 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARKLING: Balancing Signal Preservation and Symmetry Breaking for Width-Progressive Learning
Feb 02, 2026Progressive Learning (PL) reduces pre-training computational overhead by gradually increasing model scale. While prior work has extensively explored depth expansion, width expansion remains significantly understudied, with the few existing methods limited to the early stages of training. However, expanding width during the mid-stage is essential for maximizing computational savings, yet it remains a formidable challenge due to severe training instabilities. Empirically, we show that naive initialization at this stage disrupts activation statistics, triggering loss spikes, while copy-based initialization introduces gradient symmetry that hinders feature diversity. To address these issues, we propose SPARKLING (balancing {S}ignal {P}reservation {A}nd symmet{R}y brea{K}ing for width-progressive {L}earn{ING}), a novel framework for mid-stage width expansion. Our method achieves signal preservation via RMS-scale consistency, stabilizing activation statistics during expansion. Symmetry breaking is ensured through asymmetric optimizer state resetting and learning rate re-warmup. Extensive experiments on Mixture-of-Experts (MoE) models demonstrate that, across multiple width axes and optimizer families, SPARKLING consistently outperforms training from scratch and reduces training cost by up to 35% under $2\times$ width expansion.
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss
Dec 29, 2025Mixture-of-Experts (MoE) models lack explicit constraints to ensure the router's decisions align well with the experts' capabilities, which ultimately limits model performance. To address this, we propose expert-router coupling (ERC) loss, a lightweight auxiliary loss that tightly couples the router's decisions with expert capabilities. Our approach treats each expert's router embedding as a proxy token for the tokens assigned to that expert, and feeds perturbed router embeddings through the experts to obtain internal activations. The ERC loss enforces two constraints on these activations: (1) Each expert must exhibit higher activation for its own proxy token than for the proxy tokens of any other expert. (2) Each proxy token must elicit stronger activation from its corresponding expert than from any other expert. These constraints jointly ensure that each router embedding faithfully represents its corresponding expert's capability, while each expert specializes in processing the tokens actually routed to it. The ERC loss is computationally efficient, operating only on n^2 activations, where n is the number of experts. This represents a fixed cost independent of batch size, unlike prior coupling methods that scale with the number of tokens (often millions per batch). Through pre-training MoE-LLMs ranging from 3B to 15B parameters and extensive analysis on trillions of tokens, we demonstrate the effectiveness of the ERC loss. Moreover, the ERC loss offers flexible control and quantitative tracking of expert specialization levels during training, providing valuable insights into MoEs.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference
Feb 28, 2025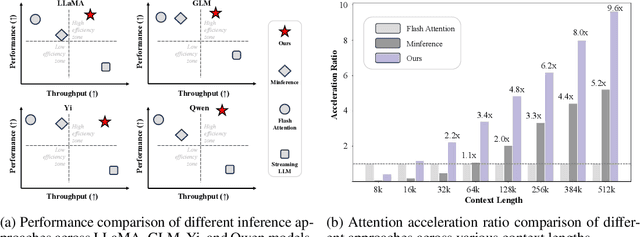



Large language models (LLMs) encounter computational challenges during long-sequence inference, especially in the attention pre-filling phase, where the complexity grows quadratically with the prompt length. Previous efforts to mitigate these challenges have relied on fixed sparse attention patterns or identifying sparse attention patterns based on limited cases. However, these methods lacked the flexibility to efficiently adapt to varying input demands. In this paper, we introduce FlexPrefill, a Flexible sparse Pre-filling mechanism that dynamically adjusts sparse attention patterns and computational budget in real-time to meet the specific requirements of each input and attention head. The flexibility of our method is demonstrated through two key innovations: 1) Query-Aware Sparse Pattern Determination: By measuring Jensen-Shannon divergence, this component adaptively switches between query-specific diverse attention patterns and predefined attention patterns. 2) Cumulative-Attention Based Index Selection: This component dynamically selects query-key indexes to be computed based on different attention patterns, ensuring the sum of attention scores meets a predefined threshold. FlexPrefill adaptively optimizes the sparse pattern and sparse ratio of each attention head based on the prompt, enhancing efficiency in long-sequence inference tasks. Experimental results show significant improvements in both speed and accuracy over prior methods, providing a more flexible and efficient solution for LLM inference.