 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Memorization for Efficient Long Context Generation
May 18, 2026Modern large language model (LLM) applications increasingly rely on long conditioning prefixes to control model behavior at inference time. While prefix-augmented inference is effective, it incurs two structural limitations: i) the prefix's influence fades as generation proceeds, and ii) attention computation over the prefix scales linearly with its length. Existing approaches either keep the prefix in attention while compressing it, or internalize it into model parameters through gradient-based training. The former still attends to the prefix at inference, while the latter is training-intensive and ill-suited to prefix updates. To address these issues, we propose attention-state memory, a training-free approach that externalizes the prefix into a lightweight, lookup-based memory of precomputed attention states between prefix and query tokens. On ManyICLBench with LLaMA-3.1-8B, our method improves accuracy over in-context learning at 1K-8K memory budgets while reducing attention latency by 1.36x at 8K, and surpasses full-attention RAG performance on NBA benchmark using only 20% of its memory footprint.
Dynamic Expert Sharing: Decoupling Memory from Parallelism in Mixture-of-Experts Diffusion LLMs
Jan 31, 2026Among parallel decoding paradigms, diffusion large language models (dLLMs) have emerged as a promising candidate that balances generation quality and throughput. However, their integration with Mixture-of-Experts (MoE) architectures is constrained by an expert explosion: as the number of tokens generated in parallel increases, the number of distinct experts activated grows nearly linearly. This results in substantial memory traffic that pushes inference into a memory-bound regime, negating the efficiency gains of both MoE and parallel decoding. To address this challenge, we propose Dynamic Expert Sharing (DES), a novel technique that shifts MoE optimization from token-centric pruning and conventional expert skipping methods to sequence-level coreset selection. To maximize expert reuse, DES identifies a compact, high-utility set of experts to satisfy the requirements of an entire parallel decoding block. We introduce two innovative selection strategies: (1) Intra-Sequence Sharing (DES-Seq), which adapts optimal allocation to the sequence level, and (2) Saliency-Aware Voting (DES-Vote), a novel mechanism that allows tokens to collectively elect a coreset based on aggregated router weights. Extensive experiments on MoE dLLMs demonstrate that DES reduces unique expert activations by over 55% and latency by up to 38%, while retaining 99% of vanilla accuracy, effectively decoupling memory overhead from the degree of parallelism.
Accelerating 3D Gaussian Splatting with Neural Sorting and Axis-Oriented Rasterization
Jun 08, 2025



3D Gaussian Splatting (3DGS) has recently gained significant attention for high-quality and efficient view synthesis, making it widely adopted in fields such as AR/VR, robotics, and autonomous driving. Despite its impressive algorithmic performance, real-time rendering on resource-constrained devices remains a major challenge due to tight power and area budgets. This paper presents an architecture-algorithm co-design to address these inefficiencies. First, we reveal substantial redundancy caused by repeated computation of common terms/expressions during the conventional rasterization. To resolve this, we propose axis-oriented rasterization, which pre-computes and reuses shared terms along both the X and Y axes through a dedicated hardware design, effectively reducing multiply-and-add (MAC) operations by up to 63%. Second, by identifying the resource and performance inefficiency of the sorting process, we introduce a novel neural sorting approach that predicts order-independent blending weights using an efficient neural network, eliminating the need for costly hardware sorters. A dedicated training framework is also proposed to improve its algorithmic stability. Third, to uniformly support rasterization and neural network inference, we design an efficient reconfigurable processing array that maximizes hardware utilization and throughput. Furthermore, we introduce a $\pi$-trajectory tile schedule, inspired by Morton encoding and Hilbert curve, to optimize Gaussian reuse and reduce memory access overhead. Comprehensive experiments demonstrate that the proposed design preserves rendering quality while achieving a speedup of $23.4\sim27.8\times$ and energy savings of $28.8\sim51.4\times$ compared to edge GPUs for real-world scenes. We plan to open-source our design to foster further development in this field.
Rethinking Optimal Verification Granularity for Compute-Efficient Test-Time Scaling
May 16, 2025Test-time scaling (TTS) has proven effective in enhancing the reasoning capabilities of large language models (LLMs). Verification plays a key role in TTS, simultaneously influencing (1) reasoning performance and (2) compute efficiency, due to the quality and computational cost of verification. In this work, we challenge the conventional paradigms of verification, and make the first attempt toward systematically investigating the impact of verification granularity-that is, how frequently the verifier is invoked during generation, beyond verifying only the final output or individual generation steps. To this end, we introduce Variable Granularity Search (VG-Search), a unified algorithm that generalizes beam search and Best-of-N sampling via a tunable granularity parameter g. Extensive experiments with VG-Search under varying compute budgets, generator-verifier configurations, and task attributes reveal that dynamically selecting g can improve the compute efficiency and scaling behavior. Building on these findings, we propose adaptive VG-Search strategies that achieve accuracy gains of up to 3.1\% over Beam Search and 3.6\% over Best-of-N, while reducing FLOPs by over 52\%. We will open-source the code to support future research.
FW-Merging: Scaling Model Merging with Frank-Wolfe Optimization
Mar 16, 2025Model merging has emerged as a promising approach for multi-task learning (MTL), offering a data-efficient alternative to conventional fine-tuning. However, with the rapid development of the open-source AI ecosystem and the increasing availability of fine-tuned foundation models, existing model merging methods face two key limitations: (i) They are primarily designed for in-house fine-tuned models, making them less adaptable to diverse model sources with partially unknown model and task information, (ii) They struggle to scale effectively when merging numerous model checkpoints. To address these challenges, we formulate model merging as a constrained optimization problem and introduce a novel approach: Frank-Wolfe Merging (FW-Merging). Inspired by Frank-Wolfe optimization, our approach iteratively selects the most relevant model in the pool to minimize a linear approximation of the objective function and then executes a local merging similar to the Frank-Wolfe update. The objective function is designed to capture the desired behavior of the target-merged model, while the fine-tuned candidate models define the constraint set. More importantly, FW-Merging serves as an orthogonal technique for existing merging methods, seamlessly integrating with them to further enhance accuracy performance. Our experiments show that FW-Merging scales across diverse model sources, remaining stable with 16 irrelevant models and improving by 15.3% with 16 relevant models on 20 CV tasks, while maintaining constant memory overhead, unlike the linear overhead of data-informed merging methods. Compared with the state-of-the-art approaches, FW-Merging surpasses the data-free merging method by 32.8% and outperforms the data-informed Adamerging by 8.39% when merging 20 ViT models.
Exploring Code Language Models for Automated HLS-based Hardware Generation: Benchmark, Infrastructure and Analysis
Feb 19, 2025Recent advances in code generation have illuminated the potential of employing large language models (LLMs) for general-purpose programming languages such as Python and C++, opening new opportunities for automating software development and enhancing programmer productivity. The potential of LLMs in software programming has sparked significant interest in exploring automated hardware generation and automation. Although preliminary endeavors have been made to adopt LLMs in generating hardware description languages (HDLs), several challenges persist in this direction. First, the volume of available HDL training data is substantially smaller compared to that for software programming languages. Second, the pre-trained LLMs, mainly tailored for software code, tend to produce HDL designs that are more error-prone. Third, the generation of HDL requires a significantly higher number of tokens compared to software programming, leading to inefficiencies in cost and energy consumption. To tackle these challenges, this paper explores leveraging LLMs to generate High-Level Synthesis (HLS)-based hardware design. Although code generation for domain-specific programming languages is not new in the literature, we aim to provide experimental results, insights, benchmarks, and evaluation infrastructure to investigate the suitability of HLS over low-level HDLs for LLM-assisted hardware design generation. To achieve this, we first finetune pre-trained models for HLS-based hardware generation, using a collected dataset with text prompts and corresponding reference HLS designs. An LLM-assisted framework is then proposed to automate end-to-end hardware code generation, which also investigates the impact of chain-of-thought and feedback loops promoting techniques on HLS-design generation. Limited by the timeframe of this research, we plan to evaluate more advanced reasoning models in the future.
MetaML-Pro: Cross-Stage Design Flow Automation for Efficient Deep Learning Acceleration
Feb 09, 2025This paper presents a unified framework for codifying and automating optimization strategies to efficiently deploy deep neural networks (DNNs) on resource-constrained hardware, such as FPGAs, while maintaining high performance, accuracy, and resource efficiency. Deploying DNNs on such platforms involves addressing the significant challenge of balancing performance, resource usage (e.g., DSPs and LUTs), and inference accuracy, which often requires extensive manual effort and domain expertise. Our novel approach addresses two key issues: cross-stage co-optimization and optimization search. By seamlessly integrating programmatic DNN optimization techniques with high-level synthesis (HLS)-based metaprogramming and leveraging advanced design space exploration (DSE) strategies like Bayesian optimization, the framework automates both top-down and bottom-up design flows, reducing the need for manual intervention and domain expertise. The proposed framework introduces customizable optimization, transformation, and control blocks to enhance DNN accelerator performance and resource efficiency. Experimental results demonstrate up to a 92\% DSP and 89\% LUT usage reduction for select networks, while preserving accuracy, along with a 15.6-fold reduction in optimization time compared to grid search. These results underscore the novelty and potential of the proposed framework for automated, resource-efficient DNN accelerator designs.
Progressive Mixed-Precision Decoding for Efficient LLM Inference
Oct 17, 2024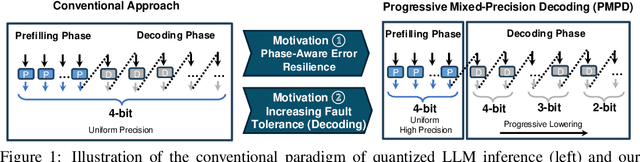
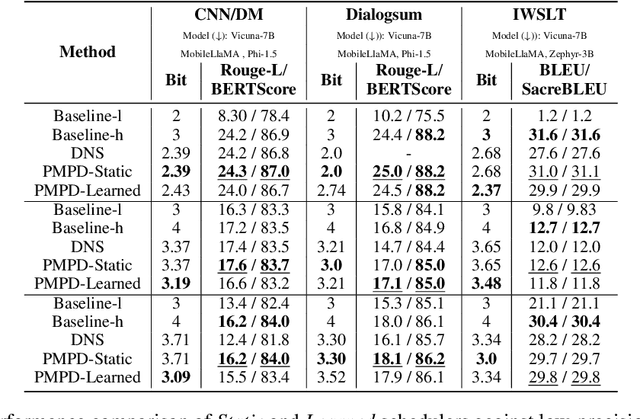
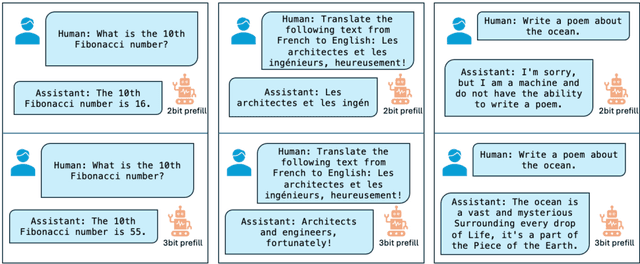
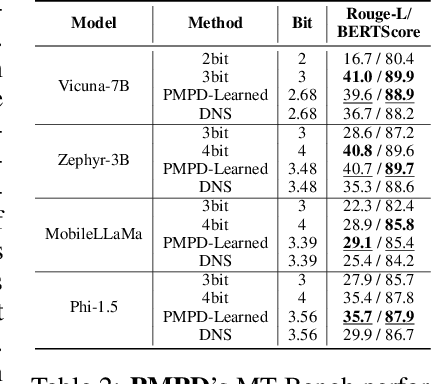
In spite of the great potential of large language models (LLMs) across various tasks, their deployment on resource-constrained devices remains challenging due to their excessive computational and memory demands. Quantization has emerged as an effective solution by storing weights in reduced precision. However, utilizing low precisions (i.e.~2/3-bit) to substantially alleviate the memory-boundedness of LLM decoding, still suffers from prohibitive performance drop. In this work, we argue that existing approaches fail to explore the diversity in computational patterns, redundancy, and sensitivity to approximations of the different phases of LLM inference, resorting to a uniform quantization policy throughout. Instead, we propose a novel phase-aware method that selectively allocates precision during different phases of LLM inference, achieving both strong context extraction during prefill and efficient memory bandwidth utilization during decoding. To further address the memory-boundedness of the decoding phase, we introduce Progressive Mixed-Precision Decoding (PMPD), a technique that enables the gradual lowering of precision deeper in the generated sequence, together with a spectrum of precision-switching schedulers that dynamically drive the precision-lowering decisions in either task-adaptive or prompt-adaptive manner. Extensive evaluation across diverse language tasks shows that when targeting Nvidia GPUs, PMPD achieves 1.4$-$12.2$\times$ speedup in matrix-vector multiplications over fp16 models, while when targeting an LLM-optimized NPU, our approach delivers a throughput gain of 3.8$-$8.0$\times$ over fp16 models and up to 1.54$\times$ over uniform quantization approaches while preserving the output quality.
Accelerating MRI Uncertainty Estimation with Mask-based Bayesian Neural Network
Jul 07, 2024Accurate and reliable Magnetic Resonance Imaging (MRI) analysis is particularly important for adaptive radiotherapy, a recent medical advance capable of improving cancer diagnosis and treatment. Recent studies have shown that IVIM-NET, a deep neural network (DNN), can achieve high accuracy in MRI analysis, indicating the potential of deep learning to enhance diagnostic capabilities in healthcare. However, IVIM-NET does not provide calibrated uncertainty information needed for reliable and trustworthy predictions in healthcare. Moreover, the expensive computation and memory demands of IVIM-NET reduce hardware performance, hindering widespread adoption in realistic scenarios. To address these challenges, this paper proposes an algorithm-hardware co-optimization flow for high-performance and reliable MRI analysis. At the algorithm level, a transformation design flow is introduced to convert IVIM-NET to a mask-based Bayesian Neural Network (BayesNN), facilitating reliable and efficient uncertainty estimation. At the hardware level, we propose an FPGA-based accelerator with several hardware optimizations, such as mask-zero skipping and operation reordering. Experimental results demonstrate that our co-design approach can satisfy the uncertainty requirements of MRI analysis, while achieving 7.5 times and 32.5 times speedup on an Xilinx VU13P FPGA compared to GPU and CPU implementations with reduced power consumption.
Enhancing Dropout-based Bayesian Neural Networks with Multi-Exit on FPGA
Jun 24, 2024Reliable uncertainty estimation plays a crucial role in various safety-critical applications such as medical diagnosis and autonomous driving. In recent years, Bayesian neural networks (BayesNNs) have gained substantial research and industrial interests due to their capability to make accurate predictions with reliable uncertainty estimation. However, the algorithmic complexity and the resulting hardware performance of BayesNNs hinder their adoption in real-life applications. To bridge this gap, this paper proposes an algorithm and hardware co-design framework that can generate field-programmable gate array (FPGA)-based accelerators for efficient BayesNNs. At the algorithm level, we propose novel multi-exit dropout-based BayesNNs with reduced computational and memory overheads while achieving high accuracy and quality of uncertainty estimation. At the hardware level, this paper introduces a transformation framework that can generate FPGA-based accelerators for the proposed efficient multi-exit BayesNNs. Several optimization techniques such as the mix of spatial and temporal mappings are introduced to reduce resource consumption and improve the overall hardware performance. Comprehensive experiments demonstrate that our approach can achieve higher energy efficiency compared to CPU, GPU, and other state-of-the-art hardware implementations. To support the future development of this research, we have open-sourced our code at: https://github.com/os-hxfan/MCME_FPGA_Acc.git