 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad Genome: A Topology Reasoning Benchmark for Scene Understanding in Autonomous Driving
Apr 20, 2023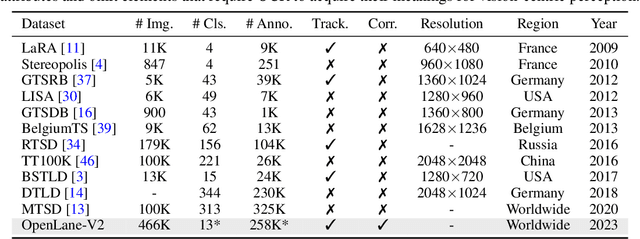
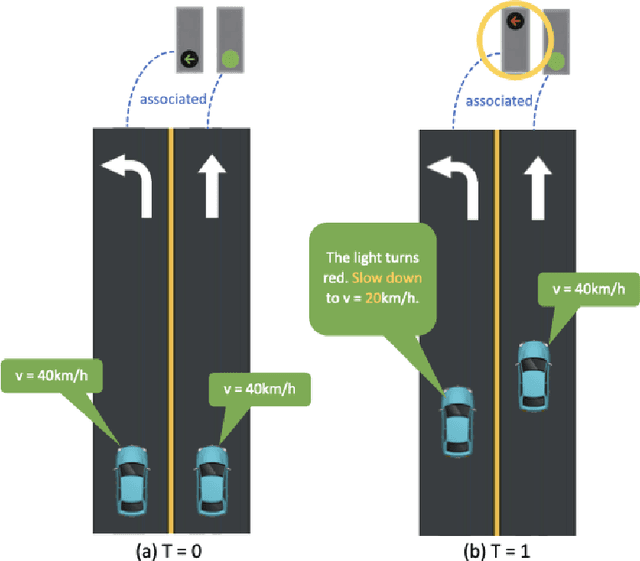
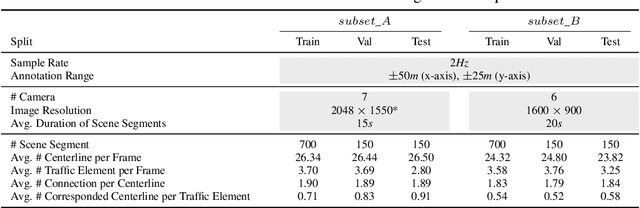
Understanding the complex traffic environment is crucial for self-driving vehicles. Existing benchmarks in autonomous driving mainly cast scene understanding as perception problems, e.g., perceiving lanelines with vanilla detection or segmentation methods. As such, we argue that the perception pipeline provides limited information for autonomous vehicles to drive in the right way, especially without the aid of high-definition (HD) map. For instance, following the wrong traffic signal at a complicated crossroad would lead to a catastrophic incident. By introducing Road Genome (OpenLane-V2), we intend to shift the community's attention and take a step further beyond perception - to the task of topology reasoning for scene structure. The goal of Road Genome is to understand the scene structure by investigating the relationship of perceived entities among traffic elements and lanes. Built on top of prevailing datasets, the newly minted benchmark comprises 2,000 sequences of multi-view images captured from diverse real-world scenarios. We annotate data with high-quality manual checks in the loop. Three subtasks compromise the gist of Road Genome, including the 3D lane detection inherited from OpenLane. We have/will host Challenges in the upcoming future at top-tiered venues.
Topology Reasoning for Driving Scenes
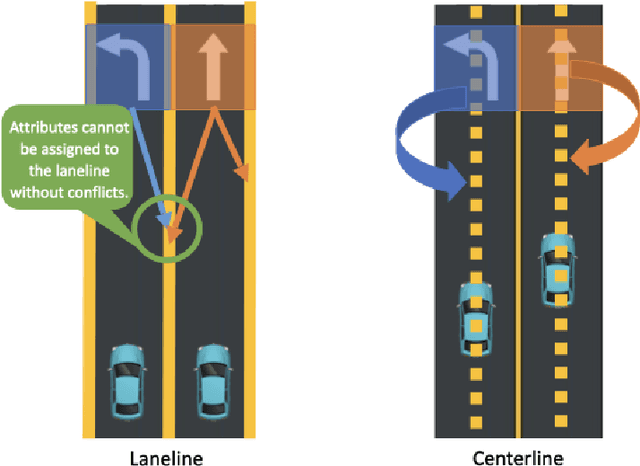
Apr 11, 2023Understanding the road genome is essential to realize autonomous driving. This highly intelligent problem contains two aspects - the connection relationship of lanes, and the assignment relationship between lanes and traffic elements, where a comprehensive topology reasoning method is vacant. On one hand, previous map learning techniques struggle in deriving lane connectivity with segmentation or laneline paradigms; or prior lane topology-oriented approaches focus on centerline detection and neglect the interaction modeling. On the other hand, the traffic element to lane assignment problem is limited in the image domain, leaving how to construct the correspondence from two views an unexplored challenge. To address these issues, we present TopoNet, the first end-to-end framework capable of abstracting traffic knowledge beyond conventional perception tasks. To capture the driving scene topology, we introduce three key designs: (1) an embedding module to incorporate semantic knowledge from 2D elements into a unified feature space; (2) a curated scene graph neural network to model relationships and enable feature interaction inside the network; (3) instead of transmitting messages arbitrarily, a scene knowledge graph is devised to differentiate prior knowledge from various types of the road genome. We evaluate TopoNet on the challenging scene understanding benchmark, OpenLane-V2, where our approach outperforms all previous works by a great margin on all perceptual and topological metrics. The code would be released soon.
SrTR: Self-reasoning Transformer with Visual-linguistic Knowledge for Scene Graph Generation
Dec 19, 2022Objects in a scene are not always related. The execution efficiency of the one-stage scene graph generation approaches are quite high, which infer the effective relation between entity pairs using sparse proposal sets and a few queries. However, they only focus on the relation between subject and object in triplet set subject entity, predicate entity, object entity, ignoring the relation between subject and predicate or predicate and object, and the model lacks self-reasoning ability. In addition, linguistic modality has been neglected in the one-stage method. It is necessary to mine linguistic modality knowledge to improve model reasoning ability. To address the above-mentioned shortcomings, a Self-reasoning Transformer with Visual-linguistic Knowledge (SrTR) is proposed to add flexible self-reasoning ability to the model. An encoder-decoder architecture is adopted in SrTR, and a self-reasoning decoder is developed to complete three inferences of the triplet set, s+o-p, s+p-o and p+o-s. Inspired by the large-scale pre-training image-text foundation models, visual-linguistic prior knowledge is introduced and a visual-linguistic alignment strategy is designed to project visual representations into semantic spaces with prior knowledge to aid relational reasoning. Experiments on the Visual Genome dataset demonstrate the superiority and fast inference ability of the proposed method.