 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Post-Train Framework for Video Generation
Apr 28, 2026While large-scale video diffusion models have demonstrated impressive capabilities in generating high-resolution and semantically rich content, a significant gap remains between their pretraining performance and real-world deployment requirements due to critical issues such as prompt sensitivity, temporal inconsistency, and prohibitive inference costs. To bridge this gap, we propose a comprehensive post-training framework that systematically aligns pretrained models with user intentions through four synergistic stages: we first employ Supervised Fine-Tuning (SFT) to transform the base model into a stable instruction-following policy, followed by a Reinforcement Learning from Human Feedback (RLHF) stage that utilizes a novel Group Relative Policy Optimization (GRPO) method tailored for video diffusion to enhance perceptual quality and temporal coherence; subsequently, we integrate Prompt Enhancement via a specialized language model to refine user inputs, and finally address system efficiency through Inference Optimization. Together, these components provide a systematic approach to improving visual quality, temporal coherence, and instruction following, while preserving the controllability learned during pretraining. The result is a practical blueprint for building scalable post-training pipelines that are stable, adaptable, and effective in real-world deployment. Extensive experiments demonstrate that this unified pipeline effectively mitigates common artifacts and significantly improves controllability and visual aesthetics while adhering to strict sampling cost constraints.
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Apr 27, 2026Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.
BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
Feb 04, 2026Large language model (LLM) inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization (PTQ) maintains high fidelity at 4-bit, it deteriorates at 2-3 bits. Fundamentally, existing methods enforce a shape-invariant quantization grid (e.g., the fixed uniform intervals of UINT2) for each group, severely restricting the feasible set for error minimization. To address this, we propose Bit-Plane Decomposition Quantization (BPDQ), which constructs a variable quantization grid via bit-planes and scalar coefficients, and iteratively refines them using approximate second-order information while progressively compensating quantization errors to minimize output discrepancy. In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy (vs. 90.83% at 16-bit). Moreover, we provide theoretical analysis showing that the variable grid expands the feasible set, and that the quantization process consistently aligns with the optimization objective in Hessian-induced geometry. Code: github.com/KingdalfGoodman/BPDQ.
Scaling Law for Quantization-Aware Training
May 20, 2025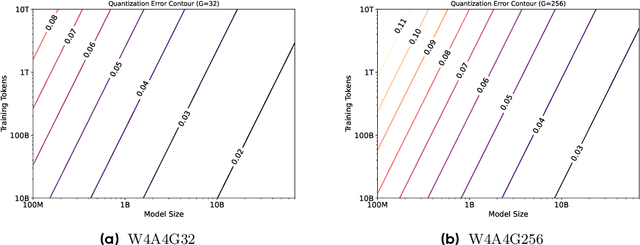
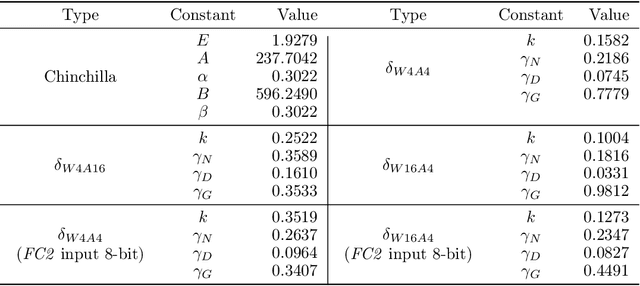
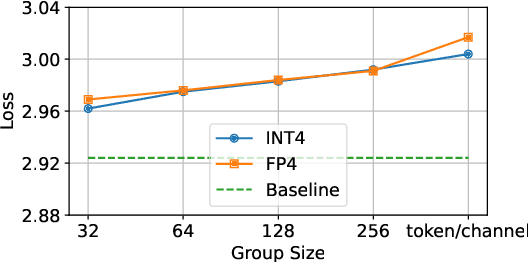
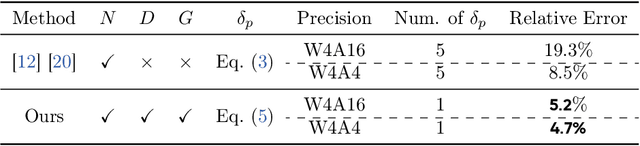
Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
DanceGRPO: Unleashing GRPO on Visual Generation
May 12, 2025
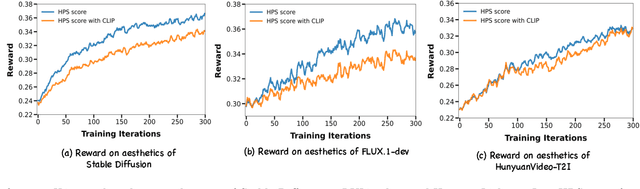
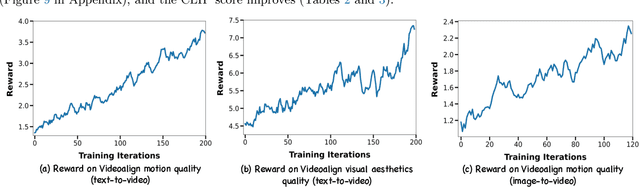

Recent breakthroughs in generative models-particularly diffusion models and rectified flows-have revolutionized visual content creation, yet aligning model outputs with human preferences remains a critical challenge. Existing reinforcement learning (RL)-based methods for visual generation face critical limitations: incompatibility with modern Ordinary Differential Equations (ODEs)-based sampling paradigms, instability in large-scale training, and lack of validation for video generation. This paper introduces DanceGRPO, the first unified framework to adapt Group Relative Policy Optimization (GRPO) to visual generation paradigms, unleashing one unified RL algorithm across two generative paradigms (diffusion models and rectified flows), three tasks (text-to-image, text-to-video, image-to-video), four foundation models (Stable Diffusion, HunyuanVideo, FLUX, SkyReel-I2V), and five reward models (image/video aesthetics, text-image alignment, video motion quality, and binary reward). To our knowledge, DanceGRPO is the first RL-based unified framework capable of seamless adaptation across diverse generative paradigms, tasks, foundational models, and reward models. DanceGRPO demonstrates consistent and substantial improvements, which outperform baselines by up to 181% on benchmarks such as HPS-v2.1, CLIP Score, VideoAlign, and GenEval. Notably, DanceGRPO not only can stabilize policy optimization for complex video generation, but also enables generative policy to better capture denoising trajectories for Best-of-N inference scaling and learn from sparse binary feedback. Our results establish DanceGRPO as a robust and versatile solution for scaling Reinforcement Learning from Human Feedback (RLHF) tasks in visual generation, offering new insights into harmonizing reinforcement learning and visual synthesis. The code will be released.
Enhance-A-Video: Better Generated Video for Free
Feb 11, 2025



DiT-based video generation has achieved remarkable results, but research into enhancing existing models remains relatively unexplored. In this work, we introduce a training-free approach to enhance the coherence and quality of DiT-based generated videos, named Enhance-A-Video. The core idea is enhancing the cross-frame correlations based on non-diagonal temporal attention distributions. Thanks to its simple design, our approach can be easily applied to most DiT-based video generation frameworks without any retraining or fine-tuning. Across various DiT-based video generation models, our approach demonstrates promising improvements in both temporal consistency and visual quality. We hope this research can inspire future explorations in video generation enhancement.
PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs
Oct 07, 2024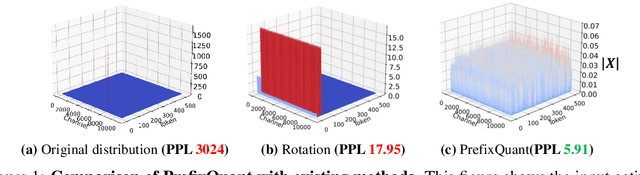
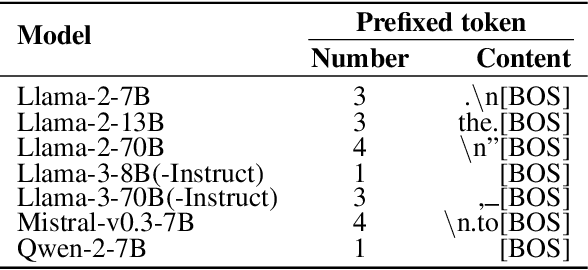
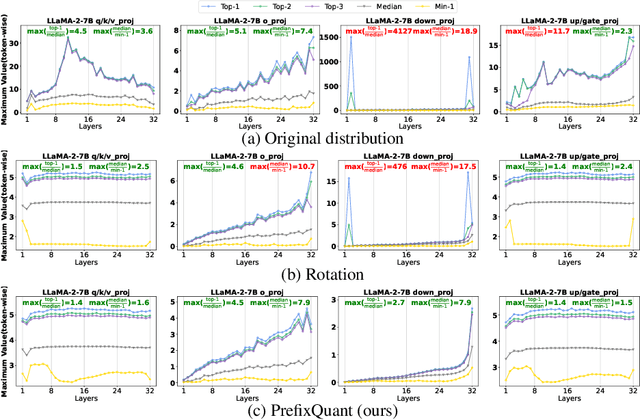

Quantization is essential for deploying Large Language Models (LLMs) by enhancing memory efficiency and inference speed. Existing methods for activation quantization mainly address channel-wise outliers, often neglecting token-wise outliers, leading to reliance on costly per-token dynamic quantization. To address this, we introduce PrefixQuant, a novel technique that isolates outlier tokens offline without re-training. Specifically, PrefixQuant identifies high-frequency outlier tokens and prefixes them in the KV cache, preventing the generation of outlier tokens during inference and simplifying quantization. To our knowledge, PrefixQuant is the first to enable efficient per-tensor static quantization to outperform expensive per-token dynamic quantization. For instance, in W4A4KV4 (4- bit weight, 4-bit activation, and 4-bit KV cache) Llama-3-8B, PrefixQuant with per-tensor static quantization achieves a 7.43 WikiText2 perplexity and 71.08% average accuracy on 5 common-sense reasoning tasks, outperforming previous per-token dynamic quantization methods like QuaRot with 0.98 perplexity improvement and +5.98 points accuracy. Additionally, the inference speed of W4A4 quantized models using PrefixQuant is 1.60x to 2.81x faster than FP16 models and exceeds QuaRot models by 1.2x to 1.3x. Our code is available at \url{https://github.com/ChenMnZ/PrefixQuant}.
Adapting LLaMA Decoder to Vision Transformer
Apr 13, 2024



This work examines whether decoder-only Transformers such as LLaMA, which were originally designed for large language models (LLMs), can be adapted to the computer vision field. We first "LLaMAfy" a standard ViT step-by-step to align with LLaMA's architecture, and find that directly applying a casual mask to the self-attention brings an attention collapse issue, resulting in the failure to the network training. We suggest to reposition the class token behind the image tokens with a post-sequence class token technique to overcome this challenge, enabling causal self-attention to efficiently capture the entire image's information. Additionally, we develop a soft mask strategy that gradually introduces a casual mask to the self-attention at the onset of training to facilitate the optimization behavior. The tailored model, dubbed as image LLaMA (iLLaMA), is akin to LLaMA in architecture and enables direct supervised learning. Its causal self-attention boosts computational efficiency and learns complex representation by elevating attention map ranks. iLLaMA rivals the performance with its encoder-only counterparts, achieving 75.1% ImageNet top-1 accuracy with only 5.7M parameters. Scaling the model to ~310M and pre-training on ImageNet-21K further enhances the accuracy to 86.0%. Extensive experiments demonstrate iLLaMA's reliable properties: calibration, shape-texture bias, quantization compatibility, ADE20K segmentation and CIFAR transfer learning. We hope our study can kindle fresh views to visual model design in the wave of LLMs. Pre-trained models and codes are available here.
BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
Feb 18, 2024Large language models (LLMs) have demonstrated outstanding performance in various tasks, such as text summarization, text question-answering, and etc. While their performance is impressive, the computational footprint due to their vast number of parameters can be prohibitive. Existing solutions such as SparseGPT and Wanda attempt to alleviate this issue through weight pruning. However, their layer-wise approach results in significant perturbation to the model's output and requires meticulous hyperparameter tuning, such as the pruning rate, which can adversely affect overall model performance. To address this, this paper introduces a novel LLM pruning technique dubbed blockwise parameter-efficient sparsity allocation (BESA) by applying a blockwise reconstruction loss. In contrast to the typical layer-wise pruning techniques, BESA is characterized by two distinctive attributes: i) it targets the overall pruning error with respect to individual transformer blocks, and ii) it allocates layer-specific sparsity in a differentiable manner, both of which ensure reduced performance degradation after pruning. Our experiments show that BESA achieves state-of-the-art performance, efficiently pruning LLMs like LLaMA1, and LLaMA2 with 7B to 70B parameters on a single A100 GPU in just five hours. Code is available at \href{https://github.com/OpenGVLab/LLMPrune-BESA}{here}.