 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGatedFWA: Linear Flash Windowed Attention with Gated Associative Memory
Dec 08, 2025Modern autoregressive models rely on attention, yet the Softmax full attention in Transformers scales quadratically with sequence length. Sliding Window Attention (SWA) achieves linear-time encoding/decoding by constraining the attention pattern, but under an \textit{Associative Memory} interpretation, its difference-style update renders the training objective effectively \emph{unbounded}. In contrast, Softmax attention normalizes updates, leading to \emph{memory shrinkage and gradient vanishing}. We propose GatedFWA: a Memory-\underline{Gated} (\underline{F}lash) \underline{W}indowed \underline{A}ttention mechanism that preserves SWAs efficiency while stabilizing memory updates and making gradient flow controllable. In essence, GatedFWA accumulate a per-token/head gate into a decay bias added to the attention logits, acting as a learnable contraction in the memory recurrence. We implement a fused one-pass gate preprocessing and a FlashAttention-compatible kernel that injects the gate under a sliding mask, ensuring I/O efficiency and numerical stability. On language modelling benchmarks, GatedFWA delivers competitive throughput with negligible overhead and better use of global context, and it integrates cleanly with token compression/selection methods such as NSA and generalizes to various autoregressive domains.
Cached Multi-Lora Composition for Multi-Concept Image Generation
Feb 07, 2025Low-Rank Adaptation (LoRA) has emerged as a widely adopted technique in text-to-image models, enabling precise rendering of multiple distinct elements, such as characters and styles, in multi-concept image generation. However, current approaches face significant challenges when composing these LoRAs for multi-concept image generation, resulting in diminished generated image quality. In this paper, we initially investigate the role of LoRAs in the denoising process through the lens of the Fourier frequency domain. Based on the hypothesis that applying multiple LoRAs could lead to "semantic conflicts", we find that certain LoRAs amplify high-frequency features such as edges and textures, whereas others mainly focus on low-frequency elements, including the overall structure and smooth color gradients. Building on these insights, we devise a frequency domain based sequencing strategy to determine the optimal order in which LoRAs should be integrated during inference. This strategy offers a methodical and generalizable solution compared to the naive integration commonly found in existing LoRA fusion techniques. To fully leverage our proposed LoRA order sequence determination method in multi-LoRA composition tasks, we introduce a novel, training-free framework, Cached Multi-LoRA (CMLoRA), designed to efficiently integrate multiple LoRAs while maintaining cohesive image generation. With its flexible backbone for multi-LoRA fusion and a non-uniform caching strategy tailored to individual LoRAs, CMLoRA has the potential to reduce semantic conflicts in LoRA composition and improve computational efficiency. Our experimental evaluations demonstrate that CMLoRA outperforms state-of-the-art training-free LoRA fusion methods by a significant margin -- it achieves an average improvement of $2.19\%$ in CLIPScore, and $11.25\%$ in MLLM win rate compared to LoraHub, LoRA Composite, and LoRA Switch.
HASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator
Jun 05, 2024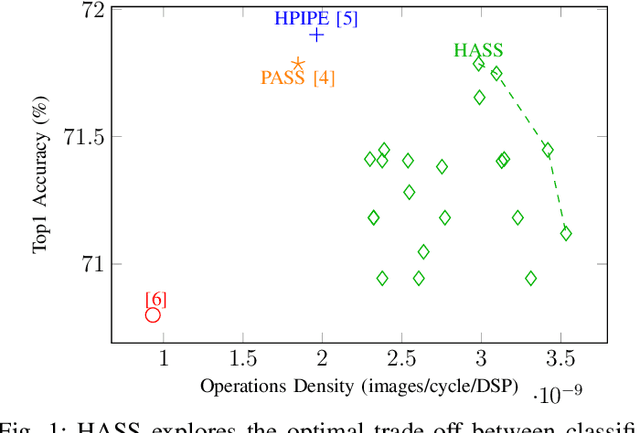
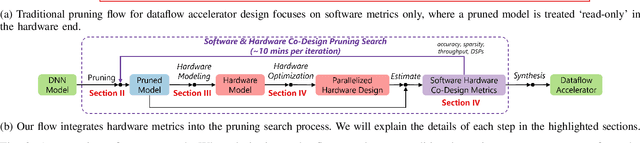
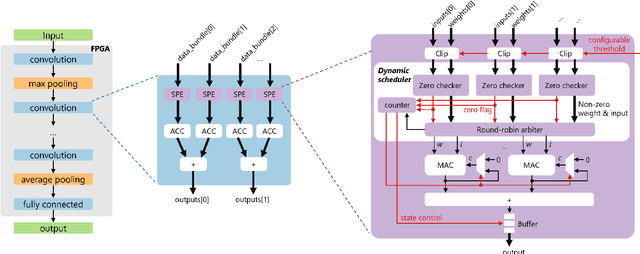
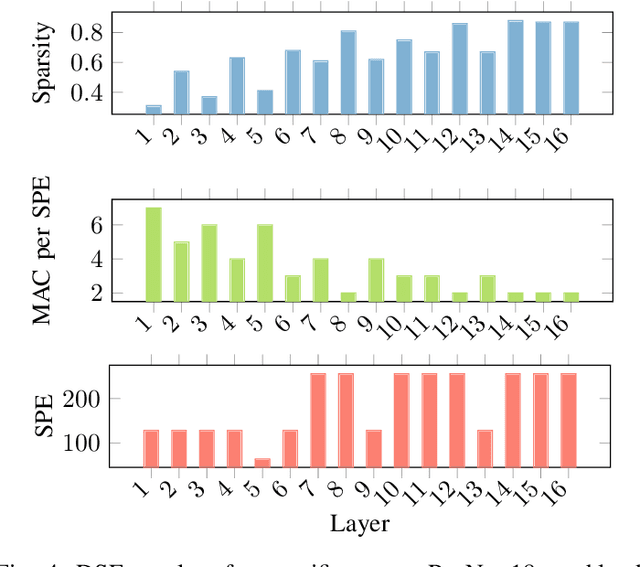
Deep Neural Networks (DNNs) excel in learning hierarchical representations from raw data, such as images, audio, and text. To compute these DNN models with high performance and energy efficiency, these models are usually deployed onto customized hardware accelerators. Among various accelerator designs, dataflow architecture has shown promising performance due to its layer-pipelined structure and its scalability in data parallelism. Exploiting weights and activations sparsity can further enhance memory storage and computation efficiency. However, existing approaches focus on exploiting sparsity in non-dataflow accelerators, which cannot be applied onto dataflow accelerators because of the large hardware design space introduced. As such, this could miss opportunities to find an optimal combination of sparsity features and hardware designs. In this paper, we propose a novel approach to exploit unstructured weights and activations sparsity for dataflow accelerators, using software and hardware co-optimization. We propose a Hardware-Aware Sparsity Search (HASS) to systematically determine an efficient sparsity solution for dataflow accelerators. Over a set of models, we achieve an efficiency improvement ranging from 1.3$\times$ to 4.2$\times$ compared to existing sparse designs, which are either non-dataflow or non-hardware-aware. Particularly, the throughput of MobileNetV3 can be optimized to 4895 images per second. HASS is open-source: \url{https://github.com/Yu-Zhewen/HASS}
$Δ$-DiT: A Training-Free Acceleration Method Tailored for Diffusion Transformers
Jun 03, 2024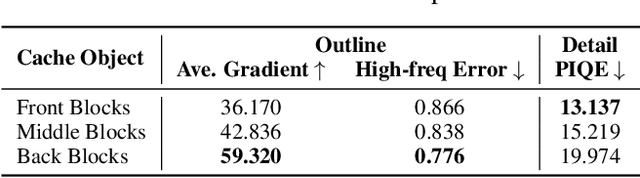
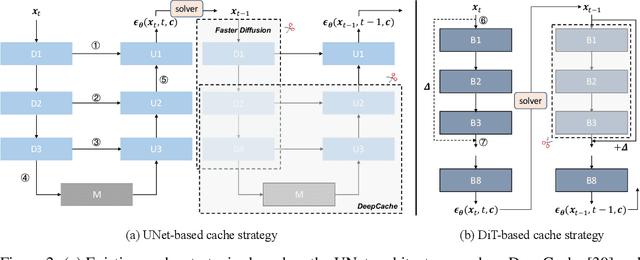

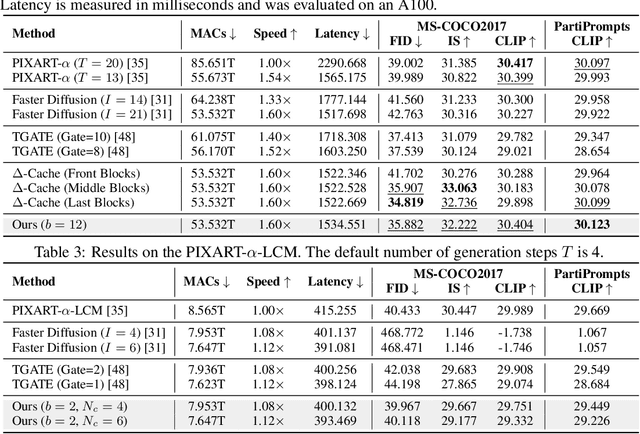
Diffusion models are widely recognized for generating high-quality and diverse images, but their poor real-time performance has led to numerous acceleration works, primarily focusing on UNet-based structures. With the more successful results achieved by diffusion transformers (DiT), there is still a lack of exploration regarding the impact of DiT structure on generation, as well as the absence of an acceleration framework tailored to the DiT architecture. To tackle these challenges, we conduct an investigation into the correlation between DiT blocks and image generation. Our findings reveal that the front blocks of DiT are associated with the outline of the generated images, while the rear blocks are linked to the details. Based on this insight, we propose an overall training-free inference acceleration framework $\Delta$-DiT: using a designed cache mechanism to accelerate the rear DiT blocks in the early sampling stages and the front DiT blocks in the later stages. Specifically, a DiT-specific cache mechanism called $\Delta$-Cache is proposed, which considers the inputs of the previous sampling image and reduces the bias in the inference. Extensive experiments on PIXART-$\alpha$ and DiT-XL demonstrate that the $\Delta$-DiT can achieve a $1.6\times$ speedup on the 20-step generation and even improves performance in most cases. In the scenario of 4-step consistent model generation and the more challenging $1.12\times$ acceleration, our method significantly outperforms existing methods. Our code will be publicly available.
SMOF: Streaming Modern CNNs on FPGAs with Smart Off-Chip Eviction
Mar 27, 2024



Convolutional Neural Networks (CNNs) have demonstrated their effectiveness in numerous vision tasks. However, their high processing requirements necessitate efficient hardware acceleration to meet the application's performance targets. In the space of FPGAs, streaming-based dataflow architectures are often adopted by users, as significant performance gains can be achieved through layer-wise pipelining and reduced off-chip memory access by retaining data on-chip. However, modern topologies, such as the UNet, YOLO, and X3D models, utilise long skip connections, requiring significant on-chip storage and thus limiting the performance achieved by such system architectures. The paper addresses the above limitation by introducing weight and activation eviction mechanisms to off-chip memory along the computational pipeline, taking into account the available compute and memory resources. The proposed mechanism is incorporated into an existing toolflow, expanding the design space by utilising off-chip memory as a buffer. This enables the mapping of such modern CNNs to devices with limited on-chip memory, under the streaming architecture design approach. SMOF has demonstrated the capacity to deliver competitive and, in some cases, state-of-the-art performance across a spectrum of computer vision tasks, achieving up to 10.65 X throughput improvement compared to previous works.
Understanding Why Label Smoothing Degrades Selective Classification and How to Fix It
Mar 19, 2024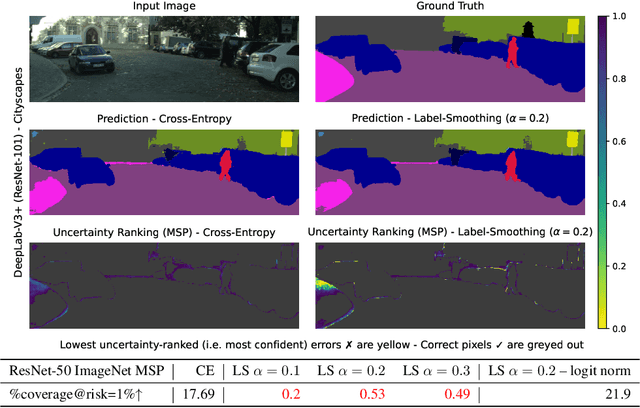
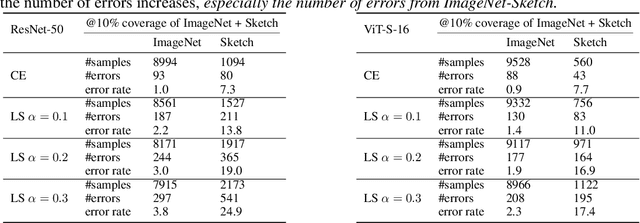


Label smoothing (LS) is a popular regularisation method for training deep neural network classifiers due to its effectiveness in improving test accuracy and its simplicity in implementation. "Hard" one-hot labels are "smoothed" by uniformly distributing probability mass to other classes, reducing overfitting. In this work, we reveal that LS negatively affects selective classification (SC) - where the aim is to reject misclassifications using a model's predictive uncertainty. We first demonstrate empirically across a range of tasks and architectures that LS leads to a consistent degradation in SC. We then explain this by analysing logit-level gradients, showing that LS exacerbates overconfidence and underconfidence by regularising the max logit more when the probability of error is low, and less when the probability of error is high. This elucidates previously reported experimental results where strong classifiers underperform in SC. We then demonstrate the empirical effectiveness of logit normalisation for recovering lost SC performance caused by LS. Furthermore, based on our gradient analysis, we explain why such normalisation is effective. We will release our code shortly.
SATAY: A Streaming Architecture Toolflow for Accelerating YOLO Models on FPGA Devices
Sep 04, 2023



AI has led to significant advancements in computer vision and image processing tasks, enabling a wide range of applications in real-life scenarios, from autonomous vehicles to medical imaging. Many of those applications require efficient object detection algorithms and complementary real-time, low latency hardware to perform inference of these algorithms. The YOLO family of models is considered the most efficient for object detection, having only a single model pass. Despite this, the complexity and size of YOLO models can be too computationally demanding for current edge-based platforms. To address this, we present SATAY: a Streaming Architecture Toolflow for Accelerating YOLO. This work tackles the challenges of deploying stateof-the-art object detection models onto FPGA devices for ultralow latency applications, enabling real-time, edge-based object detection. We employ a streaming architecture design for our YOLO accelerators, implementing the complete model on-chip in a deeply pipelined fashion. These accelerators are generated using an automated toolflow, and can target a range of suitable FPGA devices. We introduce novel hardware components to support the operations of YOLO models in a dataflow manner, and off-chip memory buffering to address the limited on-chip memory resources. Our toolflow is able to generate accelerator designs which demonstrate competitive performance and energy characteristics to GPU devices, and which outperform current state-of-the-art FPGA accelerators.
Mixed-TD: Efficient Neural Network Accelerator with Layer-Specific Tensor Decomposition
Jun 22, 2023



Neural Network designs are quite diverse, from VGG-style to ResNet-style, and from Convolutional Neural Networks to Transformers. Towards the design of efficient accelerators, many works have adopted a dataflow-based, inter-layer pipelined architecture, with a customised hardware towards each layer, achieving ultra high throughput and low latency. The deployment of neural networks to such dataflow architecture accelerators is usually hindered by the available on-chip memory as it is desirable to preload the weights of neural networks on-chip to maximise the system performance. To address this, networks are usually compressed before the deployment through methods such as pruning, quantization and tensor decomposition. In this paper, a framework for mapping CNNs onto FPGAs based on a novel tensor decomposition method called Mixed-TD is proposed. The proposed method applies layer-specific Singular Value Decomposition (SVD) and Canonical Polyadic Decomposition (CPD) in a mixed manner, achieving 1.73x to 10.29x throughput per DSP to state-of-the-art CNNs. Our work is open-sourced: https://github.com/Yu-Zhewen/Mixed-TD
fpgaHART: A toolflow for throughput-oriented acceleration of 3D CNNs for HAR onto FPGAs
May 31, 2023



Surveillance systems, autonomous vehicles, human monitoring systems, and video retrieval are just few of the many applications in which 3D Convolutional Neural Networks are exploited. However, their extensive use is restricted by their high computational and memory requirements, especially when integrated into systems with limited resources. This study proposes a toolflow that optimises the mapping of 3D CNN models for Human Action Recognition onto FPGA devices, taking into account FPGA resources and off-chip memory characteristics. The proposed system employs Synchronous Dataflow (SDF) graphs to model the designs and introduces transformations to expand and explore the design space, resulting in high-throughput designs. A variety of 3D CNN models were evaluated using the proposed toolflow on multiple FPGA devices, demonstrating its potential to deliver competitive performance compared to earlier hand-tuned and model-specific designs.
FMM-X3D: FPGA-based modeling and mapping of X3D for Human Action Recognition
May 29, 2023



3D Convolutional Neural Networks are gaining increasing attention from researchers and practitioners and have found applications in many domains, such as surveillance systems, autonomous vehicles, human monitoring systems, and video retrieval. However, their widespread adoption is hindered by their high computational and memory requirements, especially when resource-constrained systems are targeted. This paper addresses the problem of mapping X3D, a state-of-the-art model in Human Action Recognition that achieves accuracy of 95.5\% in the UCF101 benchmark, onto any FPGA device. The proposed toolflow generates an optimised stream-based hardware system, taking into account the available resources and off-chip memory characteristics of the FPGA device. The generated designs push further the current performance-accuracy pareto front, and enable for the first time the targeting of such complex model architectures for the Human Action Recognition task.