 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator
Paper and Code
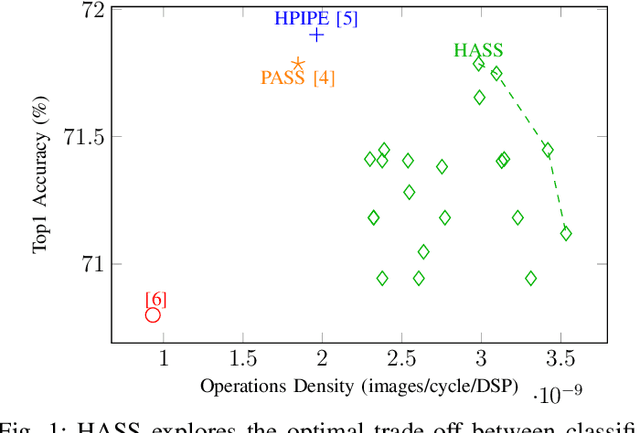
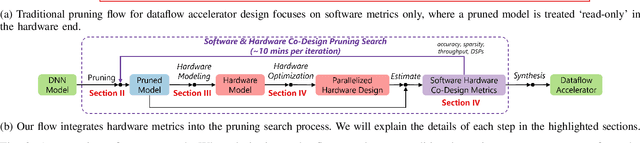
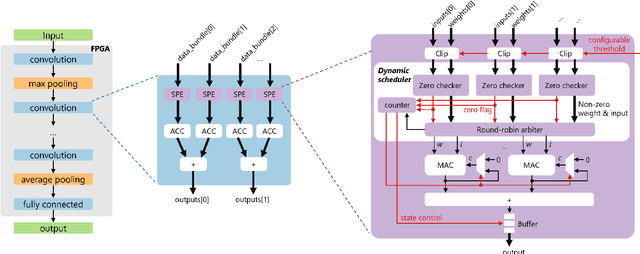
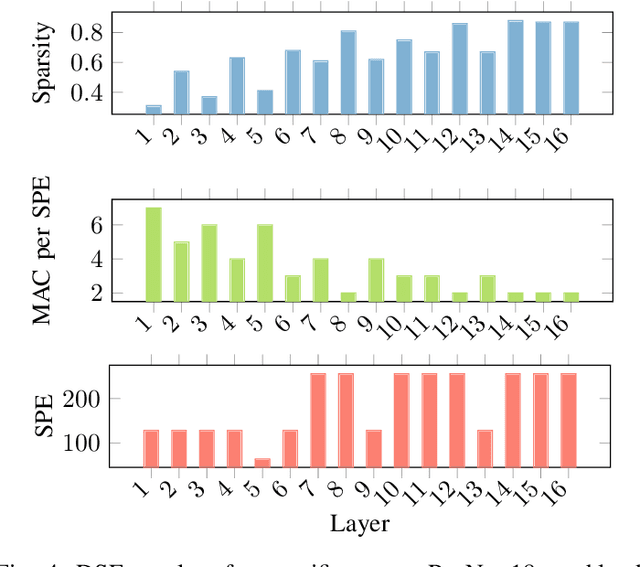
Deep Neural Networks (DNNs) excel in learning hierarchical representations from raw data, such as images, audio, and text. To compute these DNN models with high performance and energy efficiency, these models are usually deployed onto customized hardware accelerators. Among various accelerator designs, dataflow architecture has shown promising performance due to its layer-pipelined structure and its scalability in data parallelism. Exploiting weights and activations sparsity can further enhance memory storage and computation efficiency. However, existing approaches focus on exploiting sparsity in non-dataflow accelerators, which cannot be applied onto dataflow accelerators because of the large hardware design space introduced. As such, this could miss opportunities to find an optimal combination of sparsity features and hardware designs. In this paper, we propose a novel approach to exploit unstructured weights and activations sparsity for dataflow accelerators, using software and hardware co-optimization. We propose a Hardware-Aware Sparsity Search (HASS) to systematically determine an efficient sparsity solution for dataflow accelerators. Over a set of models, we achieve an efficiency improvement ranging from 1.3$\times$ to 4.2$\times$ compared to existing sparse designs, which are either non-dataflow or non-hardware-aware. Particularly, the throughput of MobileNetV3 can be optimized to 4895 images per second. HASS is open-source: \url{https://github.com/Yu-Zhewen/HASS}