 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$χ_{0}$: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
Feb 09, 2026High-reliability long-horizon robotic manipulation has traditionally relied on large-scale data and compute to understand complex real-world dynamics. However, we identify that the primary bottleneck to real-world robustness is not resource scale alone, but the distributional shift among the human demonstration distribution, the inductive bias learned by the policy, and the test-time execution distribution -- a systematic inconsistency that causes compounding errors in multi-stage tasks. To mitigate these inconsistencies, we propose $χ_{0}$, a resource-efficient framework with effective modules designated to achieve production-level robustness in robotic manipulation. Our approach builds off three technical pillars: (i) Model Arithmetic, a weight-space merging strategy that efficiently soaks up diverse distributions of different demonstrations, varying from object appearance to state variations; (ii) Stage Advantage, a stage-aware advantage estimator that provides stable, dense progress signals, overcoming the numerical instability of prior non-stage approaches; and (iii) Train-Deploy Alignment, which bridges the distribution gap via spatio-temporal augmentation, heuristic DAgger corrections, and temporal chunk-wise smoothing. $χ_{0}$ enables two sets of dual-arm robots to collaboratively orchestrate long-horizon garment manipulation, spanning tasks from flattening, folding, to hanging different clothes. Our method exhibits high-reliability autonomy; we are able to run the system from arbitrary initial state for consecutive 24 hours non-stop. Experiments validate that $χ_{0}$ surpasses the state-of-the-art $π_{0.5}$ in success rate by nearly 250%, with only 20-hour data and 8 A100 GPUs. Code, data and models will be released to facilitate the community.
ETA: Efficiency through Thinking Ahead, A Dual Approach to Self-Driving with Large Models
Jun 09, 2025How can we benefit from large models without sacrificing inference speed, a common dilemma in self-driving systems? A prevalent solution is a dual-system architecture, employing a small model for rapid, reactive decisions and a larger model for slower but more informative analyses. Existing dual-system designs often implement parallel architectures where inference is either directly conducted using the large model at each current frame or retrieved from previously stored inference results. However, these works still struggle to enable large models for a timely response to every online frame. Our key insight is to shift intensive computations of the current frame to previous time steps and perform a batch inference of multiple time steps to make large models respond promptly to each time step. To achieve the shifting, we introduce Efficiency through Thinking Ahead (ETA), an asynchronous system designed to: (1) propagate informative features from the past to the current frame using future predictions from the large model, (2) extract current frame features using a small model for real-time responsiveness, and (3) integrate these dual features via an action mask mechanism that emphasizes action-critical image regions. Evaluated on the Bench2Drive CARLA Leaderboard-v2 benchmark, ETA advances state-of-the-art performance by 8% with a driving score of 69.53 while maintaining a near-real-time inference speed at 50 ms.
Centaur: Robust End-to-End Autonomous Driving with Test-Time Training
Mar 14, 2025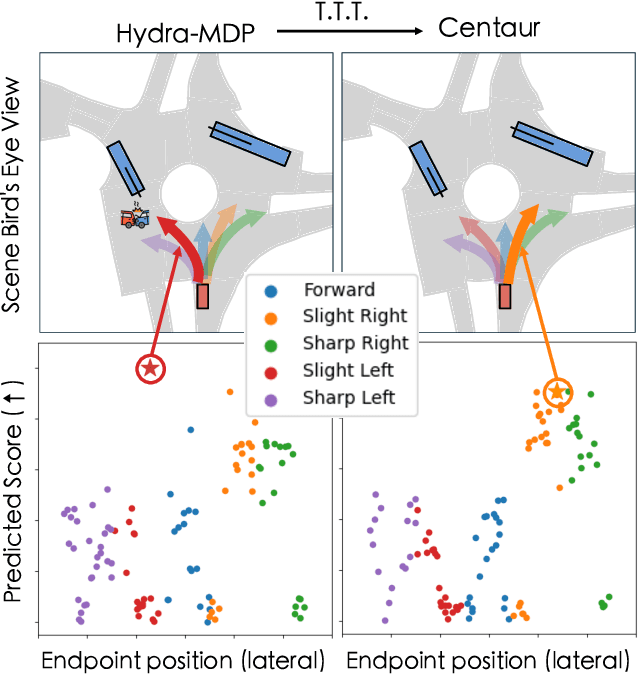



How can we rely on an end-to-end autonomous vehicle's complex decision-making system during deployment? One common solution is to have a ``fallback layer'' that checks the planned trajectory for rule violations and replaces it with a pre-defined safe action if necessary. Another approach involves adjusting the planner's decisions to minimize a pre-defined ``cost function'' using additional system predictions such as road layouts and detected obstacles. However, these pre-programmed rules or cost functions cannot learn and improve with new training data, often resulting in overly conservative behaviors. In this work, we propose Centaur (Cluster Entropy for Test-time trAining using Uncertainty) which updates a planner's behavior via test-time training, without relying on hand-engineered rules or cost functions. Instead, we measure and minimize the uncertainty in the planner's decisions. For this, we develop a novel uncertainty measure, called Cluster Entropy, which is simple, interpretable, and compatible with state-of-the-art planning algorithms. Using data collected at prior test-time time-steps, we perform an update to the model's parameters using a gradient that minimizes the Cluster Entropy. With only this sole gradient update prior to inference, Centaur exhibits significant improvements, ranking first on the navtest leaderboard with notable gains in safety-critical metrics such as time to collision. To provide detailed insights on a per-scenario basis, we also introduce navsafe, a challenging new benchmark, which highlights previously undiscovered failure modes of driving models.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
Jan 07, 2025



Recent advancements in Vision-Language Models (VLMs) have sparked interest in their use for autonomous driving, particularly in generating interpretable driving decisions through natural language. However, the assumption that VLMs inherently provide visually grounded, reliable, and interpretable explanations for driving remains largely unexamined. To address this gap, we introduce DriveBench, a benchmark dataset designed to evaluate VLM reliability across 17 settings (clean, corrupted, and text-only inputs), encompassing 19,200 frames, 20,498 question-answer pairs, three question types, four mainstream driving tasks, and a total of 12 popular VLMs. Our findings reveal that VLMs often generate plausible responses derived from general knowledge or textual cues rather than true visual grounding, especially under degraded or missing visual inputs. This behavior, concealed by dataset imbalances and insufficient evaluation metrics, poses significant risks in safety-critical scenarios like autonomous driving. We further observe that VLMs struggle with multi-modal reasoning and display heightened sensitivity to input corruptions, leading to inconsistencies in performance. To address these challenges, we propose refined evaluation metrics that prioritize robust visual grounding and multi-modal understanding. Additionally, we highlight the potential of leveraging VLMs' awareness of corruptions to enhance their reliability, offering a roadmap for developing more trustworthy and interpretable decision-making systems in real-world autonomous driving contexts. The benchmark toolkit is publicly accessible.
Hint-AD: Holistically Aligned Interpretability in End-to-End Autonomous Driving
Sep 10, 2024
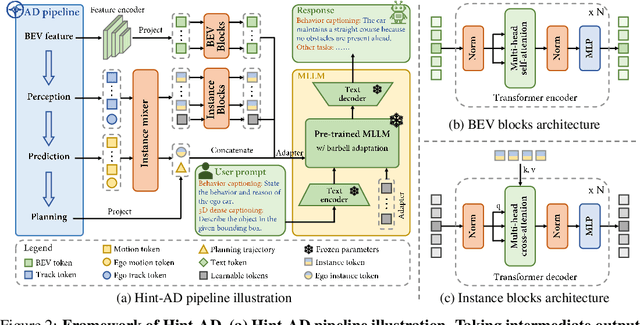

End-to-end architectures in autonomous driving (AD) face a significant challenge in interpretability, impeding human-AI trust. Human-friendly natural language has been explored for tasks such as driving explanation and 3D captioning. However, previous works primarily focused on the paradigm of declarative interpretability, where the natural language interpretations are not grounded in the intermediate outputs of AD systems, making the interpretations only declarative. In contrast, aligned interpretability establishes a connection between language and the intermediate outputs of AD systems. Here we introduce Hint-AD, an integrated AD-language system that generates language aligned with the holistic perception-prediction-planning outputs of the AD model. By incorporating the intermediate outputs and a holistic token mixer sub-network for effective feature adaptation, Hint-AD achieves desirable accuracy, achieving state-of-the-art results in driving language tasks including driving explanation, 3D dense captioning, and command prediction. To facilitate further study on driving explanation task on nuScenes, we also introduce a human-labeled dataset, Nu-X. Codes, dataset, and models will be publicly available.
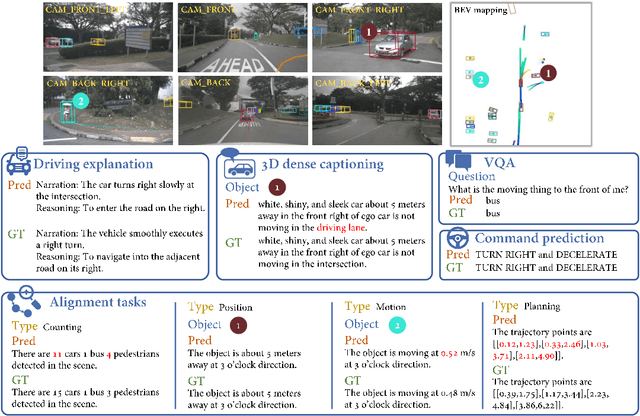
DriveLM: Driving with Graph Visual Question Answering
Dec 21, 2023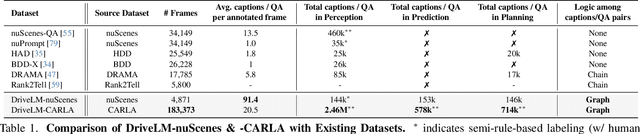
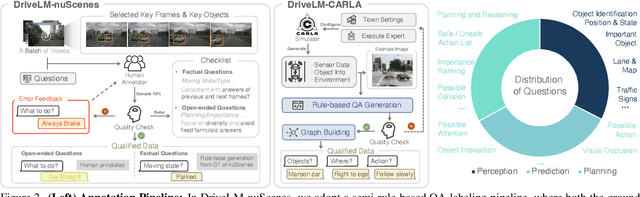
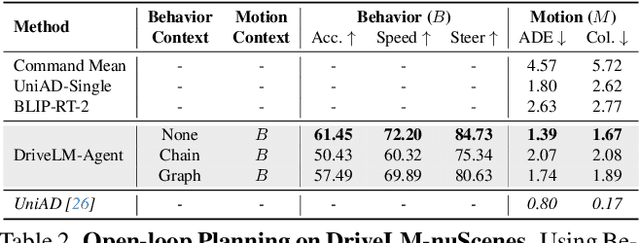
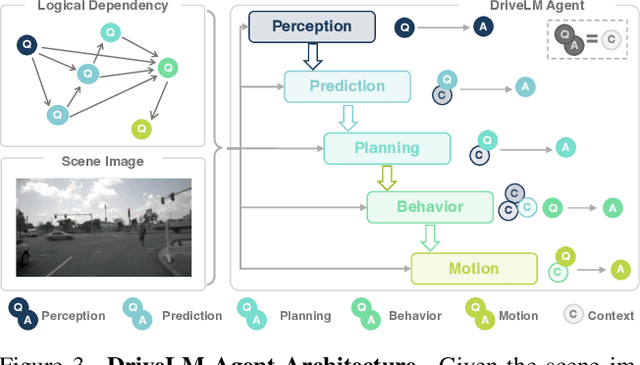
We study how vision-language models (VLMs) trained on web-scale data can be integrated into end-to-end driving systems to boost generalization and enable interactivity with human users. While recent approaches adapt VLMs to driving via single-round visual question answering (VQA), human drivers reason about decisions in multiple steps. Starting from the localization of key objects, humans estimate object interactions before taking actions. The key insight is that with our proposed task, Graph VQA, where we model graph-structured reasoning through perception, prediction and planning question-answer pairs, we obtain a suitable proxy task to mimic the human reasoning process. We instantiate datasets (DriveLM-Data) built upon nuScenes and CARLA, and propose a VLM-based baseline approach (DriveLM-Agent) for jointly performing Graph VQA and end-to-end driving. The experiments demonstrate that Graph VQA provides a simple, principled framework for reasoning about a driving scene, and DriveLM-Data provides a challenging benchmark for this task. Our DriveLM-Agent baseline performs end-to-end autonomous driving competitively in comparison to state-of-the-art driving-specific architectures. Notably, its benefits are pronounced when it is evaluated zero-shot on unseen objects or sensor configurations. We hope this work can be the starting point to shed new light on how to apply VLMs for autonomous driving. To facilitate future research, all code, data, and models are available to the public.
Leveraging Vision-Centric Multi-Modal Expertise for 3D Object Detection
Oct 24, 2023Current research is primarily dedicated to advancing the accuracy of camera-only 3D object detectors (apprentice) through the knowledge transferred from LiDAR- or multi-modal-based counterparts (expert). However, the presence of the domain gap between LiDAR and camera features, coupled with the inherent incompatibility in temporal fusion, significantly hinders the effectiveness of distillation-based enhancements for apprentices. Motivated by the success of uni-modal distillation, an apprentice-friendly expert model would predominantly rely on camera features, while still achieving comparable performance to multi-modal models. To this end, we introduce VCD, a framework to improve the camera-only apprentice model, including an apprentice-friendly multi-modal expert and temporal-fusion-friendly distillation supervision. The multi-modal expert VCD-E adopts an identical structure as that of the camera-only apprentice in order to alleviate the feature disparity, and leverages LiDAR input as a depth prior to reconstruct the 3D scene, achieving the performance on par with other heterogeneous multi-modal experts. Additionally, a fine-grained trajectory-based distillation module is introduced with the purpose of individually rectifying the motion misalignment for each object in the scene. With those improvements, our camera-only apprentice VCD-A sets new state-of-the-art on nuScenes with a score of 63.1% NDS.
Scene as Occupancy
Jun 06, 2023Human driver can easily describe the complex traffic scene by visual system. Such an ability of precise perception is essential for driver's planning. To achieve this, a geometry-aware representation that quantizes the physical 3D scene into structured grid map with semantic labels per cell, termed as 3D Occupancy, would be desirable. Compared to the form of bounding box, a key insight behind occupancy is that it could capture the fine-grained details of critical obstacles in the scene, and thereby facilitate subsequent tasks. Prior or concurrent literature mainly concentrate on a single scene completion task, where we might argue that the potential of this occupancy representation might obsess broader impact. In this paper, we propose OccNet, a multi-view vision-centric pipeline with a cascade and temporal voxel decoder to reconstruct 3D occupancy. At the core of OccNet is a general occupancy embedding to represent 3D physical world. Such a descriptor could be applied towards a wide span of driving tasks, including detection, segmentation and planning. To validate the effectiveness of this new representation and our proposed algorithm, we propose OpenOcc, the first dense high-quality 3D occupancy benchmark built on top of nuScenes. Empirical experiments show that there are evident performance gain across multiple tasks, e.g., motion planning could witness a collision rate reduction by 15%-58%, demonstrating the superiority of our method.
Road Genome: A Topology Reasoning Benchmark for Scene Understanding in Autonomous Driving
Apr 20, 2023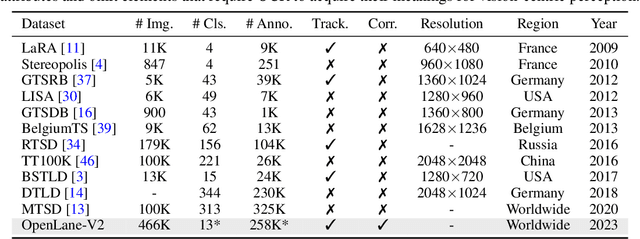
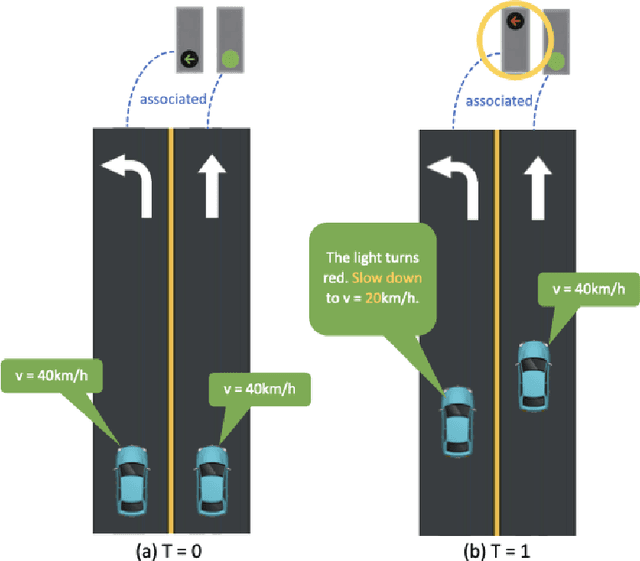
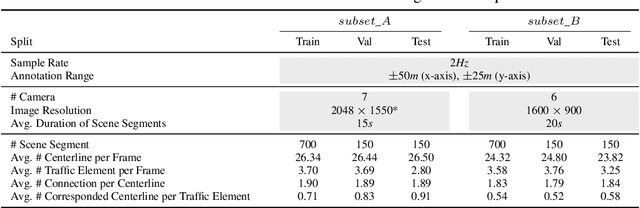
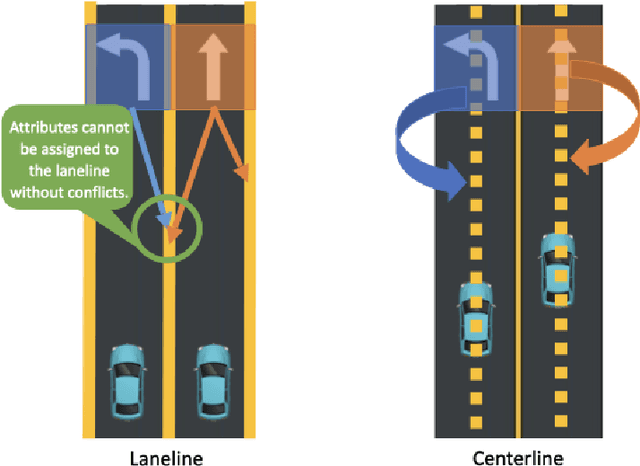
Understanding the complex traffic environment is crucial for self-driving vehicles. Existing benchmarks in autonomous driving mainly cast scene understanding as perception problems, e.g., perceiving lanelines with vanilla detection or segmentation methods. As such, we argue that the perception pipeline provides limited information for autonomous vehicles to drive in the right way, especially without the aid of high-definition (HD) map. For instance, following the wrong traffic signal at a complicated crossroad would lead to a catastrophic incident. By introducing Road Genome (OpenLane-V2), we intend to shift the community's attention and take a step further beyond perception - to the task of topology reasoning for scene structure. The goal of Road Genome is to understand the scene structure by investigating the relationship of perceived entities among traffic elements and lanes. Built on top of prevailing datasets, the newly minted benchmark comprises 2,000 sequences of multi-view images captured from diverse real-world scenarios. We annotate data with high-quality manual checks in the loop. Three subtasks compromise the gist of Road Genome, including the 3D lane detection inherited from OpenLane. We have/will host Challenges in the upcoming future at top-tiered venues.