 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology Reasoning for Driving Scenes
Apr 11, 2023Understanding the road genome is essential to realize autonomous driving. This highly intelligent problem contains two aspects - the connection relationship of lanes, and the assignment relationship between lanes and traffic elements, where a comprehensive topology reasoning method is vacant. On one hand, previous map learning techniques struggle in deriving lane connectivity with segmentation or laneline paradigms; or prior lane topology-oriented approaches focus on centerline detection and neglect the interaction modeling. On the other hand, the traffic element to lane assignment problem is limited in the image domain, leaving how to construct the correspondence from two views an unexplored challenge. To address these issues, we present TopoNet, the first end-to-end framework capable of abstracting traffic knowledge beyond conventional perception tasks. To capture the driving scene topology, we introduce three key designs: (1) an embedding module to incorporate semantic knowledge from 2D elements into a unified feature space; (2) a curated scene graph neural network to model relationships and enable feature interaction inside the network; (3) instead of transmitting messages arbitrarily, a scene knowledge graph is devised to differentiate prior knowledge from various types of the road genome. We evaluate TopoNet on the challenging scene understanding benchmark, OpenLane-V2, where our approach outperforms all previous works by a great margin on all perceptual and topological metrics. The code would be released soon.
3D Data Augmentation for Driving Scenes on Camera
Mar 18, 2023



Driving scenes are extremely diverse and complicated that it is impossible to collect all cases with human effort alone. While data augmentation is an effective technique to enrich the training data, existing methods for camera data in autonomous driving applications are confined to the 2D image plane, which may not optimally increase data diversity in 3D real-world scenarios. To this end, we propose a 3D data augmentation approach termed Drive-3DAug, aiming at augmenting the driving scenes on camera in the 3D space. We first utilize Neural Radiance Field (NeRF) to reconstruct the 3D models of background and foreground objects. Then, augmented driving scenes can be obtained by placing the 3D objects with adapted location and orientation at the pre-defined valid region of backgrounds. As such, the training database could be effectively scaled up. However, the 3D object modeling is constrained to the image quality and the limited viewpoints. To overcome these problems, we modify the original NeRF by introducing a geometric rectified loss and a symmetric-aware training strategy. We evaluate our method for the camera-only monocular 3D detection task on the Waymo and nuScences datasets. The proposed data augmentation approach contributes to a gain of 1.7% and 1.4% in terms of detection accuracy, on Waymo and nuScences respectively. Furthermore, the constructed 3D models serve as digital driving assets and could be recycled for different detectors or other 3D perception tasks.
Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022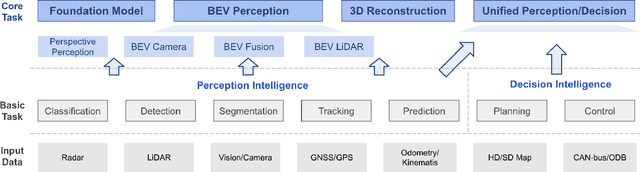
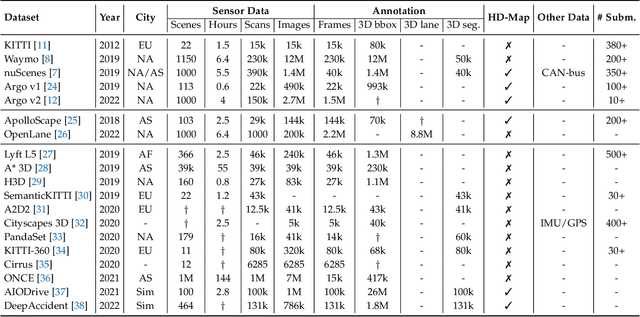
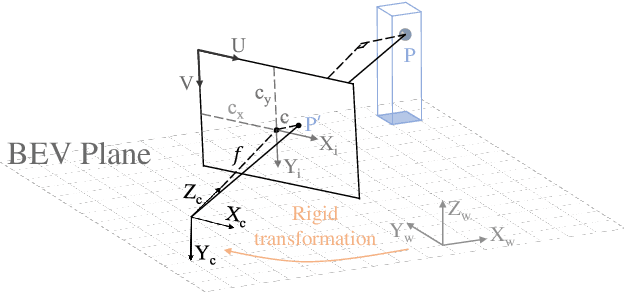
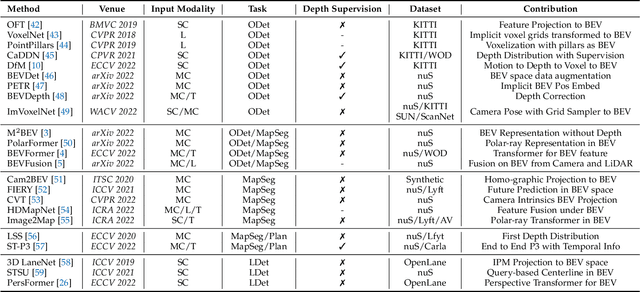
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.
PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark
Apr 12, 2022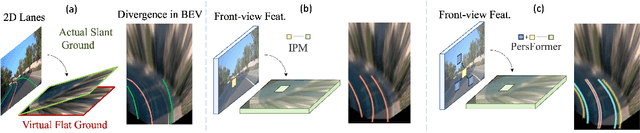
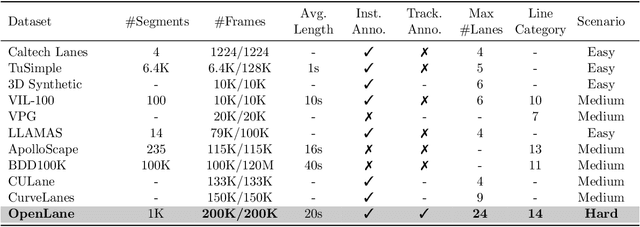
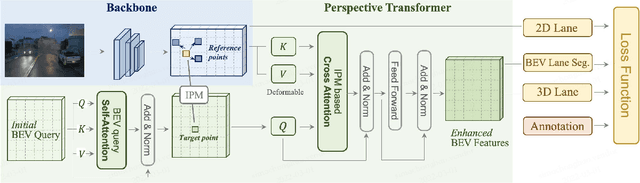

Methods for 3D lane detection have been recently proposed to address the issue of inaccurate lane layouts in many autonomous driving scenarios (uphill/downhill, bump, etc.). Previous work struggled in complex cases due to their simple designs of the spatial transformation between front view and bird's eye view (BEV) and the lack of a realistic dataset. Towards these issues, we present PersFormer: an end-to-end monocular 3D lane detector with a novel Transformer-based spatial feature transformation module. Our model generates BEV features by attending to related front-view local regions with camera parameters as a reference. PersFormer adopts a unified 2D/3D anchor design and an auxiliary task to detect 2D/3D lanes simultaneously, enhancing the feature consistency and sharing the benefits of multi-task learning. Moreover, we release one of the first large-scale real-world 3D lane datasets, which is called OpenLane, with high-quality annotation and scenario diversity. OpenLane contains 200,000 frames, over 880,000 instance-level lanes, 14 lane categories, along with scene tags and the closed-in-path object annotations to encourage the development of lane detection and more industrial-related autonomous driving methods. We show that PersFormer significantly outperforms competitive baselines in the 3D lane detection task on our new OpenLane dataset as well as Apollo 3D Lane Synthetic dataset, and is also on par with state-of-the-art algorithms in the 2D task on OpenLane. The project page is available at https://github.com/OpenPerceptionX/PersFormer_3DLane and OpenLane dataset is provided at https://github.com/OpenPerceptionX/OpenLane.