 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scaling: Agents Are Heading to the Edge
May 18, 2026The bottleneck of useful agentic intelligence has shifted from compressing world knowledge into a single model to executing a coordinated system. This position paper argues that personal-agent architecture must move to the edge because the core properties of agentic intelligence tasks, particularly their structural coupling with high-fidelity local context and the need for zero-latency execution loops, do not sit well with cloud-centric designs. We develop this claim through three structural shifts. First, the Prefrontal Turn: the main marginal lever of capability has moved from pre-training scale to framework-level executive control. Such control must remain physically close to the environment of action if the agent is to preserve cognitive alignment. Second, the Data-Geography Paradox, the ``dark matter'' of agentic data (local file hierarchies, real-time sensor streams, and transient OS states) degrades, disappears, or loses meaning once prepared for cloud transmission, thereby cutting the agent off from ground-truth context. Third, the interaction-alignment loop, the only economically and ecologically sustainable source of agentic refinement data is the high-fidelity implicit preference signal produced through real-time local interaction. Third, the interaction-alignment loop, the only economically and ecologically sustainable source of agentic refinement data is the high-fidelity implicit preference signal produced through real-time local interaction. We conclude with falsifiable predictions for the next deployment cycle of personal agents.
AGSC: Adaptive Granularity and Semantic Clustering for Uncertainty Quantification in Long-text Generation
Apr 08, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in long-form generation, yet their application is hindered by the hallucination problem. While Uncertainty Quantification (UQ) is essential for assessing reliability, the complex structure makes reliable aggregation across heterogeneous themes difficult, in addition, existing methods often overlook the nuance of neutral information and suffer from the high computational cost of fine-grained decomposition. To address these challenges, we propose AGSC (Adaptive Granularity and GMM-based Semantic Clustering), a UQ framework tailored for long-form generation. AGSC first uses NLI neutral probabilities as triggers to distinguish irrelevance from uncertainty, reducing unnecessary computation. It then applies Gaussian Mixture Model (GMM) soft clustering to model latent semantic themes and assign topic-aware weights for downstream aggregation. Experiments on BIO and LongFact show that AGSC achieves state-of-the-art correlation with factuality while reducing inference time by about 60% compared to full atomic decomposition.
Learning to Solve Complex Problems via Dataset Decomposition
Feb 23, 2026Curriculum learning is a class of training strategies that organizes the data being exposed to a model by difficulty, gradually from simpler to more complex examples. This research explores a reverse curriculum generation approach that recursively decomposes complex datasets into simpler, more learnable components. We propose a teacher-student framework where the teacher is equipped with the ability to reason step-by-step, which is used to recursively generate easier versions of examples, enabling the student model to progressively master difficult tasks. We propose a novel scoring system to measure data difficulty based on its structural complexity and conceptual depth, allowing curriculum construction over decomposed data. Experiments on math datasets (MATH and AIME) and code generation datasets demonstrate that models trained with curricula generated by our approach exhibit superior performance compared to standard training on original datasets.
TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior
Dec 23, 2025Tokenizers provide the fundamental basis through which text is represented and processed by language models (LMs). Despite the importance of tokenization, its role in LM performance and behavior is poorly understood due to the challenge of measuring the impact of tokenization in isolation. To address this need, we present TokSuite, a collection of models and a benchmark that supports research into tokenization's influence on LMs. Specifically, we train fourteen models that use different tokenizers but are otherwise identical using the same architecture, dataset, training budget, and initialization. Additionally, we curate and release a new benchmark that specifically measures model performance subject to real-world perturbations that are likely to influence tokenization. Together, TokSuite allows robust decoupling of the influence of a model's tokenizer, supporting a series of novel findings that elucidate the respective benefits and shortcomings of a wide range of popular tokenizers.
Exploring Code Language Models for Automated HLS-based Hardware Generation: Benchmark, Infrastructure and Analysis
Feb 19, 2025Recent advances in code generation have illuminated the potential of employing large language models (LLMs) for general-purpose programming languages such as Python and C++, opening new opportunities for automating software development and enhancing programmer productivity. The potential of LLMs in software programming has sparked significant interest in exploring automated hardware generation and automation. Although preliminary endeavors have been made to adopt LLMs in generating hardware description languages (HDLs), several challenges persist in this direction. First, the volume of available HDL training data is substantially smaller compared to that for software programming languages. Second, the pre-trained LLMs, mainly tailored for software code, tend to produce HDL designs that are more error-prone. Third, the generation of HDL requires a significantly higher number of tokens compared to software programming, leading to inefficiencies in cost and energy consumption. To tackle these challenges, this paper explores leveraging LLMs to generate High-Level Synthesis (HLS)-based hardware design. Although code generation for domain-specific programming languages is not new in the literature, we aim to provide experimental results, insights, benchmarks, and evaluation infrastructure to investigate the suitability of HLS over low-level HDLs for LLM-assisted hardware design generation. To achieve this, we first finetune pre-trained models for HLS-based hardware generation, using a collected dataset with text prompts and corresponding reference HLS designs. An LLM-assisted framework is then proposed to automate end-to-end hardware code generation, which also investigates the impact of chain-of-thought and feedback loops promoting techniques on HLS-design generation. Limited by the timeframe of this research, we plan to evaluate more advanced reasoning models in the future.
Photon: Federated LLM Pre-Training
Nov 05, 2024



Scaling large language models (LLMs) demands extensive data and computing resources, which are traditionally constrained to data centers by the high-bandwidth requirements of distributed training. Low-bandwidth methods like federated learning (FL) could enable collaborative training of larger models across weakly-connected GPUs if they can effectively be used for pre-training. To achieve this, we introduce Photon, the first complete system for federated end-to-end LLM training, leveraging cross-silo FL for global-scale training with minimal communication overheads. Using Photon, we train the first federated family of decoder-only LLMs from scratch. We show that: (1) Photon can train model sizes up to 7B in a federated fashion while reaching an even better perplexity than centralized pre-training; (2) Photon model training time decreases with available compute, achieving a similar compute-time trade-off to centralized; and (3) Photon outperforms the wall-time of baseline distributed training methods by 35% via communicating 64x-512xless. Our proposal is robust to data heterogeneity and converges twice as fast as previous methods like DiLoCo. This surprising data efficiency stems from a unique approach combining small client batch sizes with extremely high learning rates, enabled by federated averaging's robustness to hyperparameters. Photon thus represents the first economical system for global internet-wide LLM pre-training.
Prompt Tuning with Diffusion for Few-Shot Pre-trained Policy Generalization
Nov 02, 2024



Offline reinforcement learning (RL) methods harness previous experiences to derive an optimal policy, forming the foundation for pre-trained large-scale models (PLMs). When encountering tasks not seen before, PLMs often utilize several expert trajectories as prompts to expedite their adaptation to new requirements. Though a range of prompt-tuning methods have been proposed to enhance the quality of prompts, these methods often face optimization restrictions due to prompt initialization, which can significantly constrain the exploration domain and potentially lead to suboptimal solutions. To eliminate the reliance on the initial prompt, we shift our perspective towards the generative model, framing the prompt-tuning process as a form of conditional generative modeling, where prompts are generated from random noise. Our innovation, the Prompt Diffuser, leverages a conditional diffusion model to produce prompts of exceptional quality. Central to our framework is the approach to trajectory reconstruction and the meticulous integration of downstream task guidance during the training phase. Further experimental results underscore the potency of the Prompt Diffuser as a robust and effective tool for the prompt-tuning process, demonstrating strong performance in the meta-RL tasks.
Data Quality Control in Federated Instruction-tuning of Large Language Models
Oct 15, 2024
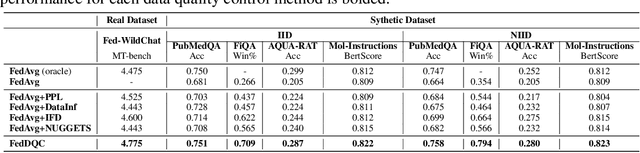
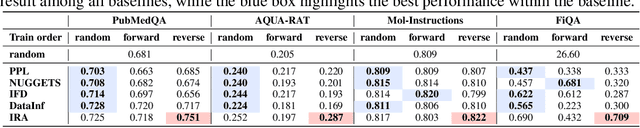

By leveraging massively distributed data, federated learning (FL) enables collaborative instruction tuning of large language models (LLMs) in a privacy-preserving way. While FL effectively expands the data quantity, the issue of data quality remains under-explored in the current literature on FL for LLMs. To address this gap, we propose a new framework of federated instruction tuning of LLMs with data quality control (FedDQC), which measures data quality to facilitate the subsequent filtering and hierarchical training processes. Our approach introduces an efficient metric to assess each client's instruction-response alignment (IRA), identifying potentially noisy data through single-shot inference. Low-IRA samples are potentially noisy and filtered to mitigate their negative impacts. To further utilize this IRA value, we propose a quality-aware hierarchical training paradigm, where LLM is progressively fine-tuned from high-IRA to low-IRA data, mirroring the easy-to-hard learning process. We conduct extensive experiments on 4 synthetic and a real-world dataset, and compare our method with baselines adapted from centralized setting. Results show that our method consistently and significantly improves the performance of LLMs trained on mix-quality data in FL.
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024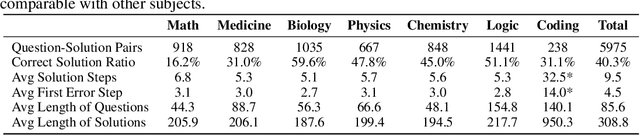
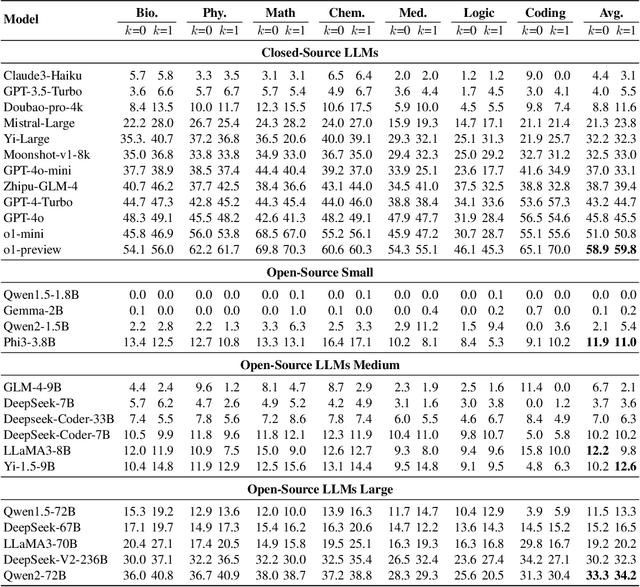
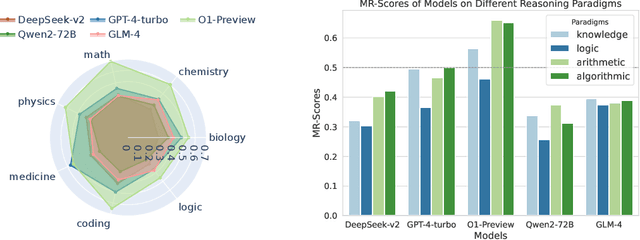
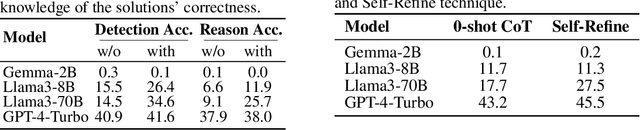
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
The Future of Large Language Model Pre-training is Federated
May 17, 2024



Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.