 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInnovation AI: A Global Dataset Mapping the AI innovation from Academic Research to Industrial Patents
Mar 13, 2025In the rapidly evolving field of artificial intelligence (AI), mapping innovation patterns and understanding effective technology transfer from research to applications are essential for economic growth. However, existing data infrastructures suffer from fragmentation, incomplete coverage, and insufficient evaluative capacity. Here, we present DeepInnovationAI, a comprehensive global dataset containing three structured files. DeepPatentAI.csv: Contains 2,356,204 patent records with 8 field-specific attributes. DeepDiveAI.csv: Encompasses 3,511,929 academic publications with 13 metadata fields. These two datasets leverage large language models, multilingual text analysis and dual-layer BERT classifiers to accurately identify AI-related content, while utilizing hypergraph analysis to create robust innovation metrics. Additionally, DeepCosineAI.csv: By applying semantic vector proximity analysis, this file presents approximately one hundred million calculated paper-patent similarity pairs to enhance understanding of how theoretical advancements translate into commercial technologies. DeepInnovationAI enables researchers, policymakers, and industry leaders to anticipate trends and identify collaboration opportunities. With extensive temporal and geographical scope, it supports detailed analysis of technological development patterns and international competition dynamics, establishing a foundation for modeling AI innovation and technology transfer processes.
An Alternating Manifold Proximal Gradient Method for Sparse PCA and Sparse CCA
Mar 27, 2019

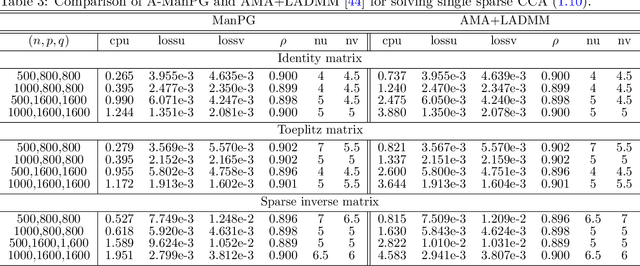
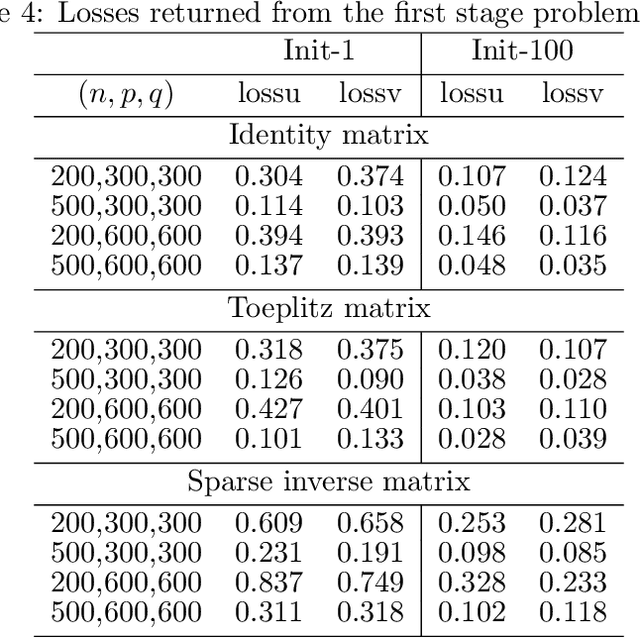
Sparse principal component analysis (PCA) and sparse canonical correlation analysis (CCA) are two essential techniques from high-dimensional statistics and machine learning for analyzing large-scale data. Both problems can be formulated as an optimization problem with nonsmooth objective and nonconvex constraints. Since non-smoothness and nonconvexity bring numerical difficulties, most algorithms suggested in the literature either solve some relaxations or are heuristic and lack convergence guarantees. In this paper, we propose a new alternating manifold proximal gradient method to solve these two high-dimensional problems and provide a unified convergence analysis. Numerical experiment results are reported to demonstrate the advantages of our algorithm.
Another Look at DWD: Thrifty Algorithm and Bayes Risk Consistency in RKHS
Aug 24, 2015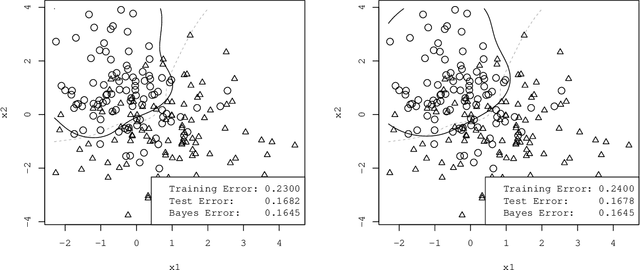

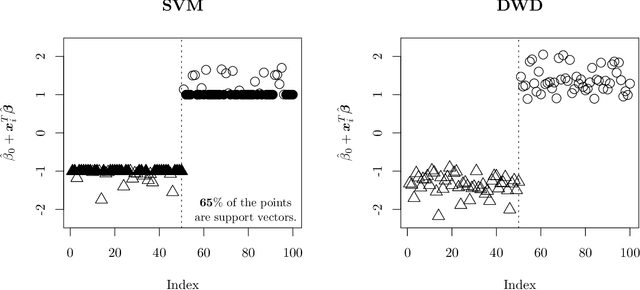
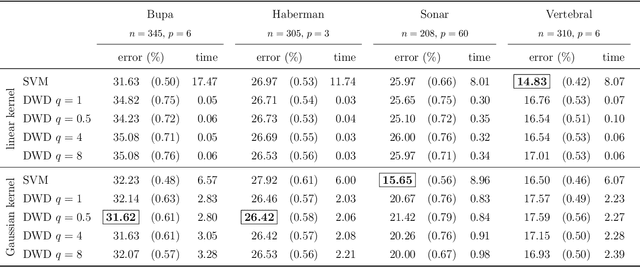
Distance weighted discrimination (DWD) is a margin-based classifier with an interesting geometric motivation. DWD was originally proposed as a superior alternative to the support vector machine (SVM), however DWD is yet to be popular compared with the SVM. The main reasons are twofold. First, the state-of-the-art algorithm for solving DWD is based on the second-order-cone programming (SOCP), while the SVM is a quadratic programming problem which is much more efficient to solve. Second, the current statistical theory of DWD mainly focuses on the linear DWD for the high-dimension-low-sample-size setting and data-piling, while the learning theory for the SVM mainly focuses on the Bayes risk consistency of the kernel SVM. In fact, the Bayes risk consistency of DWD is presented as an open problem in the original DWD paper. In this work, we advance the current understanding of DWD from both computational and theoretical perspectives. We propose a novel efficient algorithm for solving DWD, and our algorithm can be several hundred times faster than the existing state-of-the-art algorithm based on the SOCP. In addition, our algorithm can handle the generalized DWD, while the SOCP algorithm only works well for a special DWD but not the generalized DWD. Furthermore, we consider a natural kernel DWD in a reproducing kernel Hilbert space and then establish the Bayes risk consistency of the kernel DWD. We compare DWD and the SVM on several benchmark data sets and show that the two have comparable classification accuracy, but DWD equipped with our new algorithm can be much faster to compute than the SVM.
Strong oracle optimality of folded concave penalized estimation
Apr 02, 2015

Folded concave penalization methods have been shown to enjoy the strong oracle property for high-dimensional sparse estimation. However, a folded concave penalization problem usually has multiple local solutions and the oracle property is established only for one of the unknown local solutions. A challenging fundamental issue still remains that it is not clear whether the local optimum computed by a given optimization algorithm possesses those nice theoretical properties. To close this important theoretical gap in over a decade, we provide a unified theory to show explicitly how to obtain the oracle solution via the local linear approximation algorithm. For a folded concave penalized estimation problem, we show that as long as the problem is localizable and the oracle estimator is well behaved, we can obtain the oracle estimator by using the one-step local linear approximation. In addition, once the oracle estimator is obtained, the local linear approximation algorithm converges, namely it produces the same estimator in the next iteration. The general theory is demonstrated by using four classical sparse estimation problems, that is, sparse linear regression, sparse logistic regression, sparse precision matrix estimation and sparse quantile regression.
* Published in at http://dx.doi.org/10.1214/13-AOS1198 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org). With Corrections
Sparse Distance Weighted Discrimination
Jan 24, 2015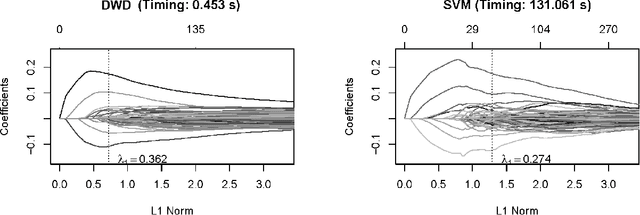
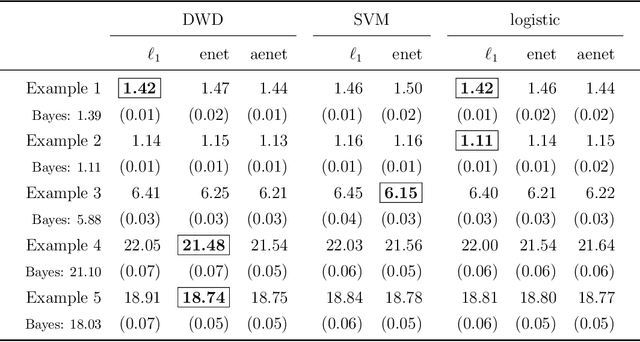

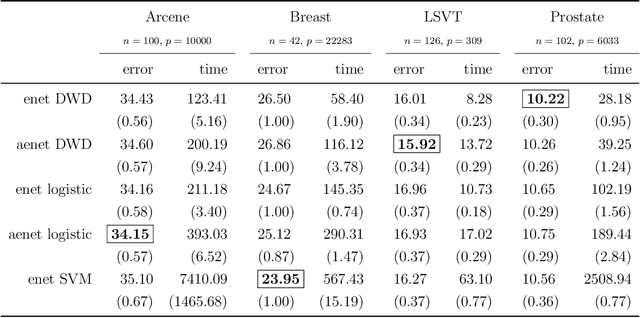
Distance weighted discrimination (DWD) was originally proposed to handle the data piling issue in the support vector machine. In this paper, we consider the sparse penalized DWD for high-dimensional classification. The state-of-the-art algorithm for solving the standard DWD is based on second-order cone programming, however such an algorithm does not work well for the sparse penalized DWD with high-dimensional data. In order to overcome the challenging computation difficulty, we develop a very efficient algorithm to compute the solution path of the sparse DWD at a given fine grid of regularization parameters. We implement the algorithm in a publicly available R package sdwd. We conduct extensive numerical experiments to demonstrate the computational efficiency and classification performance of our method.
High Dimensional Semiparametric Latent Graphical Model for Mixed Data
Apr 29, 2014


Graphical models are commonly used tools for modeling multivariate random variables. While there exist many convenient multivariate distributions such as Gaussian distribution for continuous data, mixed data with the presence of discrete variables or a combination of both continuous and discrete variables poses new challenges in statistical modeling. In this paper, we propose a semiparametric model named latent Gaussian copula model for binary and mixed data. The observed binary data are assumed to be obtained by dichotomizing a latent variable satisfying the Gaussian copula distribution or the nonparanormal distribution. The latent Gaussian model with the assumption that the latent variables are multivariate Gaussian is a special case of the proposed model. A novel rank-based approach is proposed for both latent graph estimation and latent principal component analysis. Theoretically, the proposed methods achieve the same rates of convergence for both precision matrix estimation and eigenvector estimation, as if the latent variables were observed. Under similar conditions, the consistency of graph structure recovery and feature selection for leading eigenvectors is established. The performance of the proposed methods is numerically assessed through simulation studies, and the usage of our methods is illustrated by a genetic dataset.
Alternating Direction Methods for Latent Variable Gaussian Graphical Model Selection
Sep 26, 2012Chandrasekaran, Parrilo and Willsky (2010) proposed a convex optimization problem to characterize graphical model selection in the presence of unobserved variables. This convex optimization problem aims to estimate an inverse covariance matrix that can be decomposed into a sparse matrix minus a low-rank matrix from sample data. Solving this convex optimization problem is very challenging, especially for large problems. In this paper, we propose two alternating direction methods for solving this problem. The first method is to apply the classical alternating direction method of multipliers to solve the problem as a consensus problem. The second method is a proximal gradient based alternating direction method of multipliers. Our methods exploit and take advantage of the special structure of the problem and thus can solve large problems very efficiently. Global convergence result is established for the proposed methods. Numerical results on both synthetic data and gene expression data show that our methods usually solve problems with one million variables in one to two minutes, and are usually five to thirty five times faster than a state-of-the-art Newton-CG proximal point algorithm.
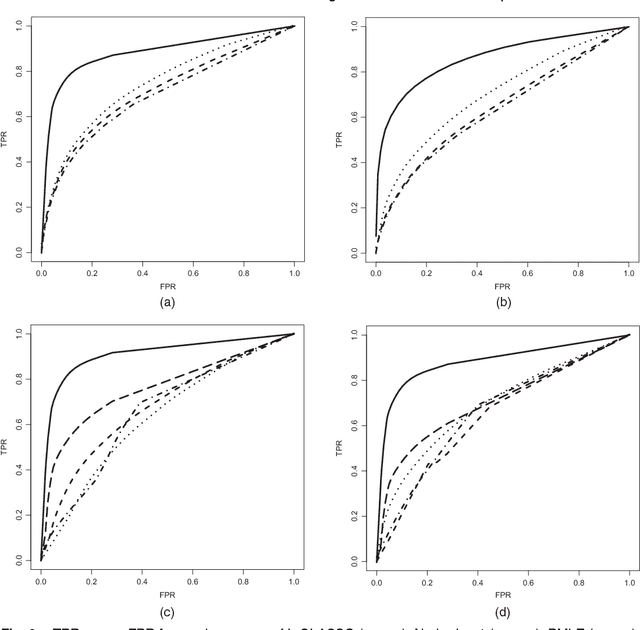
Structured variable selection in support vector machines
Feb 22, 2008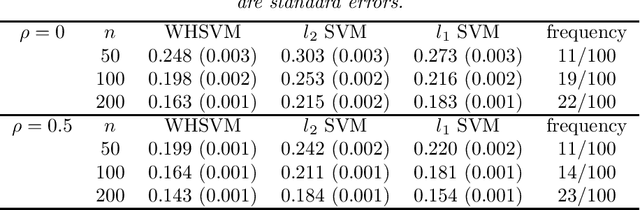

When applying the support vector machine (SVM) to high-dimensional classification problems, we often impose a sparse structure in the SVM to eliminate the influences of the irrelevant predictors. The lasso and other variable selection techniques have been successfully used in the SVM to perform automatic variable selection. In some problems, there is a natural hierarchical structure among the variables. Thus, in order to have an interpretable SVM classifier, it is important to respect the heredity principle when enforcing the sparsity in the SVM. Many variable selection methods, however, do not respect the heredity principle. In this paper we enforce both sparsity and the heredity principle in the SVM by using the so-called structured variable selection (SVS) framework originally proposed in Yuan, Joseph and Zou (2007). We minimize the empirical hinge loss under a set of linear inequality constraints and a lasso-type penalty. The solution always obeys the desired heredity principle and enjoys sparsity. The new SVM classifier can be efficiently fitted, because the optimization problem is a linear program. Another contribution of this work is to present a nonparametric extension of the SVS framework, and we propose nonparametric heredity SVMs. Simulated and real data are used to illustrate the merits of the proposed method.
* Published in at http://dx.doi.org/10.1214/07-EJS125 the Electronic Journal of Statistics (http://www.i-journals.org/ejs/) by the Institute of Mathematical Statistics (http://www.imstat.org)