 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDARDraft: Generating LiDAR Point Cloud from Versatile Inputs
Dec 23, 2025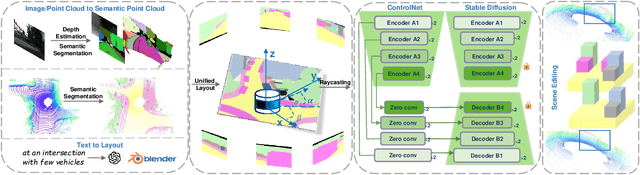
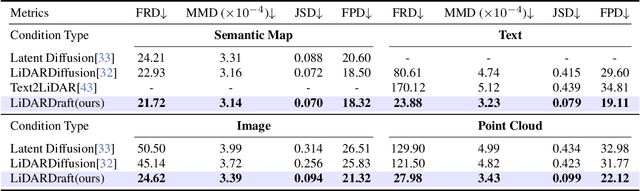
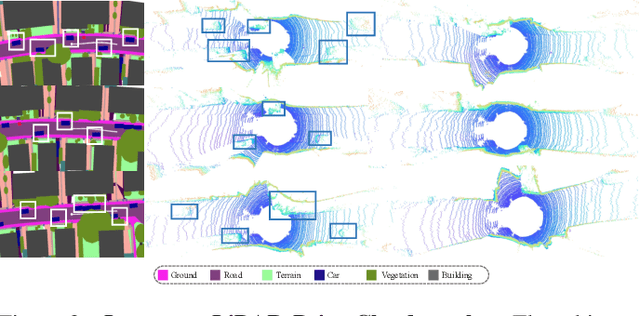
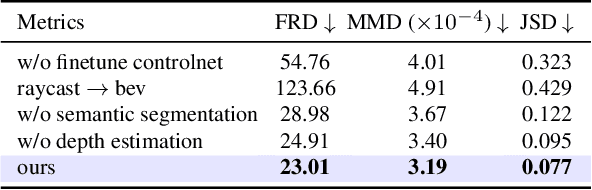
Generating realistic and diverse LiDAR point clouds is crucial for autonomous driving simulation. Although previous methods achieve LiDAR point cloud generation from user inputs, they struggle to attain high-quality results while enabling versatile controllability, due to the imbalance between the complex distribution of LiDAR point clouds and the simple control signals. To address the limitation, we propose LiDARDraft, which utilizes the 3D layout to build a bridge between versatile conditional signals and LiDAR point clouds. The 3D layout can be trivially generated from various user inputs such as textual descriptions and images. Specifically, we represent text, images, and point clouds as unified 3D layouts, which are further transformed into semantic and depth control signals. Then, we employ a rangemap-based ControlNet to guide LiDAR point cloud generation. This pixel-level alignment approach demonstrates excellent performance in controllable LiDAR point clouds generation, enabling "simulation from scratch", allowing self-driving environments to be created from arbitrary textual descriptions, images and sketches.
GeoNLF: Geometry guided Pose-Free Neural LiDAR Fields
Jul 08, 2024Although recent efforts have extended Neural Radiance Fields (NeRF) into LiDAR point cloud synthesis, the majority of existing works exhibit a strong dependence on precomputed poses. However, point cloud registration methods struggle to achieve precise global pose estimation, whereas previous pose-free NeRFs overlook geometric consistency in global reconstruction. In light of this, we explore the geometric insights of point clouds, which provide explicit registration priors for reconstruction. Based on this, we propose Geometry guided Neural LiDAR Fields(GeoNLF), a hybrid framework performing alternately global neural reconstruction and pure geometric pose optimization. Furthermore, NeRFs tend to overfit individual frames and easily get stuck in local minima under sparse-view inputs. To tackle this issue, we develop a selective-reweighting strategy and introduce geometric constraints for robust optimization. Extensive experiments on NuScenes and KITTI-360 datasets demonstrate the superiority of GeoNLF in both novel view synthesis and multi-view registration of low-frequency large-scale point clouds.
RCDN: Towards Robust Camera-Insensitivity Collaborative Perception via Dynamic Feature-based 3D Neural Modeling
May 27, 2024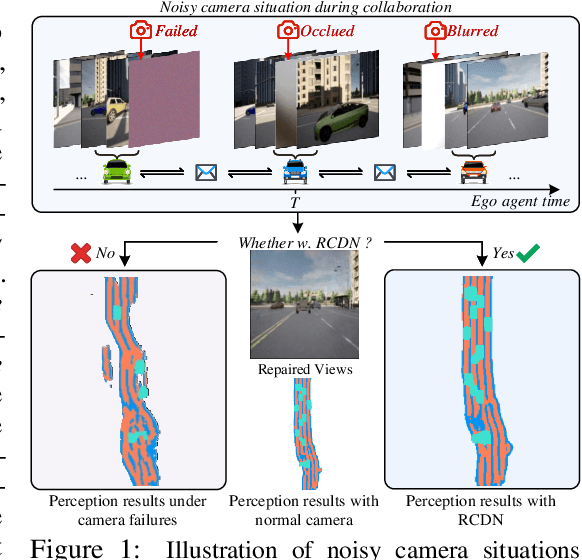
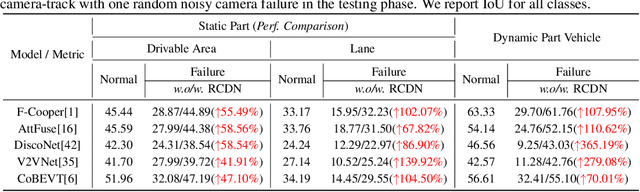
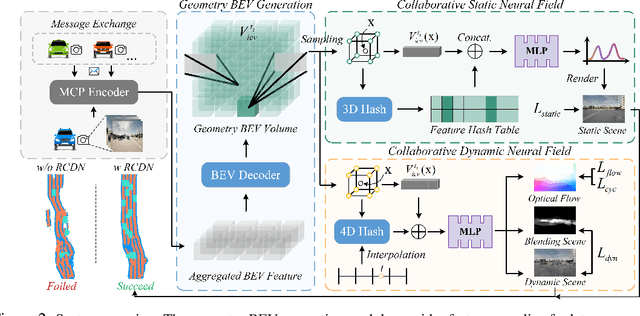
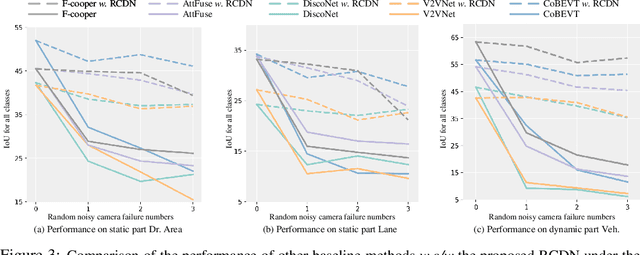
Collaborative perception is dedicated to tackling the constraints of single-agent perception, such as occlusions, based on the multiple agents' multi-view sensor inputs. However, most existing works assume an ideal condition that all agents' multi-view cameras are continuously available. In reality, cameras may be highly noisy, obscured or even failed during the collaboration. In this work, we introduce a new robust camera-insensitivity problem: how to overcome the issues caused by the failed camera perspectives, while stabilizing high collaborative performance with low calibration cost? To address above problems, we propose RCDN, a Robust Camera-insensitivity collaborative perception with a novel Dynamic feature-based 3D Neural modeling mechanism. The key intuition of RCDN is to construct collaborative neural rendering field representations to recover failed perceptual messages sent by multiple agents. To better model collaborative neural rendering field, RCDN first establishes a geometry BEV feature based time-invariant static field with other agents via fast hash grid modeling. Based on the static background field, the proposed time-varying dynamic field can model corresponding motion vectors for foregrounds with appropriate positions. To validate RCDN, we create OPV2V-N, a new large-scale dataset with manual labelling under different camera failed scenarios. Extensive experiments conducted on OPV2V-N show that RCDN can be ported to other baselines and improve their robustness in extreme camera-insensitivity settings. Our code and datasets will be available soon.
LiDAR4D: Dynamic Neural Fields for Novel Space-time View LiDAR Synthesis
Apr 03, 2024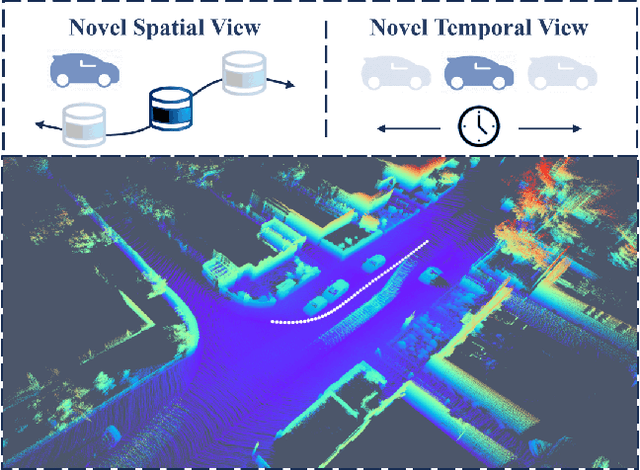
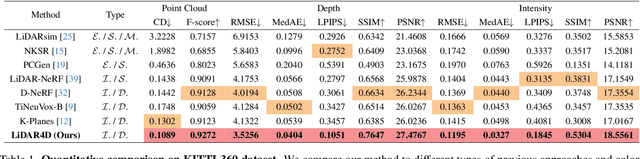
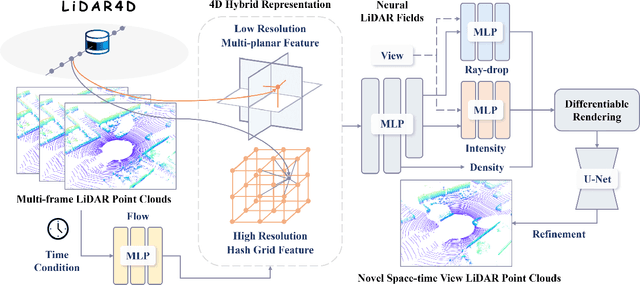
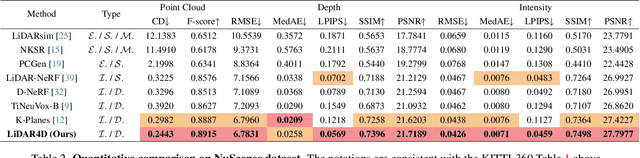
Although neural radiance fields (NeRFs) have achieved triumphs in image novel view synthesis (NVS), LiDAR NVS remains largely unexplored. Previous LiDAR NVS methods employ a simple shift from image NVS methods while ignoring the dynamic nature and the large-scale reconstruction problem of LiDAR point clouds. In light of this, we propose LiDAR4D, a differentiable LiDAR-only framework for novel space-time LiDAR view synthesis. In consideration of the sparsity and large-scale characteristics, we design a 4D hybrid representation combined with multi-planar and grid features to achieve effective reconstruction in a coarse-to-fine manner. Furthermore, we introduce geometric constraints derived from point clouds to improve temporal consistency. For the realistic synthesis of LiDAR point clouds, we incorporate the global optimization of ray-drop probability to preserve cross-region patterns. Extensive experiments on KITTI-360 and NuScenes datasets demonstrate the superiority of our method in accomplishing geometry-aware and time-consistent dynamic reconstruction. Codes are available at https://github.com/ispc-lab/LiDAR4D.
TSNet:A Two-stage Network for Image Dehazing with Multi-scale Fusion and Adaptive Learning
Apr 03, 2024



Image dehazing has been a popular topic of research for a long time. Previous deep learning-based image dehazing methods have failed to achieve satisfactory dehazing effects on both synthetic datasets and real-world datasets, exhibiting poor generalization. Moreover, single-stage networks often result in many regions with artifacts and color distortion in output images. To address these issues, this paper proposes a two-stage image dehazing network called TSNet, mainly consisting of the multi-scale fusion module (MSFM) and the adaptive learning module (ALM). Specifically, MSFM and ALM enhance the generalization of TSNet. The MSFM can obtain large receptive fields at multiple scales and integrate features at different frequencies to reduce the differences between inputs and learning objectives. The ALM can actively learn of regions of interest in images and restore texture details more effectively. Additionally, TSNet is designed as a two-stage network, where the first-stage network performs image dehazing, and the second-stage network is employed to improve issues such as artifacts and color distortion present in the results of the first-stage network. We also change the learning objective from ground truth images to opposite fog maps, which improves the learning efficiency of TSNet. Extensive experiments demonstrate that TSNet exhibits superior dehazing performance on both synthetic and real-world datasets compared to previous state-of-the-art methods.
NeuralPCI: Spatio-temporal Neural Field for 3D Point Cloud Multi-frame Non-linear Interpolation
Mar 27, 2023In recent years, there has been a significant increase in focus on the interpolation task of computer vision. Despite the tremendous advancement of video interpolation, point cloud interpolation remains insufficiently explored. Meanwhile, the existence of numerous nonlinear large motions in real-world scenarios makes the point cloud interpolation task more challenging. In light of these issues, we present NeuralPCI: an end-to-end 4D spatio-temporal Neural field for 3D Point Cloud Interpolation, which implicitly integrates multi-frame information to handle nonlinear large motions for both indoor and outdoor scenarios. Furthermore, we construct a new multi-frame point cloud interpolation dataset called NL-Drive for large nonlinear motions in autonomous driving scenes to better demonstrate the superiority of our method. Ultimately, NeuralPCI achieves state-of-the-art performance on both DHB (Dynamic Human Bodies) and NL-Drive datasets. Beyond the interpolation task, our method can be naturally extended to point cloud extrapolation, morphing, and auto-labeling, which indicates its substantial potential in other domains. Codes are available at https://github.com/ispc-lab/NeuralPCI.
PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark
Apr 12, 2022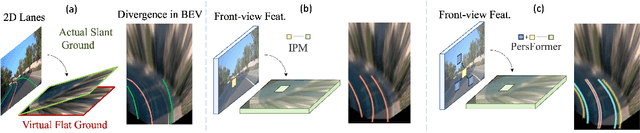
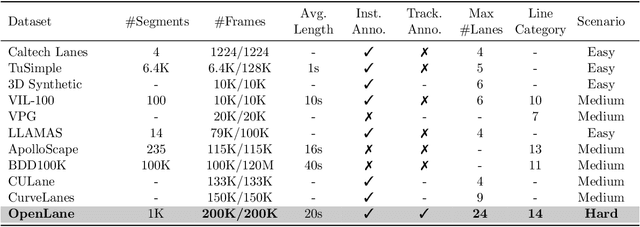
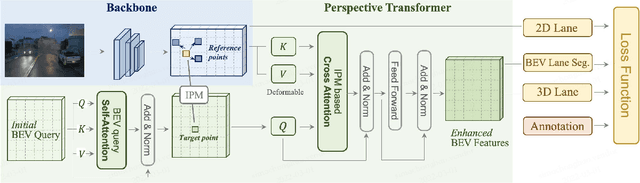

Methods for 3D lane detection have been recently proposed to address the issue of inaccurate lane layouts in many autonomous driving scenarios (uphill/downhill, bump, etc.). Previous work struggled in complex cases due to their simple designs of the spatial transformation between front view and bird's eye view (BEV) and the lack of a realistic dataset. Towards these issues, we present PersFormer: an end-to-end monocular 3D lane detector with a novel Transformer-based spatial feature transformation module. Our model generates BEV features by attending to related front-view local regions with camera parameters as a reference. PersFormer adopts a unified 2D/3D anchor design and an auxiliary task to detect 2D/3D lanes simultaneously, enhancing the feature consistency and sharing the benefits of multi-task learning. Moreover, we release one of the first large-scale real-world 3D lane datasets, which is called OpenLane, with high-quality annotation and scenario diversity. OpenLane contains 200,000 frames, over 880,000 instance-level lanes, 14 lane categories, along with scene tags and the closed-in-path object annotations to encourage the development of lane detection and more industrial-related autonomous driving methods. We show that PersFormer significantly outperforms competitive baselines in the 3D lane detection task on our new OpenLane dataset as well as Apollo 3D Lane Synthetic dataset, and is also on par with state-of-the-art algorithms in the 2D task on OpenLane. The project page is available at https://github.com/OpenPerceptionX/PersFormer_3DLane and OpenLane dataset is provided at https://github.com/OpenPerceptionX/OpenLane.