 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempora: Characterising the Time-Contingent Utility of Online Test-Time Adaptation
Feb 05, 2026Test-time adaptation (TTA) offers a compelling remedy for machine learning (ML) models that degrade under domain shifts, improving generalisation on-the-fly with only unlabelled samples. This flexibility suits real deployments, yet conventional evaluations unrealistically assume unbounded processing time, overlooking the accuracy-latency trade-off. As ML increasingly underpins latency-sensitive and user-facing use-cases, temporal pressure constrains the viability of adaptable inference; predictions arriving too late to act on are futile. We introduce Tempora, a framework for evaluating TTA under this pressure. It consists of temporal scenarios that model deployment constraints, evaluation protocols that operationalise measurement, and time-contingent utility metrics that quantify the accuracy-latency trade-off. We instantiate the framework with three such metrics: (1) discrete utility for asynchronous streams with hard deadlines, (2) continuous utility for interactive settings where value decays with latency, and (3) amortised utility for budget-constrained deployments. Applying Tempora to seven TTA methods on ImageNet-C across 240 temporal evaluations reveals rank instability: conventional rankings do not predict rankings under temporal pressure; ETA, a state-of-the-art method in the conventional setting, falls short in 41.2% of evaluations. The highest-utility method varies with corruption type and temporal pressure, with no clear winner. By enabling systematic evaluation across diverse temporal constraints for the first time, Tempora reveals when and why rankings invert, offering practitioners a lens for method selection and researchers a target for deployable adaptation.
Data-Free Group-Wise Fully Quantized Winograd Convolution via Learnable Scales
Dec 27, 2024



Despite the revolutionary breakthroughs of large-scale textto-image diffusion models for complex vision and downstream tasks, their extremely high computational and storage costs limit their usability. Quantization of diffusion models has been explored in recent works to reduce compute costs and memory bandwidth usage. To further improve inference time, fast convolution algorithms such as Winograd can be used for convolution layers, which account for a significant portion of computations in diffusion models. However, the significant quality loss of fully quantized Winograd using existing coarser-grained post-training quantization methods, combined with the complexity and cost of finetuning the Winograd transformation matrices for such large models to recover quality, makes them unsuitable for large-scale foundation models. Motivated by the presence of a large range of values in them, we investigate the impact of finer-grained group-wise quantization in quantizing diffusion models. While group-wise quantization can largely handle the fully quantized Winograd convolution, it struggles to deal with the large distribution imbalance in a sizable portion of the Winograd domain computation. To reduce range differences in the Winograd domain, we propose finetuning only the scale parameters of the Winograd transform matrices without using any domain-specific training data. Because our method does not depend on any training data, the generalization performance of quantized diffusion models is safely guaranteed. For text-to-image generation task, the 8-bit fully-quantized diffusion model with Winograd provides near-lossless quality (FID and CLIP scores) in comparison to the full-precision model. For image classification, our method outperforms the state-of-the-art Winograd PTQ method by 1.62% and 2.56% in top-1 ImageNet accuracy on ResNet18 and ResNet-34, respectively, with Winograd F(6, 3).
HASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator
Jun 05, 2024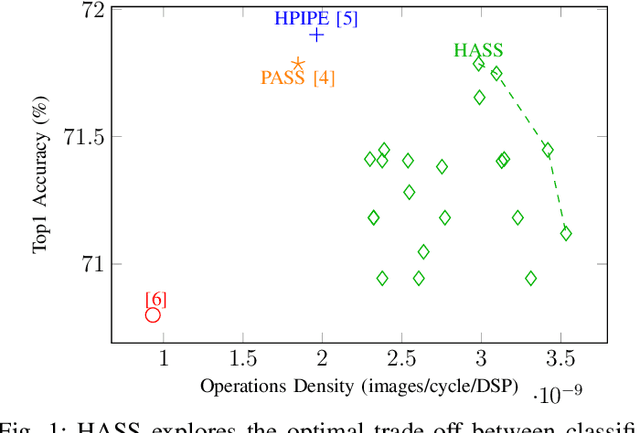
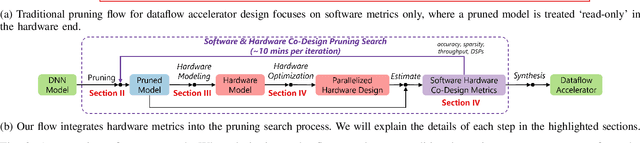
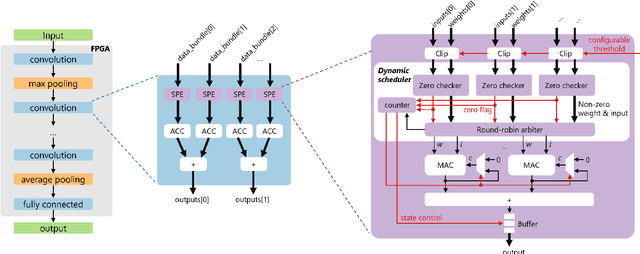
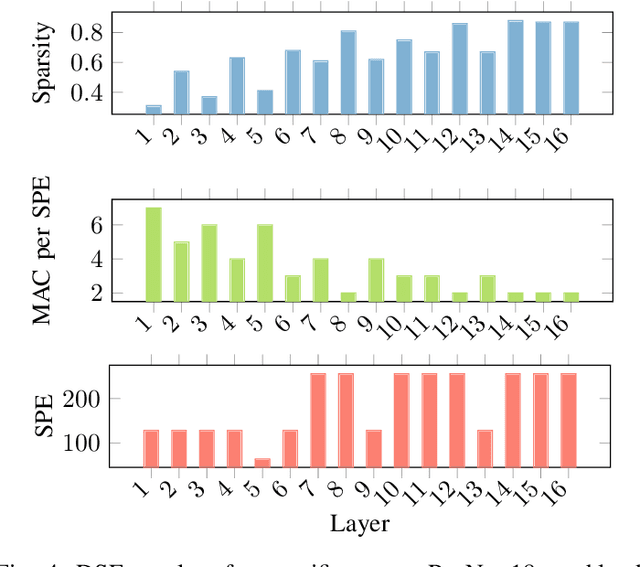
Deep Neural Networks (DNNs) excel in learning hierarchical representations from raw data, such as images, audio, and text. To compute these DNN models with high performance and energy efficiency, these models are usually deployed onto customized hardware accelerators. Among various accelerator designs, dataflow architecture has shown promising performance due to its layer-pipelined structure and its scalability in data parallelism. Exploiting weights and activations sparsity can further enhance memory storage and computation efficiency. However, existing approaches focus on exploiting sparsity in non-dataflow accelerators, which cannot be applied onto dataflow accelerators because of the large hardware design space introduced. As such, this could miss opportunities to find an optimal combination of sparsity features and hardware designs. In this paper, we propose a novel approach to exploit unstructured weights and activations sparsity for dataflow accelerators, using software and hardware co-optimization. We propose a Hardware-Aware Sparsity Search (HASS) to systematically determine an efficient sparsity solution for dataflow accelerators. Over a set of models, we achieve an efficiency improvement ranging from 1.3$\times$ to 4.2$\times$ compared to existing sparse designs, which are either non-dataflow or non-hardware-aware. Particularly, the throughput of MobileNetV3 can be optimized to 4895 images per second. HASS is open-source: \url{https://github.com/Yu-Zhewen/HASS}
Sculpting Efficiency: Pruning Medical Imaging Models for On-Device Inference
Sep 10, 2023Applying ML advancements to healthcare can improve patient outcomes. However, the sheer operational complexity of ML models, combined with legacy hardware and multi-modal gigapixel images, poses a severe deployment limitation for real-time, on-device inference. We consider filter pruning as a solution, exploring segmentation models in cardiology and ophthalmology. Our preliminary results show a compression rate of up to 1148x with minimal loss in quality, stressing the need to consider task complexity and architectural details when using off-the-shelf models. At high compression rates, filter-pruned models exhibit faster inference on a CPU than the GPU baseline. We also demonstrate that such models' robustness and generalisability characteristics exceed that of the baseline and weight-pruned counterparts. We uncover intriguing questions and take a step towards realising cost-effective disease diagnosis, monitoring, and preventive solutions.