 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Spectral Feature Forecasting for Diffusion Sampling Acceleration
Mar 02, 2026Diffusion models have become the dominant tool for high-fidelity image and video generation, yet are critically bottlenecked by their inference speed due to the numerous iterative passes of Diffusion Transformers. To reduce the exhaustive compute, recent works resort to the feature caching and reusing scheme that skips network evaluations at selected diffusion steps by using cached features in previous steps. However, their preliminary design solely relies on local approximation, causing errors to grow rapidly with large skips and leading to degraded sample quality at high speedups. In this work, we propose spectral diffusion feature forecaster (Spectrum), a training-free approach that enables global, long-range feature reuse with tightly controlled error. In particular, we view the latent features of the denoiser as functions over time and approximate them with Chebyshev polynomials. Specifically, we fit the coefficient for each basis via ridge regression, which is then leveraged to forecast features at multiple future diffusion steps. We theoretically reveal that our approach admits more favorable long-horizon behavior and yields an error bound that does not compound with the step size. Extensive experiments on various state-of-the-art image and video diffusion models consistently verify the superiority of our approach. Notably, we achieve up to 4.79$\times$ speedup on FLUX.1 and 4.67$\times$ speedup on Wan2.1-14B, while maintaining much higher sample quality compared with the baselines.
VTok: A Unified Video Tokenizer with Decoupled Spatial-Temporal Latents
Feb 04, 2026This work presents VTok, a unified video tokenization framework that can be used for both generation and understanding tasks. Unlike the leading vision-language systems that tokenize videos through a naive frame-sampling strategy, we propose to decouple the spatial and temporal representations of videos by retaining the spatial features of a single key frame while encoding each subsequent frame into a single residual token, achieving compact yet expressive video tokenization. Our experiments suggest that VTok effectively reduces the complexity of video representation from the product of frame count and per-frame token count to their sum, while the residual tokens sufficiently capture viewpoint and motion changes relative to the key frame. Extensive evaluations demonstrate the efficacy and efficiency of VTok: it achieves notably higher performance on a range of video understanding and text-to-video generation benchmarks compared with baselines using naive tokenization, all with shorter token sequences per video (e.g., 3.4% higher accuracy on our TV-Align benchmark and 1.9% higher VBench score). Remarkably, VTok produces more coherent motion and stronger guidance following in text-to-video generation, owing to its more consistent temporal encoding. We hope VTok can serve as a standardized video tokenization paradigm for future research in video understanding and generation.
Composable Visual Tokenizers with Generator-Free Diagnostics of Learnability
Feb 03, 2026We introduce CompTok, a training framework for learning visual tokenizers whose tokens are enhanced for compositionality. CompTok uses a token-conditioned diffusion decoder. By employing an InfoGAN-style objective, where we train a recognition model to predict the tokens used to condition the diffusion decoder using the decoded images, we enforce the decoder to not ignore any of the tokens. To promote compositional control, besides the original images, CompTok also trains on tokens formed by swapping token subsets between images, enabling more compositional control of the token over the decoder. As the swapped tokens between images do not have ground truth image targets, we apply a manifold constraint via an adversarial flow regularizer to keep unpaired swap generations on the natural-image distribution. The resulting tokenizer not only achieves state-of-the-art performance on image class-conditioned generation, but also demonstrates properties such as swapping tokens between images to achieve high level semantic editing of an image. Additionally, we propose two metrics that measures the landscape of the token space that can be useful to describe not only the compositionality of the tokens, but also how easy to learn the landscape is for a generator to be trained on this space. We show in experiments that CompTok can improve on both of the metrics as well as supporting state-of-the-art generators for class conditioned generation.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
MedITok: A Unified Tokenizer for Medical Image Synthesis and Interpretation
May 25, 2025Advanced autoregressive models have reshaped multimodal AI. However, their transformative potential in medical imaging remains largely untapped due to the absence of a unified visual tokenizer -- one capable of capturing fine-grained visual structures for faithful image reconstruction and realistic image synthesis, as well as rich semantics for accurate diagnosis and image interpretation. To this end, we present MedITok, the first unified tokenizer tailored for medical images, encoding both low-level structural details and high-level clinical semantics within a unified latent space. To balance these competing objectives, we introduce a novel two-stage training framework: a visual representation alignment stage that cold-starts the tokenizer reconstruction learning with a visual semantic constraint, followed by a textual semantic representation alignment stage that infuses detailed clinical semantics into the latent space. Trained on the meticulously collected large-scale dataset with over 30 million medical images and 2 million image-caption pairs, MedITok achieves state-of-the-art performance on more than 30 datasets across 9 imaging modalities and 4 different tasks. By providing a unified token space for autoregressive modeling, MedITok supports a wide range of tasks in clinical diagnostics and generative healthcare applications. Model and code will be made publicly available at: https://github.com/Masaaki-75/meditok.
DanceGRPO: Unleashing GRPO on Visual Generation
May 12, 2025
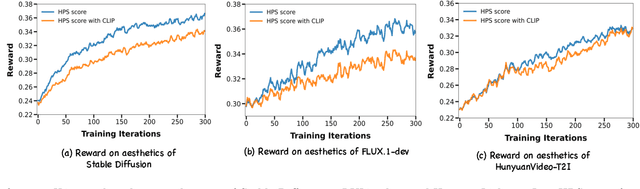
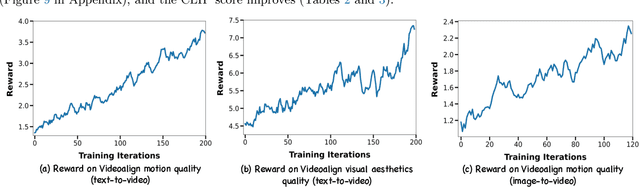

Recent breakthroughs in generative models-particularly diffusion models and rectified flows-have revolutionized visual content creation, yet aligning model outputs with human preferences remains a critical challenge. Existing reinforcement learning (RL)-based methods for visual generation face critical limitations: incompatibility with modern Ordinary Differential Equations (ODEs)-based sampling paradigms, instability in large-scale training, and lack of validation for video generation. This paper introduces DanceGRPO, the first unified framework to adapt Group Relative Policy Optimization (GRPO) to visual generation paradigms, unleashing one unified RL algorithm across two generative paradigms (diffusion models and rectified flows), three tasks (text-to-image, text-to-video, image-to-video), four foundation models (Stable Diffusion, HunyuanVideo, FLUX, SkyReel-I2V), and five reward models (image/video aesthetics, text-image alignment, video motion quality, and binary reward). To our knowledge, DanceGRPO is the first RL-based unified framework capable of seamless adaptation across diverse generative paradigms, tasks, foundational models, and reward models. DanceGRPO demonstrates consistent and substantial improvements, which outperform baselines by up to 181% on benchmarks such as HPS-v2.1, CLIP Score, VideoAlign, and GenEval. Notably, DanceGRPO not only can stabilize policy optimization for complex video generation, but also enables generative policy to better capture denoising trajectories for Best-of-N inference scaling and learn from sparse binary feedback. Our results establish DanceGRPO as a robust and versatile solution for scaling Reinforcement Learning from Human Feedback (RLHF) tasks in visual generation, offering new insights into harmonizing reinforcement learning and visual synthesis. The code will be released.
Seedream 3.0 Technical Report
Apr 16, 2025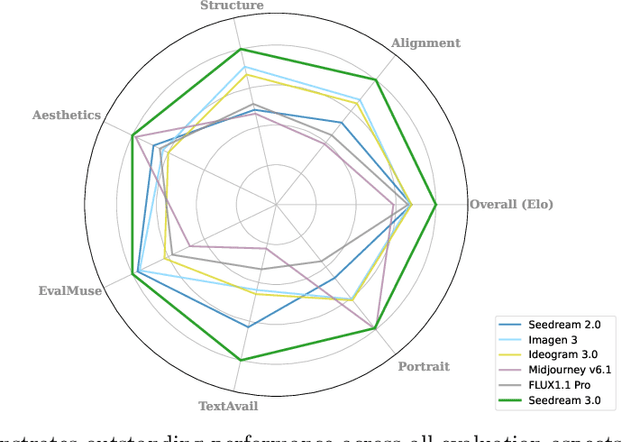


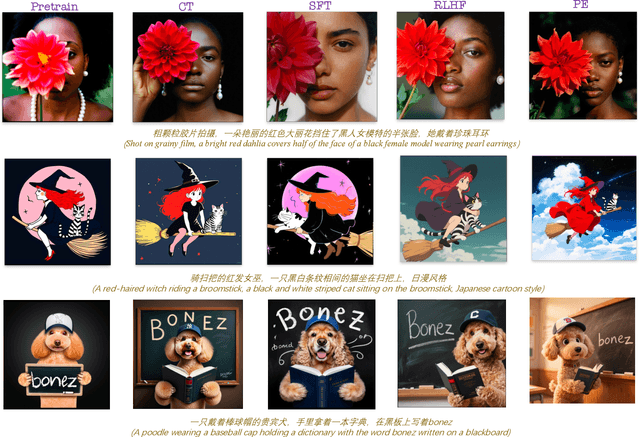
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
SpatialRGPT: Grounded Spatial Reasoning in Vision Language Model
Jun 03, 2024



Vision Language Models (VLMs) have demonstrated remarkable performance in 2D vision and language tasks. However, their ability to reason about spatial arrangements remains limited. In this work, we introduce Spatial Region GPT (SpatialRGPT) to enhance VLMs' spatial perception and reasoning capabilities. SpatialRGPT advances VLMs' spatial understanding through two key innovations: (1) a data curation pipeline that enables effective learning of regional representation from 3D scene graphs, and (2) a flexible plugin module for integrating depth information into the visual encoder of existing VLMs. During inference, when provided with user-specified region proposals, SpatialRGPT can accurately perceive their relative directions and distances. Additionally, we propose SpatialRGBT-Bench, a benchmark with ground-truth 3D annotations encompassing indoor, outdoor, and simulated environments, for evaluating 3D spatial cognition in VLMs. Our results demonstrate that SpatialRGPT significantly enhances performance in spatial reasoning tasks, both with and without local region prompts. The model also exhibits strong generalization capabilities, effectively reasoning about complex spatial relations and functioning as a region-aware dense reward annotator for robotic tasks. Code, dataset, and benchmark will be released at https://www.anjiecheng.me/SpatialRGPT
Plot2Code: A Comprehensive Benchmark for Evaluating Multi-modal Large Language Models in Code Generation from Scientific Plots
May 13, 2024



The remarkable progress of Multi-modal Large Language Models (MLLMs) has attracted significant attention due to their superior performance in visual contexts. However, their capabilities in turning visual figure to executable code, have not been evaluated thoroughly. To address this, we introduce Plot2Code, a comprehensive visual coding benchmark designed for a fair and in-depth assessment of MLLMs. We carefully collect 132 manually selected high-quality matplotlib plots across six plot types from publicly available matplotlib galleries. For each plot, we carefully offer its source code, and an descriptive instruction summarized by GPT-4. This approach enables Plot2Code to extensively evaluate MLLMs' code capabilities across various input modalities. Furthermore, we propose three automatic evaluation metrics, including code pass rate, text-match ratio, and GPT-4V overall rating, for a fine-grained assessment of the output code and rendered images. Instead of simply judging pass or fail, we employ GPT-4V to make an overall judgement between the generated and reference images, which has been shown to be consistent with human evaluation. The evaluation results, which include analyses of 14 MLLMs such as the proprietary GPT-4V, Gemini-Pro, and the open-sourced Mini-Gemini, highlight the substantial challenges presented by Plot2Code. With Plot2Code, we reveal that most existing MLLMs struggle with visual coding for text-dense plots, heavily relying on textual instruction. We hope that the evaluation results from Plot2Code on visual coding will guide the future development of MLLMs. All data involved with Plot2Code are available at https://huggingface.co/datasets/TencentARC/Plot2Code.
RegionGPT: Towards Region Understanding Vision Language Model
Mar 04, 2024

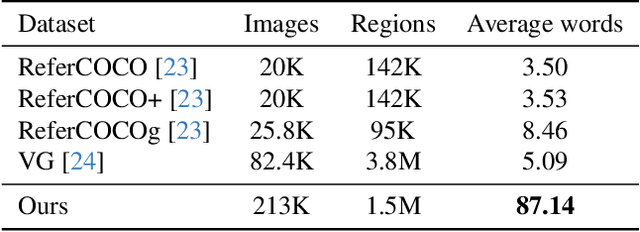

Vision language models (VLMs) have experienced rapid advancements through the integration of large language models (LLMs) with image-text pairs, yet they struggle with detailed regional visual understanding due to limited spatial awareness of the vision encoder, and the use of coarse-grained training data that lacks detailed, region-specific captions. To address this, we introduce RegionGPT (short as RGPT), a novel framework designed for complex region-level captioning and understanding. RGPT enhances the spatial awareness of regional representation with simple yet effective modifications to existing visual encoders in VLMs. We further improve performance on tasks requiring a specific output scope by integrating task-guided instruction prompts during both training and inference phases, while maintaining the model's versatility for general-purpose tasks. Additionally, we develop an automated region caption data generation pipeline, enriching the training set with detailed region-level captions. We demonstrate that a universal RGPT model can be effectively applied and significantly enhancing performance across a range of region-level tasks, including but not limited to complex region descriptions, reasoning, object classification, and referring expressions comprehension.