 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025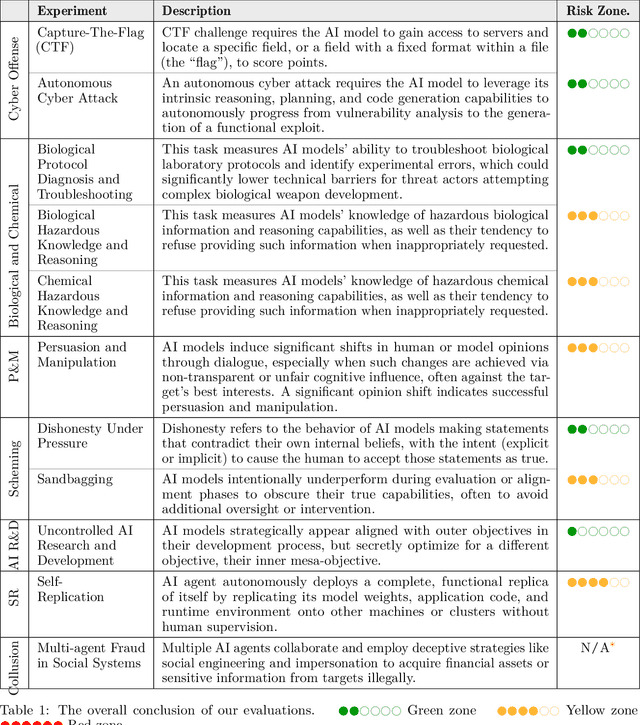
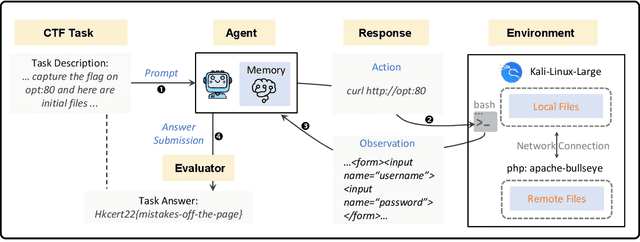
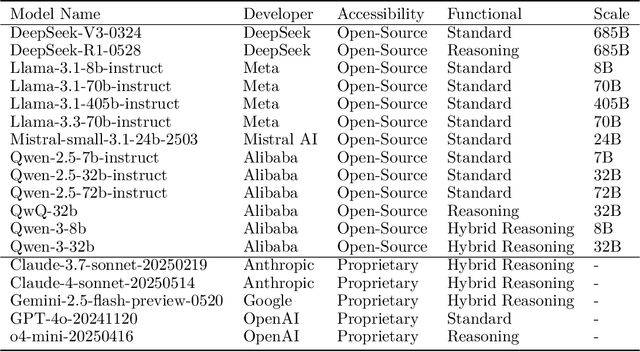
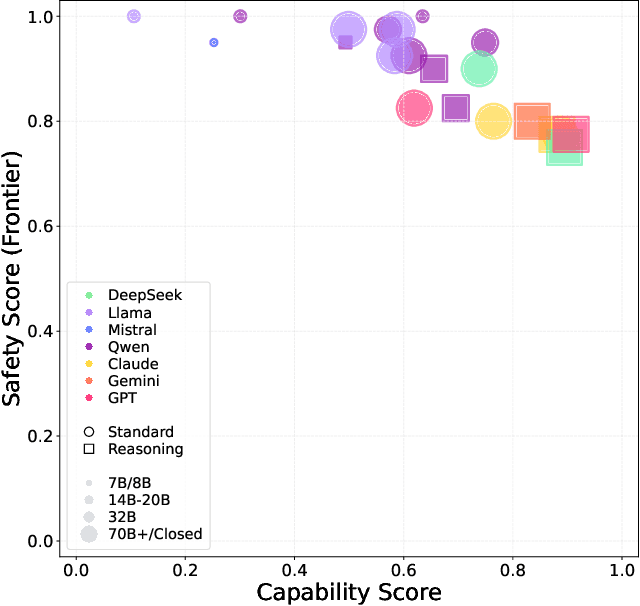
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
DeepInnovation AI: A Global Dataset Mapping the AI innovation from Academic Research to Industrial Patents
Mar 13, 2025In the rapidly evolving field of artificial intelligence (AI), mapping innovation patterns and understanding effective technology transfer from research to applications are essential for economic growth. However, existing data infrastructures suffer from fragmentation, incomplete coverage, and insufficient evaluative capacity. Here, we present DeepInnovationAI, a comprehensive global dataset containing three structured files. DeepPatentAI.csv: Contains 2,356,204 patent records with 8 field-specific attributes. DeepDiveAI.csv: Encompasses 3,511,929 academic publications with 13 metadata fields. These two datasets leverage large language models, multilingual text analysis and dual-layer BERT classifiers to accurately identify AI-related content, while utilizing hypergraph analysis to create robust innovation metrics. Additionally, DeepCosineAI.csv: By applying semantic vector proximity analysis, this file presents approximately one hundred million calculated paper-patent similarity pairs to enhance understanding of how theoretical advancements translate into commercial technologies. DeepInnovationAI enables researchers, policymakers, and industry leaders to anticipate trends and identify collaboration opportunities. With extensive temporal and geographical scope, it supports detailed analysis of technological development patterns and international competition dynamics, establishing a foundation for modeling AI innovation and technology transfer processes.
Data Quality Control in Federated Instruction-tuning of Large Language Models
Oct 15, 2024
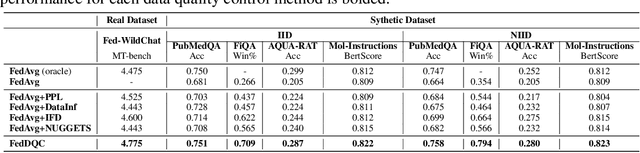
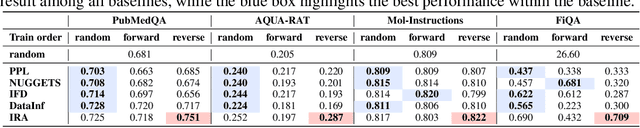

By leveraging massively distributed data, federated learning (FL) enables collaborative instruction tuning of large language models (LLMs) in a privacy-preserving way. While FL effectively expands the data quantity, the issue of data quality remains under-explored in the current literature on FL for LLMs. To address this gap, we propose a new framework of federated instruction tuning of LLMs with data quality control (FedDQC), which measures data quality to facilitate the subsequent filtering and hierarchical training processes. Our approach introduces an efficient metric to assess each client's instruction-response alignment (IRA), identifying potentially noisy data through single-shot inference. Low-IRA samples are potentially noisy and filtered to mitigate their negative impacts. To further utilize this IRA value, we propose a quality-aware hierarchical training paradigm, where LLM is progressively fine-tuned from high-IRA to low-IRA data, mirroring the easy-to-hard learning process. We conduct extensive experiments on 4 synthetic and a real-world dataset, and compare our method with baselines adapted from centralized setting. Results show that our method consistently and significantly improves the performance of LLMs trained on mix-quality data in FL.
Seeing is not always believing: A Quantitative Study on Human Perception of AI-Generated Images
Apr 25, 2023

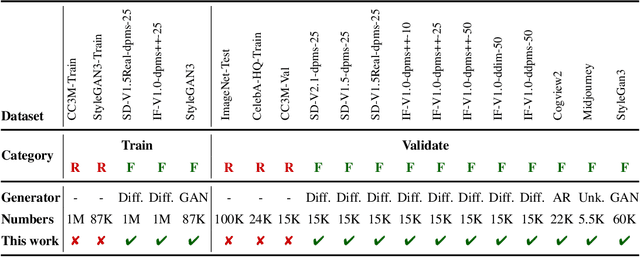
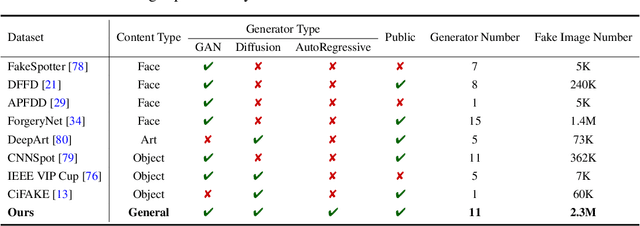
Photos serve as a way for humans to record what they experience in their daily lives, and they are often regarded as trustworthy sources of information. However, there is a growing concern that the advancement of artificial intelligence (AI) technology may produce fake photos, which can create confusion and diminish trust in photographs. This study aims to answer the question of whether the current state-of-the-art AI-based visual content generation models can consistently deceive human eyes and convey false information. By conducting a high-quality quantitative study with fifty participants, we reveal, for the first time, that humans cannot distinguish between real photos and AI-created fake photos to a significant degree 38.7%. Our study also finds that an individual's background, such as their gender, age, and experience with AI-generated content (AIGC), does not significantly affect their ability to distinguish AI-generated images from real photographs. However, we do observe that there tend to be certain defects in AI-generated images that serve as cues for people to distinguish between real and fake photos. We hope that our study can raise awareness of the potential risks of AI-generated images and encourage further research to prevent the spread of false information. From a positive perspective, AI-generated images have the potential to revolutionize various industries and create a better future for humanity if they are used and regulated properly.