 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Rethinking Stateful Tool Use in Multi-Turn Dialogues: Benchmarks and Challenges
May 19, 2025Existing benchmarks that assess Language Models (LMs) as Language Agents (LAs) for tool use primarily focus on stateless, single-turn interactions or partial evaluations, such as tool selection in a single turn, overlooking the inherent stateful nature of interactions in multi-turn applications. To fulfill this gap, we propose \texttt{DialogTool}, a multi-turn dialogue dataset with stateful tool interactions considering the whole life cycle of tool use, across six key tasks in three stages: 1) \textit{tool creation}; 2) \textit{tool utilization}: tool awareness, tool selection, tool execution; and 3) \textit{role-consistent response}: response generation and role play. Furthermore, we build \texttt{VirtualMobile} -- an embodied virtual mobile evaluation environment to simulate API calls and assess the robustness of the created APIs\footnote{We will use tools and APIs alternatively, there are no significant differences between them in this paper.}. Taking advantage of these artifacts, we conduct comprehensive evaluation on 13 distinct open- and closed-source LLMs and provide detailed analysis at each stage, revealing that the existing state-of-the-art LLMs still cannot perform well to use tools over long horizons.
Model Merging in Pre-training of Large Language Models
May 17, 2025Model merging has emerged as a promising technique for enhancing large language models, though its application in large-scale pre-training remains relatively unexplored. In this paper, we present a comprehensive investigation of model merging techniques during the pre-training process. Through extensive experiments with both dense and Mixture-of-Experts (MoE) architectures ranging from millions to over 100 billion parameters, we demonstrate that merging checkpoints trained with constant learning rates not only achieves significant performance improvements but also enables accurate prediction of annealing behavior. These improvements lead to both more efficient model development and significantly lower training costs. Our detailed ablation studies on merging strategies and hyperparameters provide new insights into the underlying mechanisms while uncovering novel applications. Through comprehensive experimental analysis, we offer the open-source community practical pre-training guidelines for effective model merging.
Efficient Pretraining Length Scaling
Apr 21, 2025Recent advances in large language models have demonstrated the effectiveness of length scaling during post-training, yet its potential in pre-training remains underexplored. We present the Parallel Hidden Decoding Transformer (\textit{PHD}-Transformer), a novel framework that enables efficient length scaling during pre-training while maintaining inference efficiency. \textit{PHD}-Transformer achieves this through an innovative KV cache management strategy that distinguishes between original tokens and hidden decoding tokens. By retaining only the KV cache of original tokens for long-range dependencies while immediately discarding hidden decoding tokens after use, our approach maintains the same KV cache size as the vanilla transformer while enabling effective length scaling. To further enhance performance, we introduce two optimized variants: \textit{PHD-SWA} employs sliding window attention to preserve local dependencies, while \textit{PHD-CSWA} implements chunk-wise sliding window attention to eliminate linear growth in pre-filling time. Extensive experiments demonstrate consistent improvements across multiple benchmarks.
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Apr 15, 2025We introduce Kimina-Prover Preview, a large language model that pioneers a novel reasoning-driven exploration paradigm for formal theorem proving, as showcased in this preview release. Trained with a large-scale reinforcement learning pipeline from Qwen2.5-72B, Kimina-Prover demonstrates strong performance in Lean 4 proof generation by employing a structured reasoning pattern we term \textit{formal reasoning pattern}. This approach allows the model to emulate human problem-solving strategies in Lean, iteratively generating and refining proof steps. Kimina-Prover sets a new state-of-the-art on the miniF2F benchmark, reaching 80.7% with pass@8192. Beyond improved benchmark performance, our work yields several key insights: (1) Kimina-Prover exhibits high sample efficiency, delivering strong results even with minimal sampling (pass@1) and scaling effectively with computational budget, stemming from its unique reasoning pattern and RL training; (2) we demonstrate clear performance scaling with model size, a trend previously unobserved for neural theorem provers in formal mathematics; (3) the learned reasoning style, distinct from traditional search algorithms, shows potential to bridge the gap between formal verification and informal mathematical intuition. We open source distilled versions with 1.5B and 7B parameters of Kimina-Prover
FlexPrefill: A Context-Aware Sparse Attention Mechanism for Efficient Long-Sequence Inference
Feb 28, 2025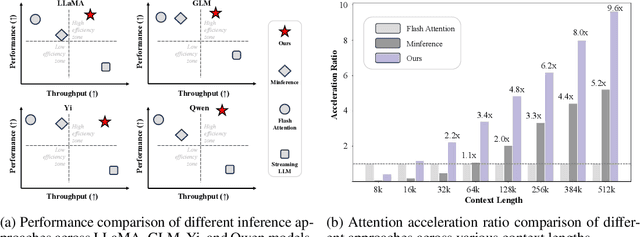



Large language models (LLMs) encounter computational challenges during long-sequence inference, especially in the attention pre-filling phase, where the complexity grows quadratically with the prompt length. Previous efforts to mitigate these challenges have relied on fixed sparse attention patterns or identifying sparse attention patterns based on limited cases. However, these methods lacked the flexibility to efficiently adapt to varying input demands. In this paper, we introduce FlexPrefill, a Flexible sparse Pre-filling mechanism that dynamically adjusts sparse attention patterns and computational budget in real-time to meet the specific requirements of each input and attention head. The flexibility of our method is demonstrated through two key innovations: 1) Query-Aware Sparse Pattern Determination: By measuring Jensen-Shannon divergence, this component adaptively switches between query-specific diverse attention patterns and predefined attention patterns. 2) Cumulative-Attention Based Index Selection: This component dynamically selects query-key indexes to be computed based on different attention patterns, ensuring the sum of attention scores meets a predefined threshold. FlexPrefill adaptively optimizes the sparse pattern and sparse ratio of each attention head based on the prompt, enhancing efficiency in long-sequence inference tasks. Experimental results show significant improvements in both speed and accuracy over prior methods, providing a more flexible and efficient solution for LLM inference.
FormalAlign: Automated Alignment Evaluation for Autoformalization
Oct 14, 2024



Autoformalization aims to convert informal mathematical proofs into machine-verifiable formats, bridging the gap between natural and formal languages. However, ensuring semantic alignment between the informal and formalized statements remains challenging. Existing approaches heavily rely on manual verification, hindering scalability. To address this, we introduce \textsc{FormalAlign}, the first automated framework designed for evaluating the alignment between natural and formal languages in autoformalization. \textsc{FormalAlign} trains on both the autoformalization sequence generation task and the representational alignment between input and output, employing a dual loss that combines a pair of mutually enhancing autoformalization and alignment tasks. Evaluated across four benchmarks augmented by our proposed misalignment strategies, \textsc{FormalAlign} demonstrates superior performance. In our experiments, \textsc{FormalAlign} outperforms GPT-4, achieving an Alignment-Selection Score 11.58\% higher on \forml-Basic (99.21\% vs. 88.91\%) and 3.19\% higher on MiniF2F-Valid (66.39\% vs. 64.34\%). This effective alignment evaluation significantly reduces the need for manual verification. Both the dataset and code can be accessed via~\url{https://github.com/rookie-joe/FormalAlign}.
Scaling Laws for Mixed quantization in Large Language Models
Oct 09, 2024



Post-training quantization of Large Language Models (LLMs) has proven effective in reducing the computational requirements for running inference on these models. In this study, we focus on a straightforward question: When aiming for a specific accuracy or perplexity target for low-precision quantization, how many high-precision numbers or calculations are required to preserve as we scale LLMs to larger sizes? We first introduce a critical metric named the quantization ratio, which compares the number of parameters quantized to low-precision arithmetic against the total parameter count. Through extensive and carefully controlled experiments across different model families, arithmetic types, and quantization granularities (e.g. layer-wise, matmul-wise), we identify two central phenomenons. 1) The larger the models, the better they can preserve performance with an increased quantization ratio, as measured by perplexity in pre-training tasks or accuracy in downstream tasks. 2) The finer the granularity of mixed-precision quantization (e.g., matmul-wise), the more the model can increase the quantization ratio. We believe these observed phenomena offer valuable insights for future AI hardware design and the development of advanced Efficient AI algorithms.
UNComp: Uncertainty-Aware Long-Context Compressor for Efficient Large Language Model Inference
Oct 04, 2024



Deploying large language models (LLMs) is challenging due to their high memory and computational demands, especially during long-context inference. While key-value (KV) caching accelerates inference by reusing previously computed keys and values, it also introduces significant memory overhead. Existing KV cache compression methods such as eviction and merging typically compress the KV cache after it is generated and overlook the eviction of hidden states, failing to improve the speed of the prefilling stage. Additionally, applying a uniform compression rate across different attention heads can harm crucial retrieval heads in needle-in-a-haystack tasks due to excessive compression. In this paper, we propose UNComp, an uncertainty-aware compression scheme that leverages matrix entropy to estimate model uncertainty across layers and heads at the token sequence level. By grouping layers and heads based on their uncertainty, UNComp adaptively compresses both the hidden states and the KV cache. Our method achieves a 1.6x speedup in the prefilling stage and reduces the KV cache to 4.74% of its original size, resulting in a 6.4x increase in throughput and a 1.4x speedup in inference with only a 1.41% performance loss. Remarkably, in needle-in-a-haystack tasks, UNComp outperforms the full-size KV cache even when compressed to 9.38% of its original size. Our approach offers an efficient, training-free Grouped-Query Attention paradigm that can be seamlessly integrated into existing KV cache schemes.
UncertaintyRAG: Span-Level Uncertainty Enhanced Long-Context Modeling for Retrieval-Augmented Generation
Oct 03, 2024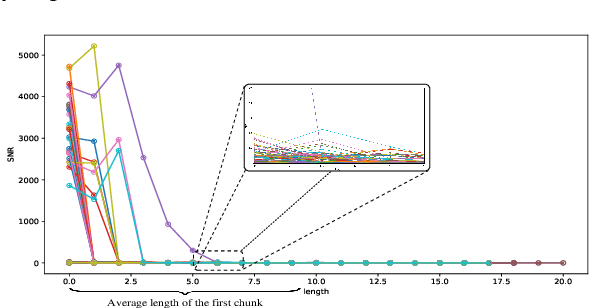
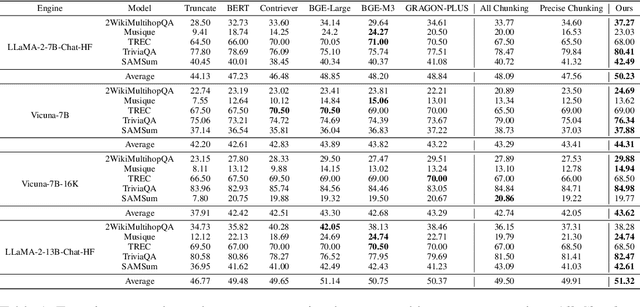


We present UncertaintyRAG, a novel approach for long-context Retrieval-Augmented Generation (RAG) that utilizes Signal-to-Noise Ratio (SNR)-based span uncertainty to estimate similarity between text chunks. This span uncertainty enhances model calibration, improving robustness and mitigating semantic inconsistencies introduced by random chunking. Leveraging this insight, we propose an efficient unsupervised learning technique to train the retrieval model, alongside an effective data sampling and scaling strategy. UncertaintyRAG outperforms baselines by 2.03% on LLaMA-2-7B, achieving state-of-the-art results while using only 4% of the training data compared to other advanced open-source retrieval models under distribution shift settings. Our method demonstrates strong calibration through span uncertainty, leading to improved generalization and robustness in long-context RAG tasks. Additionally, UncertaintyRAG provides a lightweight retrieval model that can be integrated into any large language model with varying context window lengths, without the need for fine-tuning, showcasing the flexibility of our approach.