 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$χ_{0}$: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
Feb 09, 2026High-reliability long-horizon robotic manipulation has traditionally relied on large-scale data and compute to understand complex real-world dynamics. However, we identify that the primary bottleneck to real-world robustness is not resource scale alone, but the distributional shift among the human demonstration distribution, the inductive bias learned by the policy, and the test-time execution distribution -- a systematic inconsistency that causes compounding errors in multi-stage tasks. To mitigate these inconsistencies, we propose $χ_{0}$, a resource-efficient framework with effective modules designated to achieve production-level robustness in robotic manipulation. Our approach builds off three technical pillars: (i) Model Arithmetic, a weight-space merging strategy that efficiently soaks up diverse distributions of different demonstrations, varying from object appearance to state variations; (ii) Stage Advantage, a stage-aware advantage estimator that provides stable, dense progress signals, overcoming the numerical instability of prior non-stage approaches; and (iii) Train-Deploy Alignment, which bridges the distribution gap via spatio-temporal augmentation, heuristic DAgger corrections, and temporal chunk-wise smoothing. $χ_{0}$ enables two sets of dual-arm robots to collaboratively orchestrate long-horizon garment manipulation, spanning tasks from flattening, folding, to hanging different clothes. Our method exhibits high-reliability autonomy; we are able to run the system from arbitrary initial state for consecutive 24 hours non-stop. Experiments validate that $χ_{0}$ surpasses the state-of-the-art $π_{0.5}$ in success rate by nearly 250%, with only 20-hour data and 8 A100 GPUs. Code, data and models will be released to facilitate the community.
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
Mar 09, 2025We explore how scalable robot data can address real-world challenges for generalized robotic manipulation. Introducing AgiBot World, a large-scale platform comprising over 1 million trajectories across 217 tasks in five deployment scenarios, we achieve an order-of-magnitude increase in data scale compared to existing datasets. Accelerated by a standardized collection pipeline with human-in-the-loop verification, AgiBot World guarantees high-quality and diverse data distribution. It is extensible from grippers to dexterous hands and visuo-tactile sensors for fine-grained skill acquisition. Building on top of data, we introduce Genie Operator-1 (GO-1), a novel generalist policy that leverages latent action representations to maximize data utilization, demonstrating predictable performance scaling with increased data volume. Policies pre-trained on our dataset achieve an average performance improvement of 30% over those trained on Open X-Embodiment, both in in-domain and out-of-distribution scenarios. GO-1 exhibits exceptional capability in real-world dexterous and long-horizon tasks, achieving over 60% success rate on complex tasks and outperforming prior RDT approach by 32%. By open-sourcing the dataset, tools, and models, we aim to democratize access to large-scale, high-quality robot data, advancing the pursuit of scalable and general-purpose intelligence.
Open-sourced Data Ecosystem in Autonomous Driving: the Present and Future
Dec 06, 2023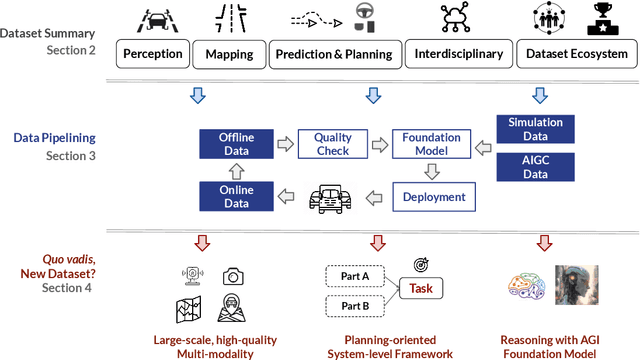
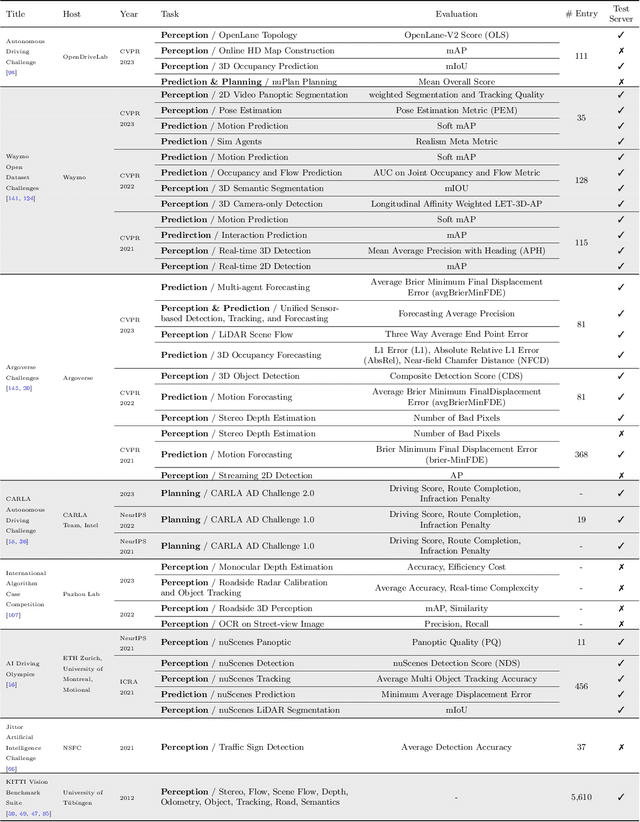
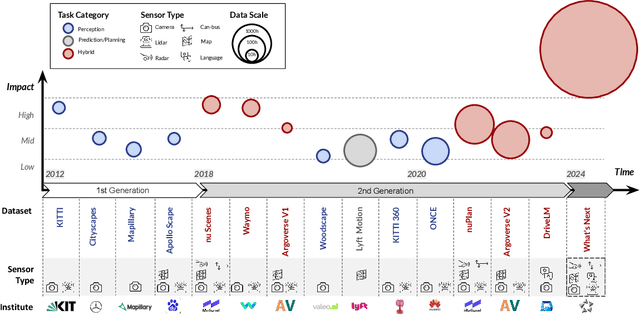
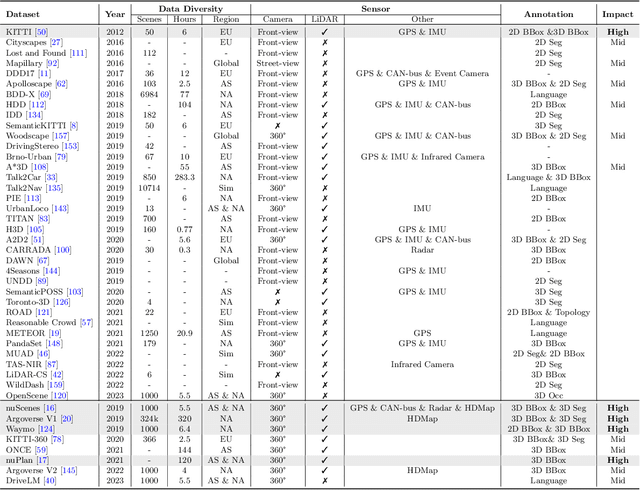
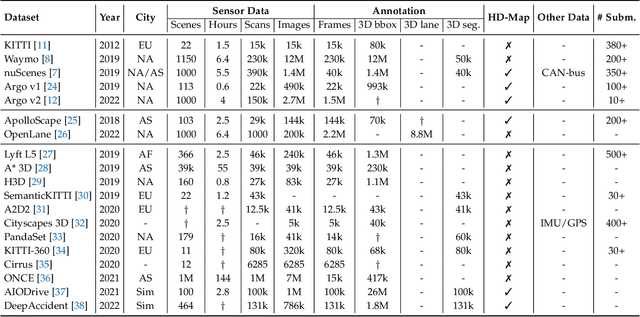
With the continuous maturation and application of autonomous driving technology, a systematic examination of open-source autonomous driving datasets becomes instrumental in fostering the robust evolution of the industry ecosystem. Current autonomous driving datasets can broadly be categorized into two generations. The first-generation autonomous driving datasets are characterized by relatively simpler sensor modalities, smaller data scale, and is limited to perception-level tasks. KITTI, introduced in 2012, serves as a prominent representative of this initial wave. In contrast, the second-generation datasets exhibit heightened complexity in sensor modalities, greater data scale and diversity, and an expansion of tasks from perception to encompass prediction and control. Leading examples of the second generation include nuScenes and Waymo, introduced around 2019. This comprehensive review, conducted in collaboration with esteemed colleagues from both academia and industry, systematically assesses over seventy open-source autonomous driving datasets from domestic and international sources. It offers insights into various aspects, such as the principles underlying the creation of high-quality datasets, the pivotal role of data engine systems, and the utilization of generative foundation models to facilitate scalable data generation. Furthermore, this review undertakes an exhaustive analysis and discourse regarding the characteristics and data scales that future third-generation autonomous driving datasets should possess. It also delves into the scientific and technical challenges that warrant resolution. These endeavors are pivotal in advancing autonomous innovation and fostering technological enhancement in critical domains. For further details, please refer to https://github.com/OpenDriveLab/DriveAGI.
Application of a Dense Fusion Attention Network in Fault Diagnosis of Centrifugal Fan
Nov 12, 2023Although the deep learning recognition model has been widely used in the condition monitoring of rotating machinery. However, it is still a challenge to understand the correspondence between the structure and function of the model and the diagnosis process. Therefore, this paper discusses embedding distributed attention modules into dense connections instead of traditional dense cascading operations. It not only decouples the influence of space and channel on fault feature adaptive recalibration feature weights, but also forms a fusion attention function. The proposed dense fusion focuses on the visualization of the network diagnosis process, which increases the interpretability of model diagnosis. How to continuously and effectively integrate different functions to enhance the ability to extract fault features and the ability to resist noise is answered. Centrifugal fan fault data is used to verify this network. Experimental results show that the network has stronger diagnostic performance than other advanced fault diagnostic models.
Road Genome: A Topology Reasoning Benchmark for Scene Understanding in Autonomous Driving
Apr 20, 2023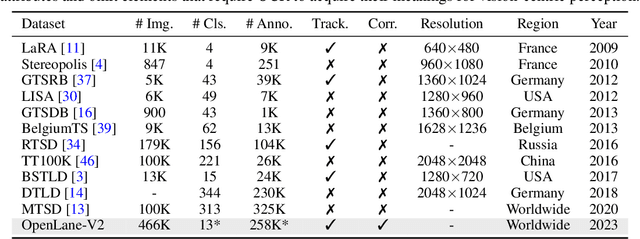
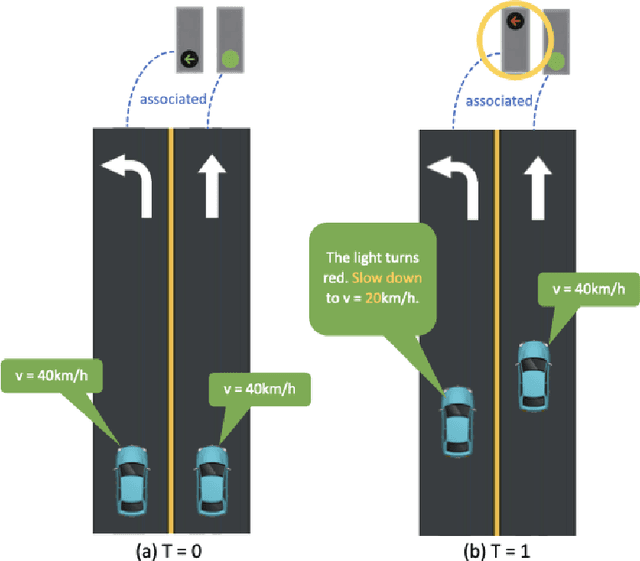
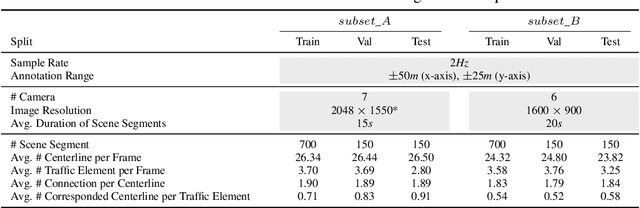
Understanding the complex traffic environment is crucial for self-driving vehicles. Existing benchmarks in autonomous driving mainly cast scene understanding as perception problems, e.g., perceiving lanelines with vanilla detection or segmentation methods. As such, we argue that the perception pipeline provides limited information for autonomous vehicles to drive in the right way, especially without the aid of high-definition (HD) map. For instance, following the wrong traffic signal at a complicated crossroad would lead to a catastrophic incident. By introducing Road Genome (OpenLane-V2), we intend to shift the community's attention and take a step further beyond perception - to the task of topology reasoning for scene structure. The goal of Road Genome is to understand the scene structure by investigating the relationship of perceived entities among traffic elements and lanes. Built on top of prevailing datasets, the newly minted benchmark comprises 2,000 sequences of multi-view images captured from diverse real-world scenarios. We annotate data with high-quality manual checks in the loop. Three subtasks compromise the gist of Road Genome, including the 3D lane detection inherited from OpenLane. We have/will host Challenges in the upcoming future at top-tiered venues.
Topology Reasoning for Driving Scenes
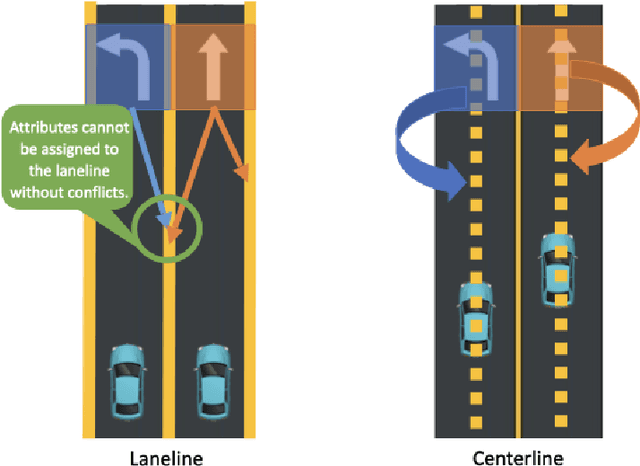
Apr 11, 2023Understanding the road genome is essential to realize autonomous driving. This highly intelligent problem contains two aspects - the connection relationship of lanes, and the assignment relationship between lanes and traffic elements, where a comprehensive topology reasoning method is vacant. On one hand, previous map learning techniques struggle in deriving lane connectivity with segmentation or laneline paradigms; or prior lane topology-oriented approaches focus on centerline detection and neglect the interaction modeling. On the other hand, the traffic element to lane assignment problem is limited in the image domain, leaving how to construct the correspondence from two views an unexplored challenge. To address these issues, we present TopoNet, the first end-to-end framework capable of abstracting traffic knowledge beyond conventional perception tasks. To capture the driving scene topology, we introduce three key designs: (1) an embedding module to incorporate semantic knowledge from 2D elements into a unified feature space; (2) a curated scene graph neural network to model relationships and enable feature interaction inside the network; (3) instead of transmitting messages arbitrarily, a scene knowledge graph is devised to differentiate prior knowledge from various types of the road genome. We evaluate TopoNet on the challenging scene understanding benchmark, OpenLane-V2, where our approach outperforms all previous works by a great margin on all perceptual and topological metrics. The code would be released soon.
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Apr 07, 2023Multi-camera 3D object detection for autonomous driving is a challenging problem that has garnered notable attention from both academia and industry. An obstacle encountered in vision-based techniques involves the precise extraction of geometry-conscious features from RGB images. Recent approaches have utilized geometric-aware image backbones pretrained on depth-relevant tasks to acquire spatial information. However, these approaches overlook the critical aspect of view transformation, resulting in inadequate performance due to the misalignment of spatial knowledge between the image backbone and view transformation. To address this issue, we propose a novel geometric-aware pretraining framework called GAPretrain. Our approach incorporates spatial and structural cues to camera networks by employing the geometric-rich modality as guidance during the pretraining phase. The transference of modal-specific attributes across different modalities is non-trivial, but we bridge this gap by using a unified bird's-eye-view (BEV) representation and structural hints derived from LiDAR point clouds to facilitate the pretraining process. GAPretrain serves as a plug-and-play solution that can be flexibly applied to multiple state-of-the-art detectors. Our experiments demonstrate the effectiveness and generalization ability of the proposed method. We achieve 46.2 mAP and 55.5 NDS on the nuScenes val set using the BEVFormer method, with a gain of 2.7 and 2.1 points, respectively. We also conduct experiments on various image backbones and view transformations to validate the efficacy of our approach. Code will be released at https://github.com/OpenDriveLab/BEVPerception-Survey-Recipe.
Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022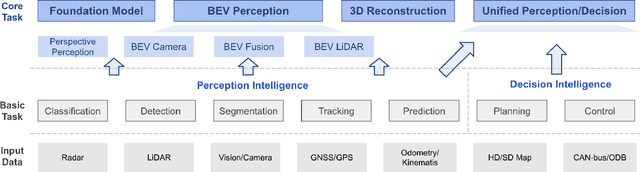
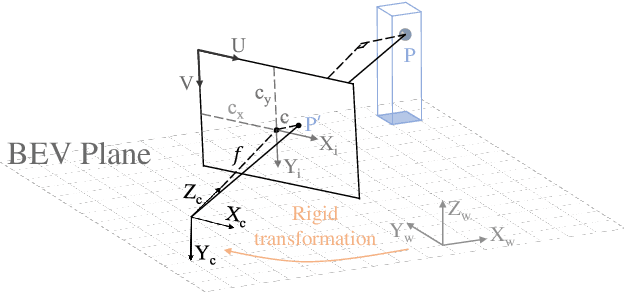
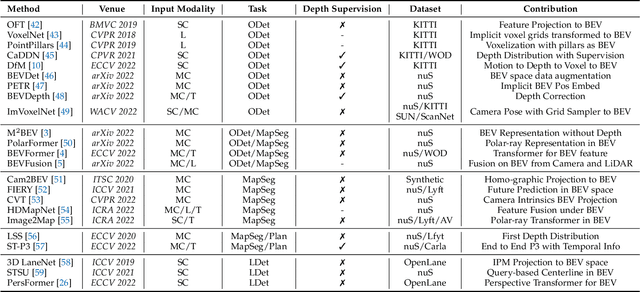
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.
Multi-Compound Transformer for Accurate Biomedical Image Segmentation
Jun 28, 2021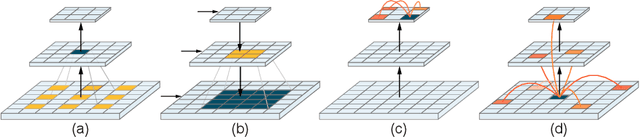
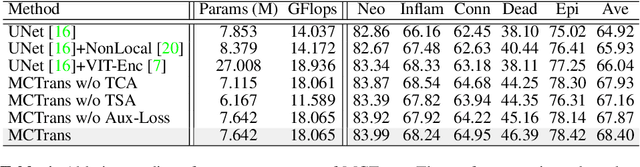
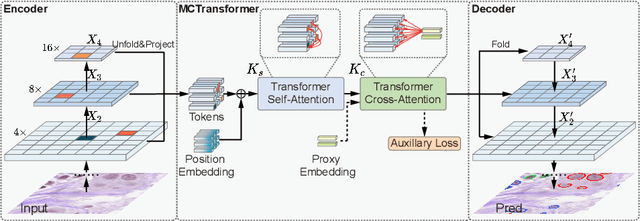
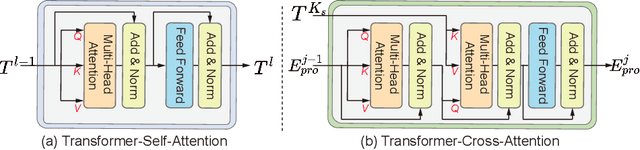
The recent vision transformer(i.e.for image classification) learns non-local attentive interaction of different patch tokens. However, prior arts miss learning the cross-scale dependencies of different pixels, the semantic correspondence of different labels, and the consistency of the feature representations and semantic embeddings, which are critical for biomedical segmentation. In this paper, we tackle the above issues by proposing a unified transformer network, termed Multi-Compound Transformer (MCTrans), which incorporates rich feature learning and semantic structure mining into a unified framework. Specifically, MCTrans embeds the multi-scale convolutional features as a sequence of tokens and performs intra- and inter-scale self-attention, rather than single-scale attention in previous works. In addition, a learnable proxy embedding is also introduced to model semantic relationship and feature enhancement by using self-attention and cross-attention, respectively. MCTrans can be easily plugged into a UNet-like network and attains a significant improvement over the state-of-the-art methods in biomedical image segmentation in six standard benchmarks. For example, MCTrans outperforms UNet by 3.64%, 3.71%, 4.34%, 2.8%, 1.88%, 1.57% in Pannuke, CVC-Clinic, CVC-Colon, Etis, Kavirs, ISIC2018 dataset, respectively. Code is available at https://github.com/JiYuanFeng/MCTrans.