 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Feature Aggregation or: How Policies Learn to Stop Worrying about Robustness and Attend to Task-Relevant Visual Cues
Nov 13, 2025The adoption of pre-trained visual representations (PVRs), leveraging features from large-scale vision models, has become a popular paradigm for training visuomotor policies. However, these powerful representations can encode a broad range of task-irrelevant scene information, making the resulting trained policies vulnerable to out-of-domain visual changes and distractors. In this work we address visuomotor policy feature pooling as a solution to the observed lack of robustness in perturbed scenes. We achieve this via Attentive Feature Aggregation (AFA), a lightweight, trainable pooling mechanism that learns to naturally attend to task-relevant visual cues, ignoring even semantically rich scene distractors. Through extensive experiments in both simulation and the real world, we demonstrate that policies trained with AFA significantly outperform standard pooling approaches in the presence of visual perturbations, without requiring expensive dataset augmentation or fine-tuning of the PVR. Our findings show that ignoring extraneous visual information is a crucial step towards deploying robust and generalisable visuomotor policies. Project Page: tsagkas.github.io/afa
Progressive Mixed-Precision Decoding for Efficient LLM Inference
Oct 17, 2024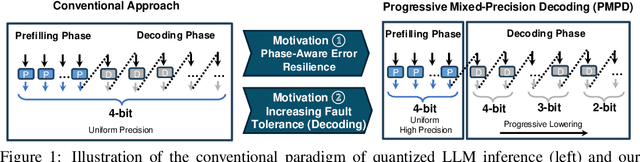
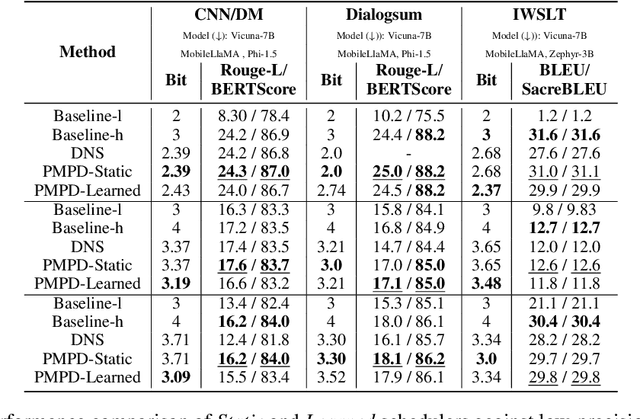
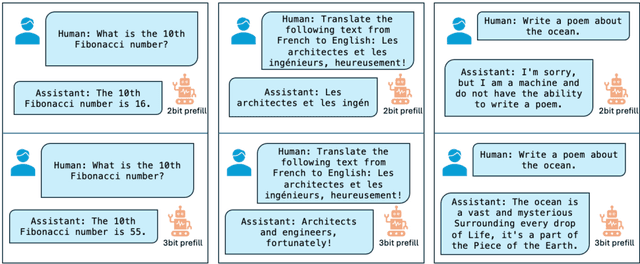
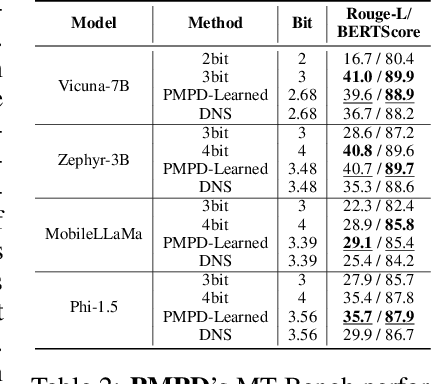
In spite of the great potential of large language models (LLMs) across various tasks, their deployment on resource-constrained devices remains challenging due to their excessive computational and memory demands. Quantization has emerged as an effective solution by storing weights in reduced precision. However, utilizing low precisions (i.e.~2/3-bit) to substantially alleviate the memory-boundedness of LLM decoding, still suffers from prohibitive performance drop. In this work, we argue that existing approaches fail to explore the diversity in computational patterns, redundancy, and sensitivity to approximations of the different phases of LLM inference, resorting to a uniform quantization policy throughout. Instead, we propose a novel phase-aware method that selectively allocates precision during different phases of LLM inference, achieving both strong context extraction during prefill and efficient memory bandwidth utilization during decoding. To further address the memory-boundedness of the decoding phase, we introduce Progressive Mixed-Precision Decoding (PMPD), a technique that enables the gradual lowering of precision deeper in the generated sequence, together with a spectrum of precision-switching schedulers that dynamically drive the precision-lowering decisions in either task-adaptive or prompt-adaptive manner. Extensive evaluation across diverse language tasks shows that when targeting Nvidia GPUs, PMPD achieves 1.4$-$12.2$\times$ speedup in matrix-vector multiplications over fp16 models, while when targeting an LLM-optimized NPU, our approach delivers a throughput gain of 3.8$-$8.0$\times$ over fp16 models and up to 1.54$\times$ over uniform quantization approaches while preserving the output quality.
Sparse-DySta: Sparsity-Aware Dynamic and Static Scheduling for Sparse Multi-DNN Workloads
Oct 17, 2023Running multiple deep neural networks (DNNs) in parallel has become an emerging workload in both edge devices, such as mobile phones where multiple tasks serve a single user for daily activities, and data centers, where various requests are raised from millions of users, as seen with large language models. To reduce the costly computational and memory requirements of these workloads, various efficient sparsification approaches have been introduced, resulting in widespread sparsity across different types of DNN models. In this context, there is an emerging need for scheduling sparse multi-DNN workloads, a problem that is largely unexplored in previous literature. This paper systematically analyses the use-cases of multiple sparse DNNs and investigates the opportunities for optimizations. Based on these findings, we propose Dysta, a novel bi-level dynamic and static scheduler that utilizes both static sparsity patterns and dynamic sparsity information for the sparse multi-DNN scheduling. Both static and dynamic components of Dysta are jointly designed at the software and hardware levels, respectively, to improve and refine the scheduling approach. To facilitate future progress in the study of this class of workloads, we construct a public benchmark that contains sparse multi-DNN workloads across different deployment scenarios, spanning from mobile phones and AR/VR wearables to data centers. A comprehensive evaluation on the sparse multi-DNN benchmark demonstrates that our proposed approach outperforms the state-of-the-art methods with up to 10% decrease in latency constraint violation rate and nearly 4X reduction in average normalized turnaround time. Our artifacts and code are publicly available at: https://github.com/SamsungLabs/Sparse-Multi-DNN-Scheduling.
The Future of Consumer Edge-AI Computing
Oct 19, 2022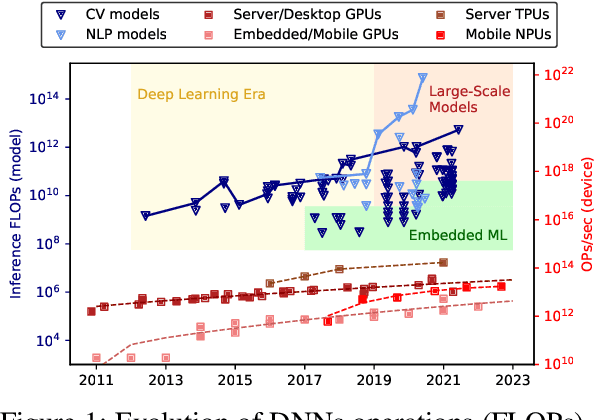
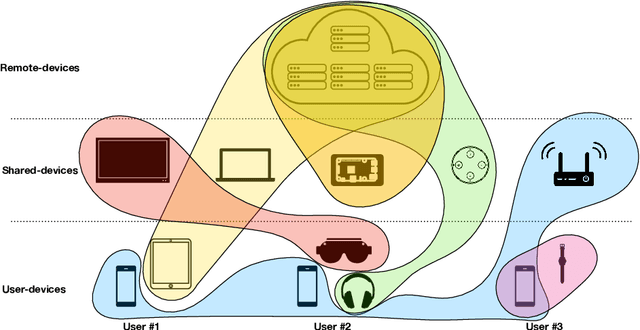

Deep Learning has proliferated dramatically across consumer devices in less than a decade, but has been largely powered through the hardware acceleration within isolated devices. Nonetheless, clear signals exist that the next decade of consumer intelligence will require levels of resources, a mixing of modalities and a collaboration of devices that will demand a significant pivot beyond hardware alone. To accomplish this, we believe a new Edge-AI paradigm will be necessary for this transition to be possible in a sustainable manner, without trespassing user-privacy or hurting quality of experience.
Fluid Batching: Exit-Aware Preemptive Serving of Early-Exit Neural Networks on Edge NPUs
Sep 27, 2022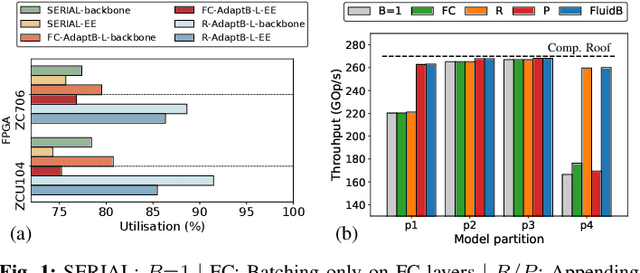
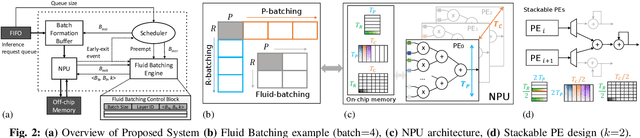
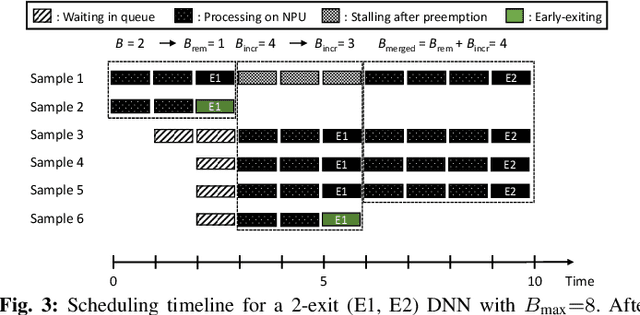
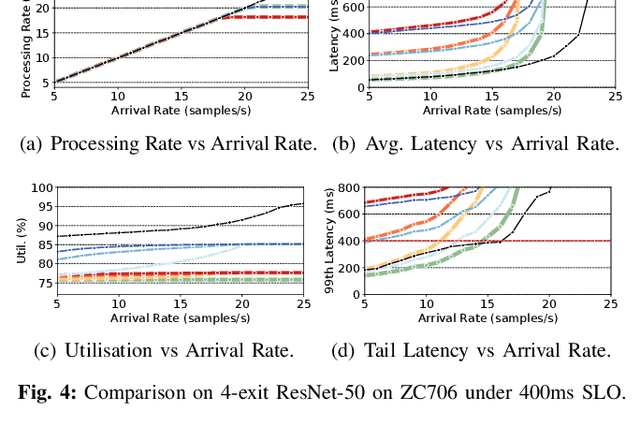
With deep neural networks (DNNs) emerging as the backbone in a multitude of computer vision tasks, their adoption in real-world consumer applications broadens continuously. Given the abundance and omnipresence of smart devices, "smart ecosystems" are being formed where sensing happens simultaneously rather than standalone. This is shifting the on-device inference paradigm towards deploying centralised neural processing units (NPUs) at the edge, where multiple devices (e.g. in smart homes or autonomous vehicles) can stream their data for processing with dynamic rates. While this provides enhanced potential for input batching, naive solutions can lead to subpar performance and quality of experience, especially under spiking loads. At the same time, the deployment of dynamic DNNs, comprising stochastic computation graphs (e.g. early-exit (EE) models), introduces a new dimension of dynamic behaviour in such systems. In this work, we propose a novel early-exit-aware scheduling algorithm that allows sample preemption at run time, to account for the dynamicity introduced both by the arrival and early-exiting processes. At the same time, we introduce two novel dimensions to the design space of the NPU hardware architecture, namely Fluid Batching and Stackable Processing Elements, that enable run-time adaptability to different batch sizes and significantly improve the NPU utilisation even at small batch sizes. Our evaluation shows that our system achieves an average 1.97x and 6.7x improvement over state-of-the-art DNN streaming systems in terms of average latency and tail latency SLO satisfaction, respectively.
Adaptable Butterfly Accelerator for Attention-based NNs via Hardware and Algorithm Co-design
Sep 20, 2022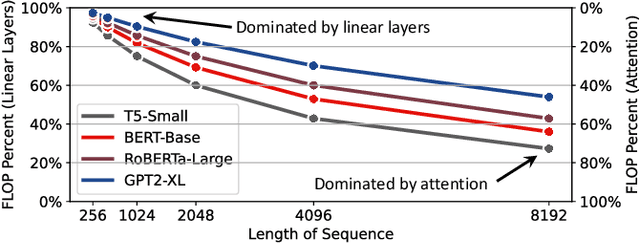
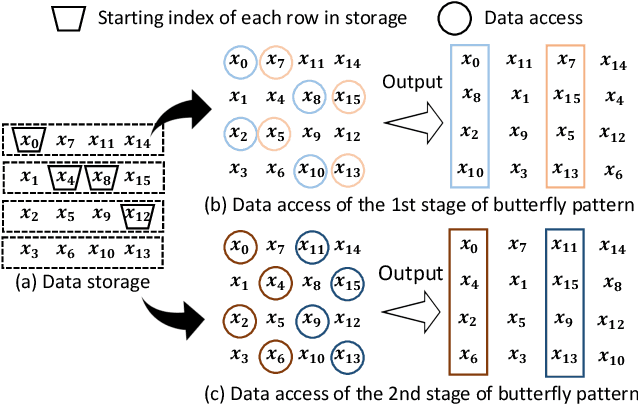
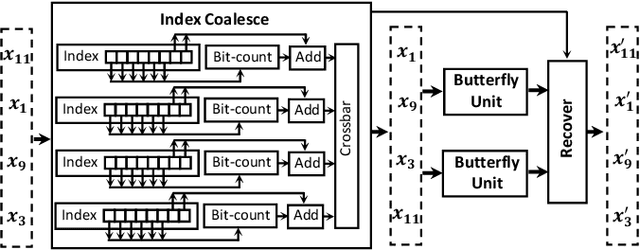
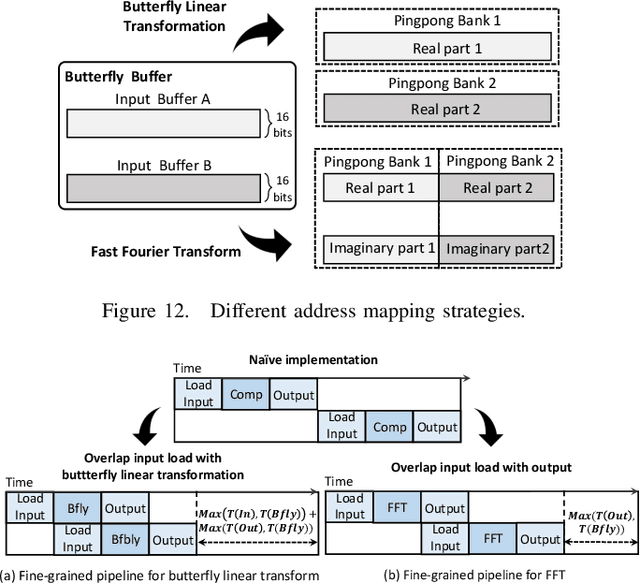
Attention-based neural networks have become pervasive in many AI tasks. Despite their excellent algorithmic performance, the use of the attention mechanism and feed-forward network (FFN) demands excessive computational and memory resources, which often compromises their hardware performance. Although various sparse variants have been introduced, most approaches only focus on mitigating the quadratic scaling of attention on the algorithm level, without explicitly considering the efficiency of mapping their methods on real hardware designs. Furthermore, most efforts only focus on either the attention mechanism or the FFNs but without jointly optimizing both parts, causing most of the current designs to lack scalability when dealing with different input lengths. This paper systematically considers the sparsity patterns in different variants from a hardware perspective. On the algorithmic level, we propose FABNet, a hardware-friendly variant that adopts a unified butterfly sparsity pattern to approximate both the attention mechanism and the FFNs. On the hardware level, a novel adaptable butterfly accelerator is proposed that can be configured at runtime via dedicated hardware control to accelerate different butterfly layers using a single unified hardware engine. On the Long-Range-Arena dataset, FABNet achieves the same accuracy as the vanilla Transformer while reducing the amount of computation by 10 to 66 times and the number of parameters 2 to 22 times. By jointly optimizing the algorithm and hardware, our FPGA-based butterfly accelerator achieves 14.2 to 23.2 times speedup over state-of-the-art accelerators normalized to the same computational budget. Compared with optimized CPU and GPU designs on Raspberry Pi 4 and Jetson Nano, our system is up to 273.8 and 15.1 times faster under the same power budget.
Adaptive Inference through Early-Exit Networks: Design, Challenges and Directions
Jun 09, 2021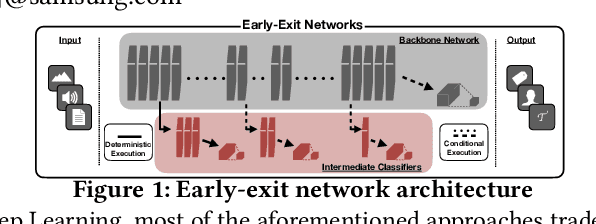
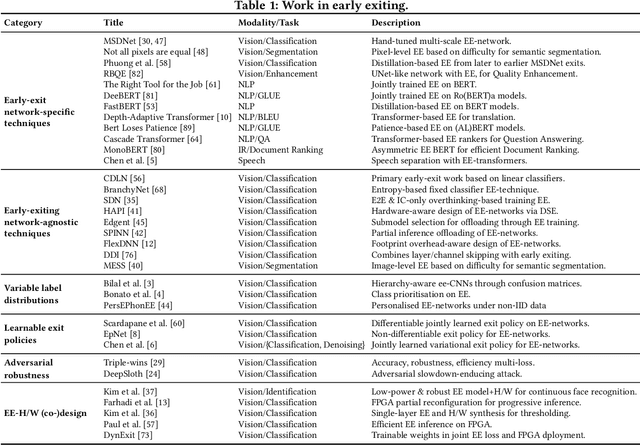
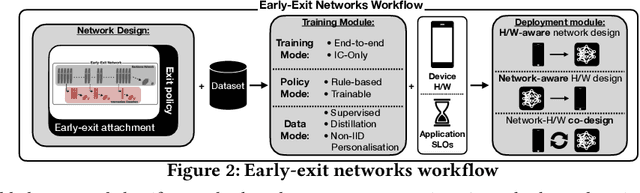
DNNs are becoming less and less over-parametrised due to recent advances in efficient model design, through careful hand-crafted or NAS-based methods. Relying on the fact that not all inputs require the same amount of computation to yield a confident prediction, adaptive inference is gaining attention as a prominent approach for pushing the limits of efficient deployment. Particularly, early-exit networks comprise an emerging direction for tailoring the computation depth of each input sample at runtime, offering complementary performance gains to other efficiency optimisations. In this paper, we decompose the design methodology of early-exit networks to its key components and survey the recent advances in each one of them. We also position early-exiting against other efficient inference solutions and provide our insights on the current challenges and most promising future directions for research in the field.
Multi-Exit Semantic Segmentation Networks
Jun 07, 2021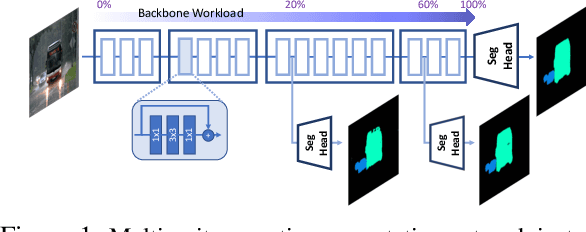


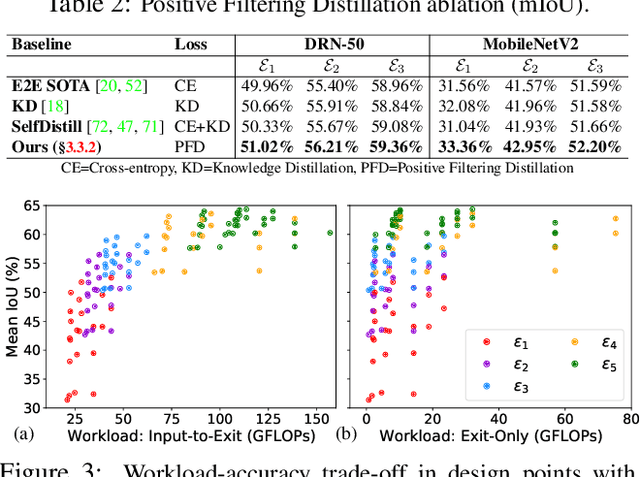
Semantic segmentation arises as the backbone of many vision systems, spanning from self-driving cars and robot navigation to augmented reality and teleconferencing. Frequently operating under stringent latency constraints within a limited resource envelope, optimising for efficient execution becomes important. To this end, we propose a framework for converting state-of-the-art segmentation models to MESS networks; specially trained CNNs that employ parametrised early exits along their depth to save computation during inference on easier samples. Designing and training such networks naively can hurt performance. Thus, we propose a two-staged training process that pushes semantically important features early in the network. We co-optimise the number, placement and architecture of the attached segmentation heads, along with the exit policy, to adapt to the device capabilities and application-specific requirements. Optimising for speed, MESS networks can achieve latency gains of up to 2.83x over state-of-the-art methods with no accuracy degradation. Accordingly, optimising for accuracy, we achieve an improvement of up to 5.33 pp, under the same computational budget.
Approximate LSTMs for Time-Constrained Inference: Enabling Fast Reaction in Self-Driving Cars
May 02, 2019


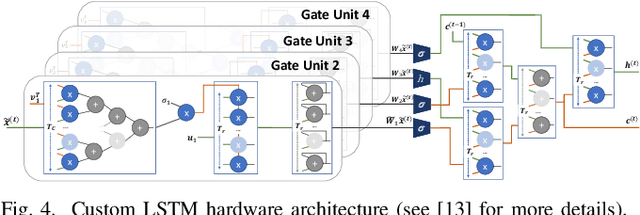
The need to recognise long-term dependencies in sequential data such as video streams has made LSTMs a prominent AI model for many emerging applications. However, the high computational and memory demands of LSTMs introduce challenges in their deployment on latency-critical systems such as self-driving cars which are equipped with limited computational resources on-board. In this paper, we introduce an approximate computing scheme combining model pruning and computation restructuring to obtain a high-accuracy approximation of the result in early stages of the computation. Our experiments demonstrate that using the proposed methodology, mission-critical systems responsible for autonomous navigation and collision avoidance are able to make informed decisions based on approximate calculations within the available time budget, meeting their specifications on safety and robustness.
CascadeCNN: Pushing the Performance Limits of Quantisation in Convolutional Neural Networks
Jul 13, 2018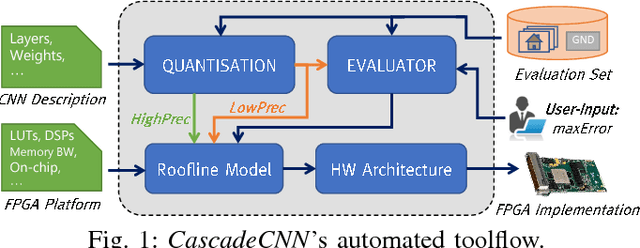
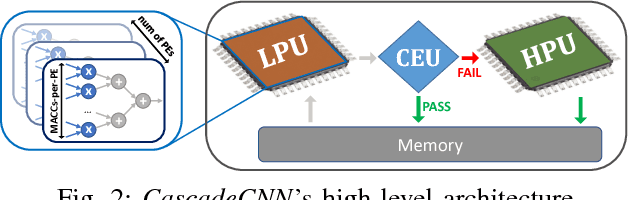
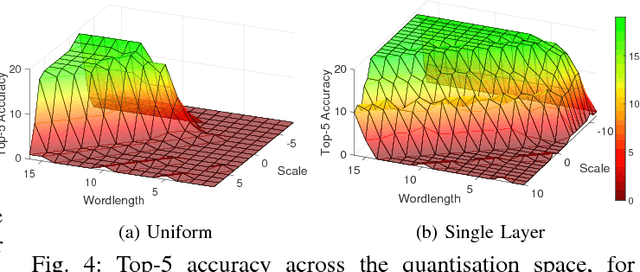
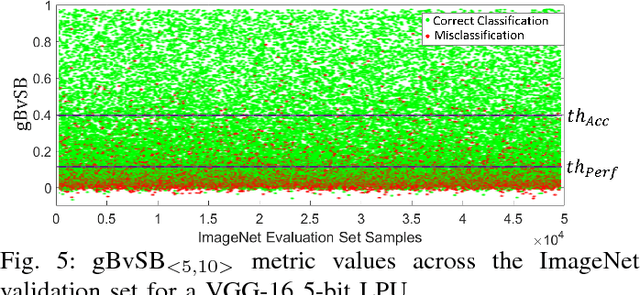
This work presents CascadeCNN, an automated toolflow that pushes the quantisation limits of any given CNN model, aiming to perform high-throughput inference. A two-stage architecture tailored for any given CNN-FPGA pair is generated, consisting of a low- and high-precision unit in a cascade. A confidence evaluation unit is employed to identify misclassified cases from the excessively low-precision unit and forward them to the high-precision unit for re-processing. Experiments demonstrate that the proposed toolflow can achieve a performance boost up to 55% for VGG-16 and 48% for AlexNet over the baseline design for the same resource budget and accuracy, without the need of retraining the model or accessing the training data.