 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARKLING: Balancing Signal Preservation and Symmetry Breaking for Width-Progressive Learning
Feb 02, 2026Progressive Learning (PL) reduces pre-training computational overhead by gradually increasing model scale. While prior work has extensively explored depth expansion, width expansion remains significantly understudied, with the few existing methods limited to the early stages of training. However, expanding width during the mid-stage is essential for maximizing computational savings, yet it remains a formidable challenge due to severe training instabilities. Empirically, we show that naive initialization at this stage disrupts activation statistics, triggering loss spikes, while copy-based initialization introduces gradient symmetry that hinders feature diversity. To address these issues, we propose SPARKLING (balancing {S}ignal {P}reservation {A}nd symmet{R}y brea{K}ing for width-progressive {L}earn{ING}), a novel framework for mid-stage width expansion. Our method achieves signal preservation via RMS-scale consistency, stabilizing activation statistics during expansion. Symmetry breaking is ensured through asymmetric optimizer state resetting and learning rate re-warmup. Extensive experiments on Mixture-of-Experts (MoE) models demonstrate that, across multiple width axes and optimizer families, SPARKLING consistently outperforms training from scratch and reduces training cost by up to 35% under $2\times$ width expansion.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
Stabilizing Voltage in Power Distribution Networks via Multi-Agent Reinforcement Learning with Transformer
Jun 08, 2022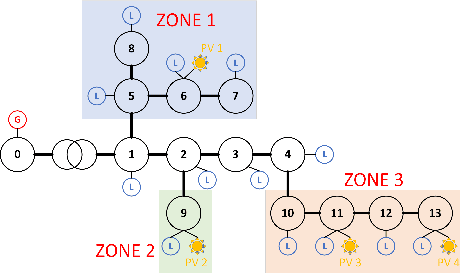
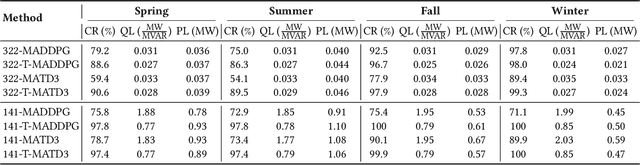
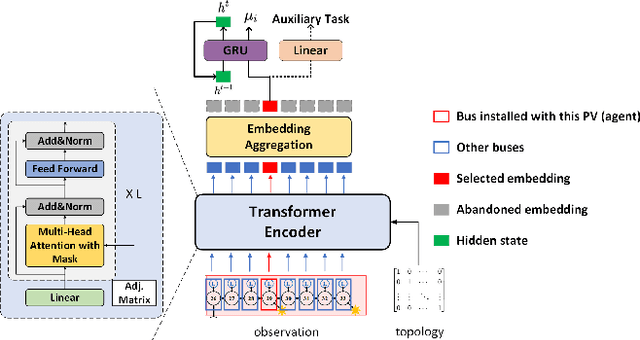
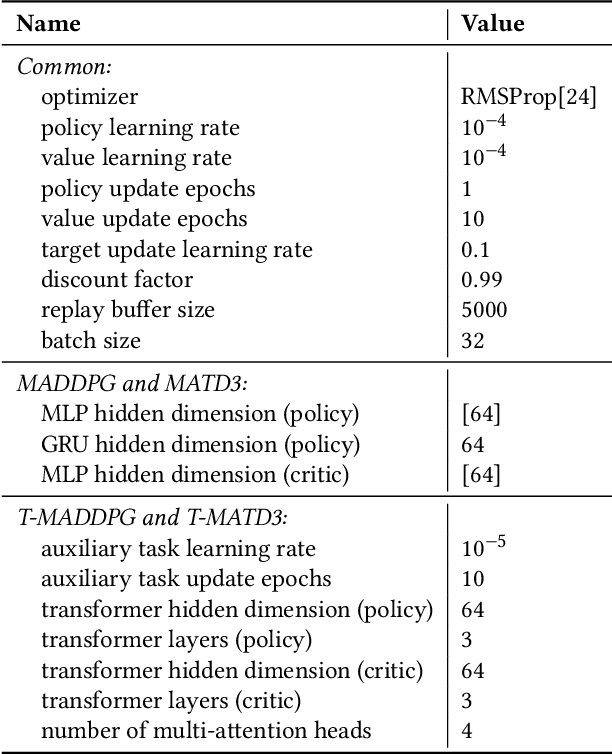
The increased integration of renewable energy poses a slew of technical challenges for the operation of power distribution networks. Among them, voltage fluctuations caused by the instability of renewable energy are receiving increasing attention. Utilizing MARL algorithms to coordinate multiple control units in the grid, which is able to handle rapid changes of power systems, has been widely studied in active voltage control task recently. However, existing approaches based on MARL ignore the unique nature of the grid and achieve limited performance. In this paper, we introduce the transformer architecture to extract representations adapting to power network problems and propose a Transformer-based Multi-Agent Actor-Critic framework (T-MAAC) to stabilize voltage in power distribution networks. In addition, we adopt a novel auxiliary-task training process tailored to the voltage control task, which improves the sample efficiency and facilitating the representation learning of the transformer-based model. We couple T-MAAC with different multi-agent actor-critic algorithms, and the consistent improvements on the active voltage control task demonstrate the effectiveness of the proposed method.