 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Foundation Model for Multimodal Histopathology
Apr 04, 2026Accurate diagnosis and treatment of complex diseases require integrating histological, molecular, and clinical data, yet in practice these modalities are often incomplete owing to tissue scarcity, assay cost, and workflow constraints. Existing computational approaches attempt to impute missing modalities from available data but rely on task-specific models trained on narrow, single source-target pairs, limiting their generalizability. Here we introduce MuPD (Multimodal Pathology Diffusion), a generative foundation model that embeds hematoxylin and eosin (H&E)-stained histology, molecular RNA profiles, and clinical text into a shared latent space through a diffusion transformer with decoupled cross-modal attention. Pretrained on 100 million histology image patches, 1.6 million text-histology pairs, and 10.8 million RNA-histology pairs spanning 34 human organs, MuPD supports diverse cross-modal synthesis tasks with minimal or no task-specific fine-tuning. For text-conditioned and image-to-image generation, MuPD synthesizes histologically faithful tissue architectures, reducing Fréchet inception distance (FID) scores by 50% relative to domain-specific models and improving few-shot classification accuracy by up to 47% through synthetic data augmentation. For RNA-conditioned histology generation, MuPD reduces FID by 23% compared with the next-best method while preserving cell-type distributions across five cancer types. As a virtual stainer, MuPD translates H&E images to immunohistochemistry and multiplex immunofluorescence, improving average marker correlation by 37% over existing approaches. These results demonstrate that a single, unified generative model pretrained across heterogeneous pathology modalities can substantially outperform specialized alternatives, providing a scalable computational framework for multimodal histopathology.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
nnMIL: A generalizable multiple instance learning framework for computational pathology
Nov 18, 2025Computational pathology holds substantial promise for improving diagnosis and guiding treatment decisions. Recent pathology foundation models enable the extraction of rich patch-level representations from large-scale whole-slide images (WSIs), but current approaches for aggregating these features into slide-level predictions remain constrained by design limitations that hinder generalizability and reliability. Here, we developed nnMIL, a simple yet broadly applicable multiple-instance learning framework that connects patch-level foundation models to robust slide-level clinical inference. nnMIL introduces random sampling at both the patch and feature levels, enabling large-batch optimization, task-aware sampling strategies, and efficient and scalable training across datasets and model architectures. A lightweight aggregator performs sliding-window inference to generate ensemble slide-level predictions and supports principled uncertainty estimation. Across 40,000 WSIs encompassing 35 clinical tasks and four pathology foundation models, nnMIL consistently outperformed existing MIL methods for disease diagnosis, histologic subtyping, molecular biomarker detection, and pan- cancer prognosis prediction. It further demonstrated strong cross-model generalization, reliable uncertainty quantification, and robust survival stratification in multiple external cohorts. In conclusion, nnMIL offers a practical and generalizable solution for translating pathology foundation models into clinically meaningful predictions, advancing the development and deployment of reliable AI systems in real-world settings.
A Generative Foundation Model for Chest Radiography
Sep 04, 2025The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
MedITok: A Unified Tokenizer for Medical Image Synthesis and Interpretation
May 25, 2025Advanced autoregressive models have reshaped multimodal AI. However, their transformative potential in medical imaging remains largely untapped due to the absence of a unified visual tokenizer -- one capable of capturing fine-grained visual structures for faithful image reconstruction and realistic image synthesis, as well as rich semantics for accurate diagnosis and image interpretation. To this end, we present MedITok, the first unified tokenizer tailored for medical images, encoding both low-level structural details and high-level clinical semantics within a unified latent space. To balance these competing objectives, we introduce a novel two-stage training framework: a visual representation alignment stage that cold-starts the tokenizer reconstruction learning with a visual semantic constraint, followed by a textual semantic representation alignment stage that infuses detailed clinical semantics into the latent space. Trained on the meticulously collected large-scale dataset with over 30 million medical images and 2 million image-caption pairs, MedITok achieves state-of-the-art performance on more than 30 datasets across 9 imaging modalities and 4 different tasks. By providing a unified token space for autoregressive modeling, MedITok supports a wide range of tasks in clinical diagnostics and generative healthcare applications. Model and code will be made publicly available at: https://github.com/Masaaki-75/meditok.
RetinaLogos: Fine-Grained Synthesis of High-Resolution Retinal Images Through Captions
May 19, 2025The scarcity of high-quality, labelled retinal imaging data, which presents a significant challenge in the development of machine learning models for ophthalmology, hinders progress in the field. To synthesise Colour Fundus Photographs (CFPs), existing methods primarily relying on predefined disease labels face significant limitations. However, current methods remain limited, thus failing to generate images for broader categories with diverse and fine-grained anatomical structures. To overcome these challenges, we first introduce an innovative pipeline that creates a large-scale, synthetic Caption-CFP dataset comprising 1.4 million entries, called RetinaLogos-1400k. Specifically, RetinaLogos-1400k uses large language models (LLMs) to describe retinal conditions and key structures, such as optic disc configuration, vascular distribution, nerve fibre layers, and pathological features. Furthermore, based on this dataset, we employ a novel three-step training framework, called RetinaLogos, which enables fine-grained semantic control over retinal images and accurately captures different stages of disease progression, subtle anatomical variations, and specific lesion types. Extensive experiments demonstrate state-of-the-art performance across multiple datasets, with 62.07% of text-driven synthetic images indistinguishable from real ones by ophthalmologists. Moreover, the synthetic data improves accuracy by 10%-25% in diabetic retinopathy grading and glaucoma detection, thereby providing a scalable solution to augment ophthalmic datasets.
GMAI-VL-R1: Harnessing Reinforcement Learning for Multimodal Medical Reasoning
Apr 02, 2025Recent advances in general medical AI have made significant strides, but existing models often lack the reasoning capabilities needed for complex medical decision-making. This paper presents GMAI-VL-R1, a multimodal medical reasoning model enhanced by reinforcement learning (RL) to improve its reasoning abilities. Through iterative training, GMAI-VL-R1 optimizes decision-making, significantly boosting diagnostic accuracy and clinical support. We also develop a reasoning data synthesis method, generating step-by-step reasoning data via rejection sampling, which further enhances the model's generalization. Experimental results show that after RL training, GMAI-VL-R1 excels in tasks such as medical image diagnosis and visual question answering. While the model demonstrates basic memorization with supervised fine-tuning, RL is crucial for true generalization. Our work establishes new evaluation benchmarks and paves the way for future advancements in medical reasoning models. Code, data, and model will be released at \href{https://github.com/uni-medical/GMAI-VL-R1}{this link}.
Towards Interpretable Counterfactual Generation via Multimodal Autoregression
Mar 29, 2025Counterfactual medical image generation enables clinicians to explore clinical hypotheses, such as predicting disease progression, facilitating their decision-making. While existing methods can generate visually plausible images from disease progression prompts, they produce silent predictions that lack interpretation to verify how the generation reflects the hypothesized progression -- a critical gap for medical applications that require traceable reasoning. In this paper, we propose Interpretable Counterfactual Generation (ICG), a novel task requiring the joint generation of counterfactual images that reflect the clinical hypothesis and interpretation texts that outline the visual changes induced by the hypothesis. To enable ICG, we present ICG-CXR, the first dataset pairing longitudinal medical images with hypothetical progression prompts and textual interpretations. We further introduce ProgEmu, an autoregressive model that unifies the generation of counterfactual images and textual interpretations. We demonstrate the superiority of ProgEmu in generating progression-aligned counterfactuals and interpretations, showing significant potential in enhancing clinical decision support and medical education. Project page: https://progemu.github.io.
SegBook: A Simple Baseline and Cookbook for Volumetric Medical Image Segmentation
Nov 21, 2024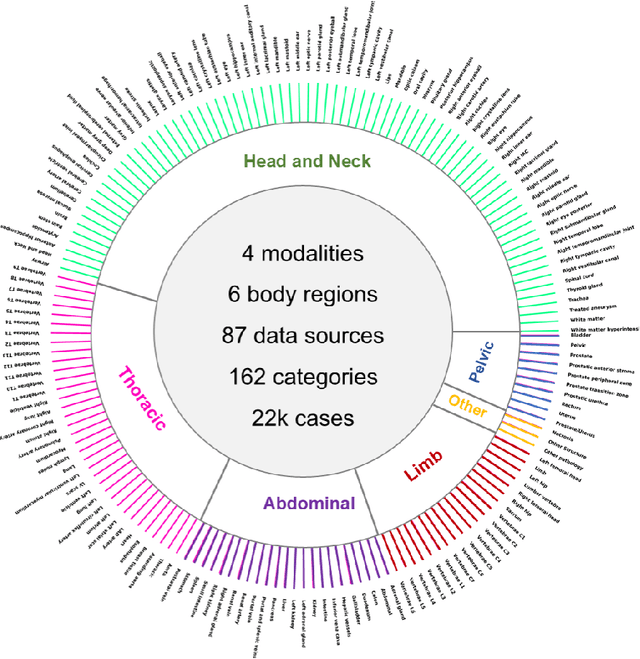

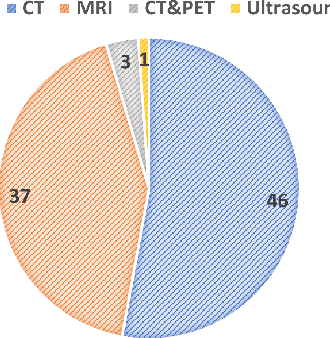
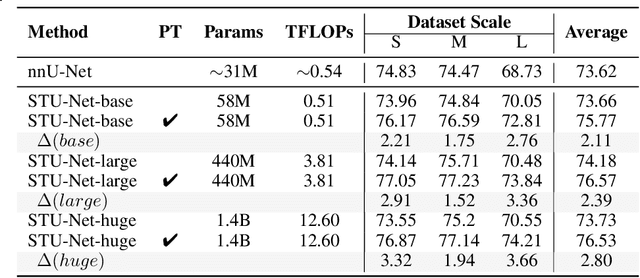
Computed Tomography (CT) is one of the most popular modalities for medical imaging. By far, CT images have contributed to the largest publicly available datasets for volumetric medical segmentation tasks, covering full-body anatomical structures. Large amounts of full-body CT images provide the opportunity to pre-train powerful models, e.g., STU-Net pre-trained in a supervised fashion, to segment numerous anatomical structures. However, it remains unclear in which conditions these pre-trained models can be transferred to various downstream medical segmentation tasks, particularly segmenting the other modalities and diverse targets. To address this problem, a large-scale benchmark for comprehensive evaluation is crucial for finding these conditions. Thus, we collected 87 public datasets varying in modality, target, and sample size to evaluate the transfer ability of full-body CT pre-trained models. We then employed a representative model, STU-Net with multiple model scales, to conduct transfer learning across modalities and targets. Our experimental results show that (1) there may be a bottleneck effect concerning the dataset size in fine-tuning, with more improvement on both small- and large-scale datasets than medium-size ones. (2) Models pre-trained on full-body CT demonstrate effective modality transfer, adapting well to other modalities such as MRI. (3) Pre-training on the full-body CT not only supports strong performance in structure detection but also shows efficacy in lesion detection, showcasing adaptability across target tasks. We hope that this large-scale open evaluation of transfer learning can direct future research in volumetric medical image segmentation.