 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign$^2$LLaVA: Cascaded Human and Large Language Model Preference Alignment for Multi-modal Instruction Curation
Sep 27, 2024



Recent advances in Multi-modal Large Language Models (MLLMs), such as LLaVA-series models, are driven by massive machine-generated instruction-following data tuning. Such automatic instruction collection pipelines, however, inadvertently introduce significant variability in data quality. This paper introduces a novel instruction curation algorithm, derived from two unique perspectives, human and LLM preference alignment, to compress this vast corpus of machine-generated multimodal instructions to a compact and high-quality form: (i) For human preference alignment, we have collected a machine-generated multimodal instruction dataset and established a comprehensive set of both subjective and objective criteria to guide the data quality assessment critically from human experts. By doing so, a reward model was trained on the annotated dataset to internalize the nuanced human understanding of instruction alignment. (ii) For LLM preference alignment, given the instruction selected by the reward model, we propose leveraging the inner LLM used in MLLM to align the writing style of visual instructions with that of the inner LLM itself, resulting in LLM-aligned instruction improvement. Extensive experiments demonstrate that we can maintain or even improve model performance by compressing synthetic multimodal instructions by up to 90%. Impressively, by aggressively reducing the total training sample size from 158k to 14k (9$\times$ smaller), our model consistently outperforms its full-size dataset counterpart across various MLLM benchmarks. Our project is available at https://github.com/DCDmllm/Align2LLaVA.
HASS: Hardware-Aware Sparsity Search for Dataflow DNN Accelerator
Jun 05, 2024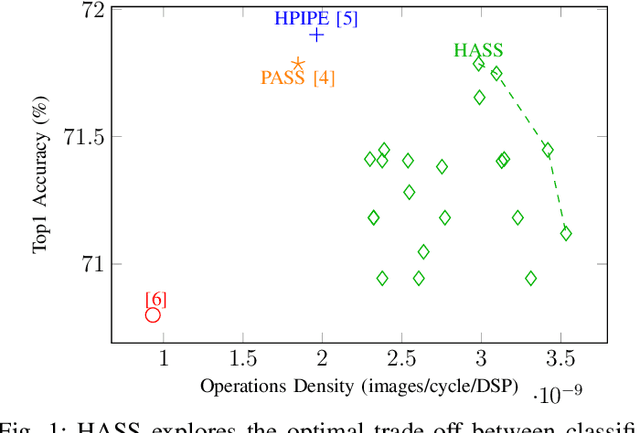
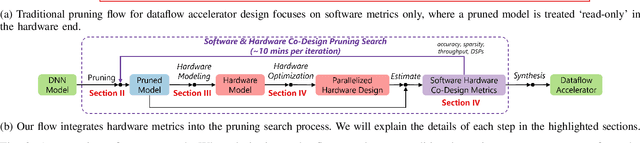
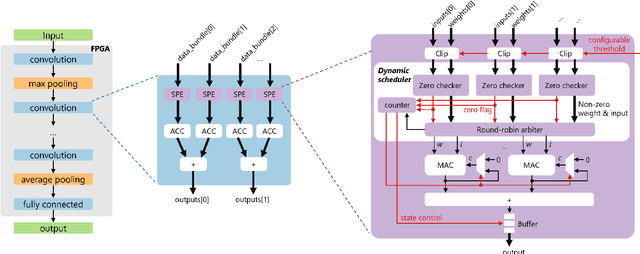
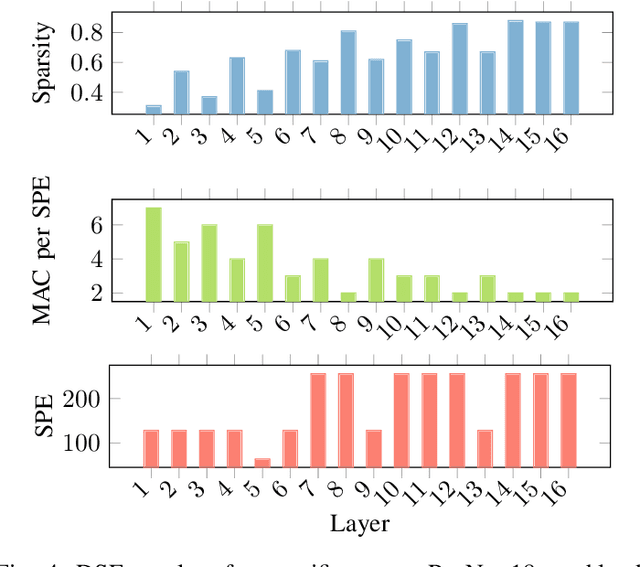
Deep Neural Networks (DNNs) excel in learning hierarchical representations from raw data, such as images, audio, and text. To compute these DNN models with high performance and energy efficiency, these models are usually deployed onto customized hardware accelerators. Among various accelerator designs, dataflow architecture has shown promising performance due to its layer-pipelined structure and its scalability in data parallelism. Exploiting weights and activations sparsity can further enhance memory storage and computation efficiency. However, existing approaches focus on exploiting sparsity in non-dataflow accelerators, which cannot be applied onto dataflow accelerators because of the large hardware design space introduced. As such, this could miss opportunities to find an optimal combination of sparsity features and hardware designs. In this paper, we propose a novel approach to exploit unstructured weights and activations sparsity for dataflow accelerators, using software and hardware co-optimization. We propose a Hardware-Aware Sparsity Search (HASS) to systematically determine an efficient sparsity solution for dataflow accelerators. Over a set of models, we achieve an efficiency improvement ranging from 1.3$\times$ to 4.2$\times$ compared to existing sparse designs, which are either non-dataflow or non-hardware-aware. Particularly, the throughput of MobileNetV3 can be optimized to 4895 images per second. HASS is open-source: \url{https://github.com/Yu-Zhewen/HASS}
SMOF: Streaming Modern CNNs on FPGAs with Smart Off-Chip Eviction
Mar 27, 2024



Convolutional Neural Networks (CNNs) have demonstrated their effectiveness in numerous vision tasks. However, their high processing requirements necessitate efficient hardware acceleration to meet the application's performance targets. In the space of FPGAs, streaming-based dataflow architectures are often adopted by users, as significant performance gains can be achieved through layer-wise pipelining and reduced off-chip memory access by retaining data on-chip. However, modern topologies, such as the UNet, YOLO, and X3D models, utilise long skip connections, requiring significant on-chip storage and thus limiting the performance achieved by such system architectures. The paper addresses the above limitation by introducing weight and activation eviction mechanisms to off-chip memory along the computational pipeline, taking into account the available compute and memory resources. The proposed mechanism is incorporated into an existing toolflow, expanding the design space by utilising off-chip memory as a buffer. This enables the mapping of such modern CNNs to devices with limited on-chip memory, under the streaming architecture design approach. SMOF has demonstrated the capacity to deliver competitive and, in some cases, state-of-the-art performance across a spectrum of computer vision tasks, achieving up to 10.65 X throughput improvement compared to previous works.
SATAY: A Streaming Architecture Toolflow for Accelerating YOLO Models on FPGA Devices
Sep 04, 2023



AI has led to significant advancements in computer vision and image processing tasks, enabling a wide range of applications in real-life scenarios, from autonomous vehicles to medical imaging. Many of those applications require efficient object detection algorithms and complementary real-time, low latency hardware to perform inference of these algorithms. The YOLO family of models is considered the most efficient for object detection, having only a single model pass. Despite this, the complexity and size of YOLO models can be too computationally demanding for current edge-based platforms. To address this, we present SATAY: a Streaming Architecture Toolflow for Accelerating YOLO. This work tackles the challenges of deploying stateof-the-art object detection models onto FPGA devices for ultralow latency applications, enabling real-time, edge-based object detection. We employ a streaming architecture design for our YOLO accelerators, implementing the complete model on-chip in a deeply pipelined fashion. These accelerators are generated using an automated toolflow, and can target a range of suitable FPGA devices. We introduce novel hardware components to support the operations of YOLO models in a dataflow manner, and off-chip memory buffering to address the limited on-chip memory resources. Our toolflow is able to generate accelerator designs which demonstrate competitive performance and energy characteristics to GPU devices, and which outperform current state-of-the-art FPGA accelerators.
Mixed-TD: Efficient Neural Network Accelerator with Layer-Specific Tensor Decomposition
Jun 22, 2023



Neural Network designs are quite diverse, from VGG-style to ResNet-style, and from Convolutional Neural Networks to Transformers. Towards the design of efficient accelerators, many works have adopted a dataflow-based, inter-layer pipelined architecture, with a customised hardware towards each layer, achieving ultra high throughput and low latency. The deployment of neural networks to such dataflow architecture accelerators is usually hindered by the available on-chip memory as it is desirable to preload the weights of neural networks on-chip to maximise the system performance. To address this, networks are usually compressed before the deployment through methods such as pruning, quantization and tensor decomposition. In this paper, a framework for mapping CNNs onto FPGAs based on a novel tensor decomposition method called Mixed-TD is proposed. The proposed method applies layer-specific Singular Value Decomposition (SVD) and Canonical Polyadic Decomposition (CPD) in a mixed manner, achieving 1.73x to 10.29x throughput per DSP to state-of-the-art CNNs. Our work is open-sourced: https://github.com/Yu-Zhewen/Mixed-TD
SVD-NAS: Coupling Low-Rank Approximation and Neural Architecture Search
Aug 22, 2022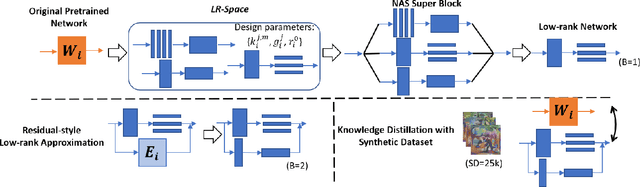
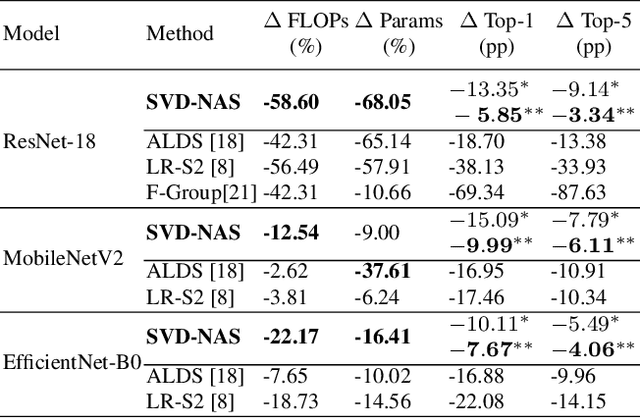
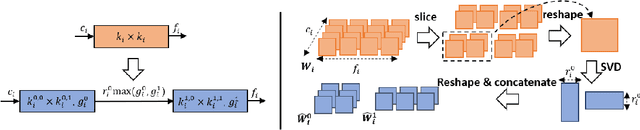

The task of compressing pre-trained Deep Neural Networks has attracted wide interest of the research community due to its great benefits in freeing practitioners from data access requirements. In this domain, low-rank approximation is a promising method, but existing solutions considered a restricted number of design choices and failed to efficiently explore the design space, which lead to severe accuracy degradation and limited compression ratio achieved. To address the above limitations, this work proposes the SVD-NAS framework that couples the domains of low-rank approximation and neural architecture search. SVD-NAS generalises and expands the design choices of previous works by introducing the Low-Rank architecture space, LR-space, which is a more fine-grained design space of low-rank approximation. Afterwards, this work proposes a gradient-descent-based search for efficiently traversing the LR-space. This finer and more thorough exploration of the possible design choices results in improved accuracy as well as reduction in parameters, FLOPS, and latency of a CNN model. Results demonstrate that the SVD-NAS achieves 2.06-12.85pp higher accuracy on ImageNet than state-of-the-art methods under the data-limited problem setting. SVD-NAS is open-sourced at https://github.com/Yu-Zhewen/SVD-NAS.