach relies solely on a computationally efficient global descriptor similarity search process to achieve re-ranking. Additionally, we introduce a novel similarity label supervision technique to maximize the utility of limited training data. Specifically, we employ points average distance to approximate appearance similarity and incorporate an adaptive margin, based on similarity differences, into the vanilla triplet loss. Experimental results on the KITTI dataset demonstrate that our method significantly outperforms state-of-the-art approaches.
Benchmarking Large Vision-Language Models via Directed Scene Graph for Comprehensive Image Captioning
Dec 12, 2024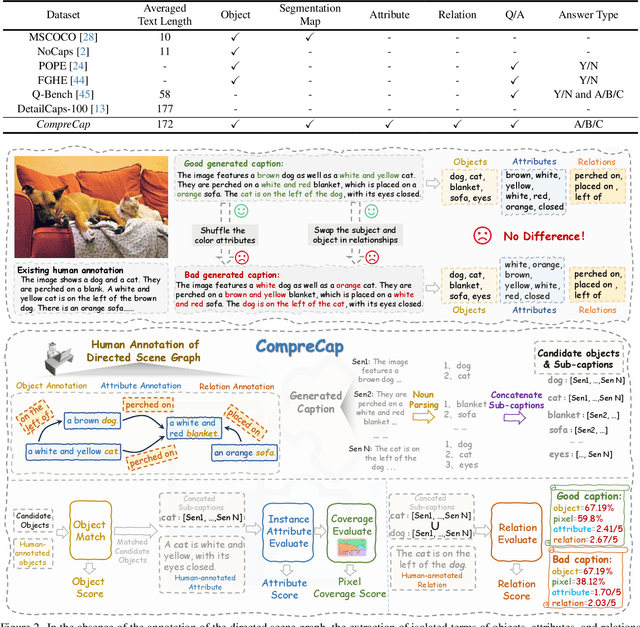
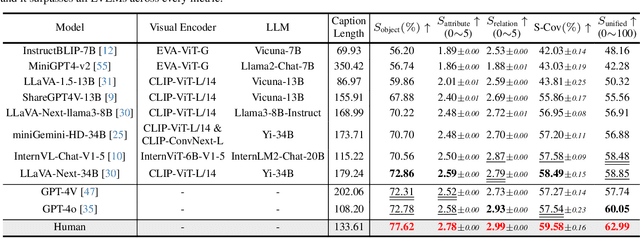

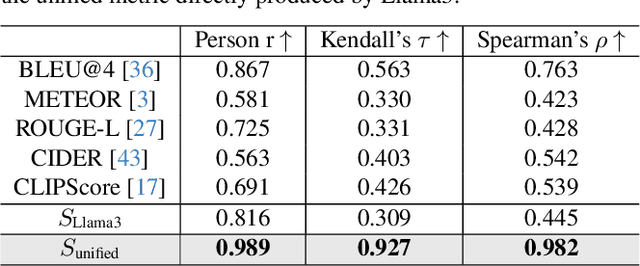
Generating detailed captions comprehending text-rich visual content in images has received growing attention for Large Vision-Language Models (LVLMs). However, few studies have developed benchmarks specifically tailored for detailed captions to measure their accuracy and comprehensiveness. In this paper, we introduce a detailed caption benchmark, termed as CompreCap, to evaluate the visual context from a directed scene graph view. Concretely, we first manually segment the image into semantically meaningful regions (i.e., semantic segmentation mask) according to common-object vocabulary, while also distinguishing attributes of objects within all those regions. Then directional relation labels of these objects are annotated to compose a directed scene graph that can well encode rich compositional information of the image. Based on our directed scene graph, we develop a pipeline to assess the generated detailed captions from LVLMs on multiple levels, including the object-level coverage, the accuracy of attribute descriptions, the score of key relationships, etc. Experimental results on the CompreCap dataset confirm that our evaluation method aligns closely with human evaluation scores across LVLMs.