 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Control in Federated Instruction-tuning of Large Language Models
Oct 15, 2024
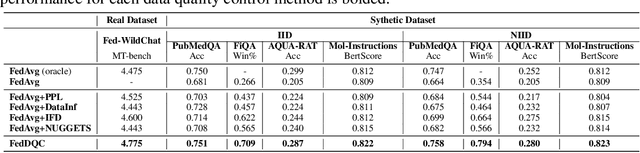
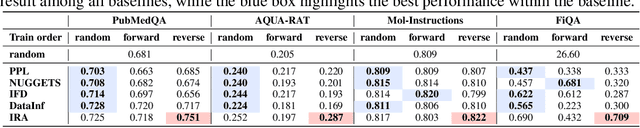

By leveraging massively distributed data, federated learning (FL) enables collaborative instruction tuning of large language models (LLMs) in a privacy-preserving way. While FL effectively expands the data quantity, the issue of data quality remains under-explored in the current literature on FL for LLMs. To address this gap, we propose a new framework of federated instruction tuning of LLMs with data quality control (FedDQC), which measures data quality to facilitate the subsequent filtering and hierarchical training processes. Our approach introduces an efficient metric to assess each client's instruction-response alignment (IRA), identifying potentially noisy data through single-shot inference. Low-IRA samples are potentially noisy and filtered to mitigate their negative impacts. To further utilize this IRA value, we propose a quality-aware hierarchical training paradigm, where LLM is progressively fine-tuned from high-IRA to low-IRA data, mirroring the easy-to-hard learning process. We conduct extensive experiments on 4 synthetic and a real-world dataset, and compare our method with baselines adapted from centralized setting. Results show that our method consistently and significantly improves the performance of LLMs trained on mix-quality data in FL.