 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogniMap3D: Cognitive 3D Mapping and Rapid Retrieval
Jan 13, 2026We present CogniMap3D, a bioinspired framework for dynamic 3D scene understanding and reconstruction that emulates human cognitive processes. Our approach maintains a persistent memory bank of static scenes, enabling efficient spatial knowledge storage and rapid retrieval. CogniMap3D integrates three core capabilities: a multi-stage motion cue framework for identifying dynamic objects, a cognitive mapping system for storing, recalling, and updating static scenes across multiple visits, and a factor graph optimization strategy for refining camera poses. Given an image stream, our model identifies dynamic regions through motion cues with depth and camera pose priors, then matches static elements against its memory bank. When revisiting familiar locations, CogniMap3D retrieves stored scenes, relocates cameras, and updates memory with new observations. Evaluations on video depth estimation, camera pose reconstruction, and 3D mapping tasks demonstrate its state-of-the-art performance, while effectively supporting continuous scene understanding across extended sequences and multiple visits.
Consistent Instance Field for Dynamic Scene Understanding
Dec 16, 2025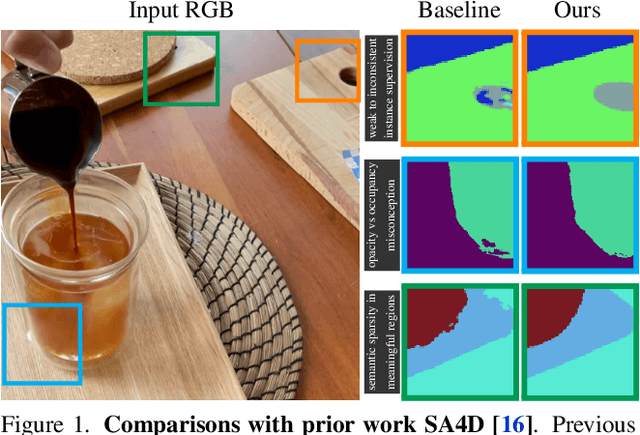
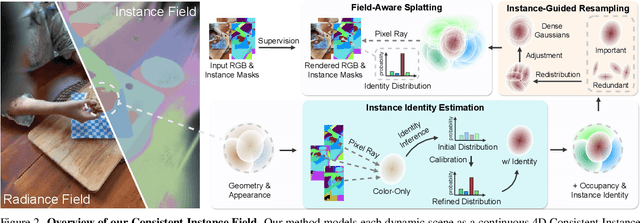
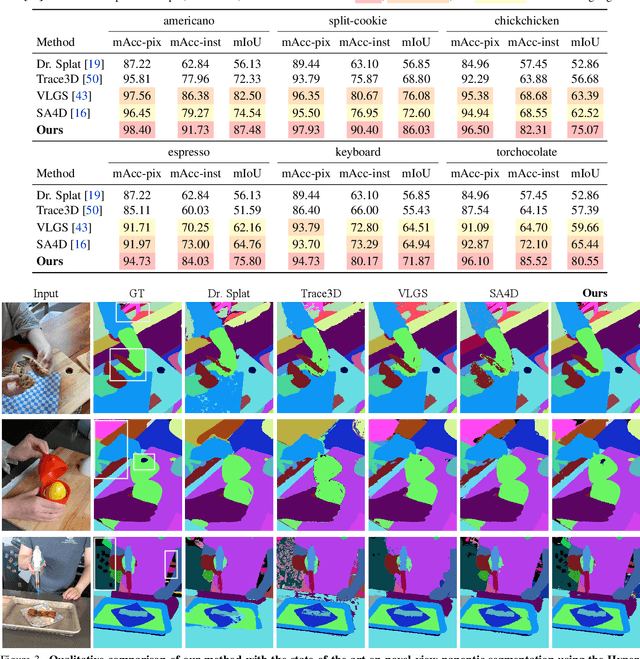
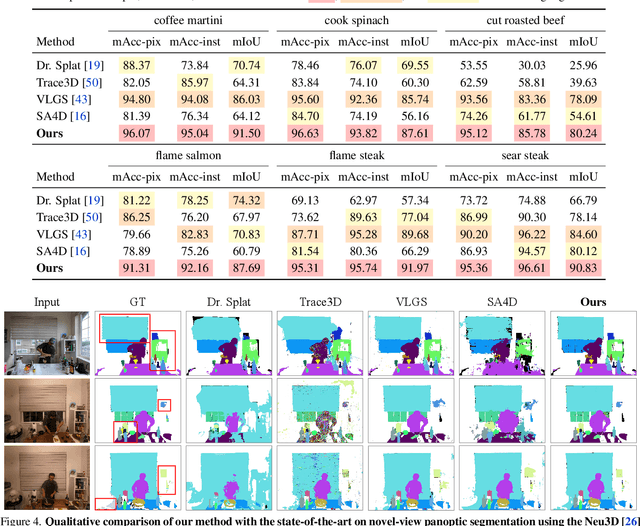
We introduce Consistent Instance Field, a continuous and probabilistic spatio-temporal representation for dynamic scene understanding. Unlike prior methods that rely on discrete tracking or view-dependent features, our approach disentangles visibility from persistent object identity by modeling each space-time point with an occupancy probability and a conditional instance distribution. To realize this, we introduce a novel instance-embedded representation based on deformable 3D Gaussians, which jointly encode radiance and semantic information and are learned directly from input RGB images and instance masks through differentiable rasterization. Furthermore, we introduce new mechanisms to calibrate per-Gaussian identities and resample Gaussians toward semantically active regions, ensuring consistent instance representations across space and time. Experiments on HyperNeRF and Neu3D datasets demonstrate that our method significantly outperforms state-of-the-art methods on novel-view panoptic segmentation and open-vocabulary 4D querying tasks.
From Particles to Fields: Reframing Photon Mapping with Continuous Gaussian Photon Fields
Dec 13, 2025Accurately modeling light transport is essential for realistic image synthesis. Photon mapping provides physically grounded estimates of complex global illumination effects such as caustics and specular-diffuse interactions, yet its per-view radiance estimation remains computationally inefficient when rendering multiple views of the same scene. The inefficiency arises from independent photon tracing and stochastic kernel estimation at each viewpoint, leading to inevitable redundant computation. To accelerate multi-view rendering, we reformulate photon mapping as a continuous and reusable radiance function. Specifically, we introduce the Gaussian Photon Field (GPF), a learnable representation that encodes photon distributions as anisotropic 3D Gaussian primitives parameterized by position, rotation, scale, and spectrum. GPF is initialized from physically traced photons in the first SPPM iteration and optimized using multi-view supervision of final radiance, distilling photon-based light transport into a continuous field. Once trained, the field enables differentiable radiance evaluation along camera rays without repeated photon tracing or iterative refinement. Extensive experiments on scenes with complex light transport, such as caustics and specular-diffuse interactions, demonstrate that GPF attains photon-level accuracy while reducing computation by orders of magnitude, unifying the physical rigor of photon-based rendering with the efficiency of neural scene representations.
TraceFlow: Dynamic 3D Reconstruction of Specular Scenes Driven by Ray Tracing
Dec 10, 2025We present TraceFlow, a novel framework for high-fidelity rendering of dynamic specular scenes by addressing two key challenges: precise reflection direction estimation and physically accurate reflection modeling. To achieve this, we propose a Residual Material-Augmented 2D Gaussian Splatting representation that models dynamic geometry and material properties, allowing accurate reflection ray computation. Furthermore, we introduce a Dynamic Environment Gaussian and a hybrid rendering pipeline that decomposes rendering into diffuse and specular components, enabling physically grounded specular synthesis via rasterization and ray tracing. Finally, we devise a coarse-to-fine training strategy to improve optimization stability and promote physically meaningful decomposition. Extensive experiments on dynamic scene benchmarks demonstrate that TraceFlow outperforms prior methods both quantitatively and qualitatively, producing sharper and more realistic specular reflections in complex dynamic environments.
Tensor-Efficient High-Dimensional Q-learning
Nov 05, 2025


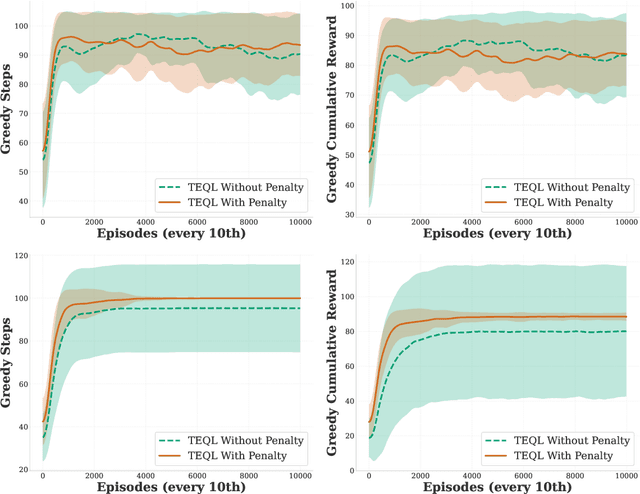
High-dimensional reinforcement learning faces challenges with complex calculations and low sample efficiency in large state-action spaces. Q-learning algorithms struggle particularly with the curse of dimensionality, where the number of state-action pairs grows exponentially with problem size. While neural network-based approaches like Deep Q-Networks have shown success, recent tensor-based methods using low-rank decomposition offer more parameter-efficient alternatives. Building upon existing tensor-based methods, we propose Tensor-Efficient Q-Learning (TEQL), which enhances low-rank tensor decomposition via improved block coordinate descent on discretized state-action spaces, incorporating novel exploration and regularization mechanisms. The key innovation is an exploration strategy that combines approximation error with visit count-based upper confidence bound to prioritize actions with high uncertainty, avoiding wasteful random exploration. Additionally, we incorporate a frequency-based penalty term in the objective function to encourage exploration of less-visited state-action pairs and reduce overfitting to frequently visited regions. Empirical results on classic control tasks demonstrate that TEQL outperforms conventional matrix-based methods and deep RL approaches in both sample efficiency and total rewards, making it suitable for resource-constrained applications, such as space and healthcare where sampling costs are high.
FlashEdit: Decoupling Speed, Structure, and Semantics for Precise Image Editing
Sep 26, 2025Text-guided image editing with diffusion models has achieved remarkable quality but suffers from prohibitive latency, hindering real-world applications. We introduce FlashEdit, a novel framework designed to enable high-fidelity, real-time image editing. Its efficiency stems from three key innovations: (1) a One-Step Inversion-and-Editing (OSIE) pipeline that bypasses costly iterative processes; (2) a Background Shield (BG-Shield) technique that guarantees background preservation by selectively modifying features only within the edit region; and (3) a Sparsified Spatial Cross-Attention (SSCA) mechanism that ensures precise, localized edits by suppressing semantic leakage to the background. Extensive experiments demonstrate that FlashEdit maintains superior background consistency and structural integrity, while performing edits in under 0.2 seconds, which is an over 150$\times$ speedup compared to prior multi-step methods. Our code will be made publicly available at https://github.com/JunyiWuCode/FlashEdit.
Efficient Multimodal Dataset Distillation via Generative Models
Sep 18, 2025Dataset distillation aims to synthesize a small dataset from a large dataset, enabling the model trained on it to perform well on the original dataset. With the blooming of large language models and multimodal large language models, the importance of multimodal datasets, particularly image-text datasets, has grown significantly. However, existing multimodal dataset distillation methods are constrained by the Matching Training Trajectories algorithm, which significantly increases the computing resource requirement, and takes days to process the distillation. In this work, we introduce EDGE, a generative distillation method for efficient multimodal dataset distillation. Specifically, we identify two key challenges of distilling multimodal datasets with generative models: 1) The lack of correlation between generated images and captions. 2) The lack of diversity among generated samples. To address the aforementioned issues, we propose a novel generative model training workflow with a bi-directional contrastive loss and a diversity loss. Furthermore, we propose a caption synthesis strategy to further improve text-to-image retrieval performance by introducing more text information. Our method is evaluated on Flickr30K, COCO, and CC3M datasets, demonstrating superior performance and efficiency compared to existing approaches. Notably, our method achieves results 18x faster than the state-of-the-art method.
DVD-Quant: Data-free Video Diffusion Transformers Quantization
May 24, 2025Diffusion Transformers (DiTs) have emerged as the state-of-the-art architecture for video generation, yet their computational and memory demands hinder practical deployment. While post-training quantization (PTQ) presents a promising approach to accelerate Video DiT models, existing methods suffer from two critical limitations: (1) dependence on lengthy, computation-heavy calibration procedures, and (2) considerable performance deterioration after quantization. To address these challenges, we propose DVD-Quant, a novel Data-free quantization framework for Video DiTs. Our approach integrates three key innovations: (1) Progressive Bounded Quantization (PBQ) and (2) Auto-scaling Rotated Quantization (ARQ) for calibration data-free quantization error reduction, as well as (3) $\delta$-Guided Bit Switching ($\delta$-GBS) for adaptive bit-width allocation. Extensive experiments across multiple video generation benchmarks demonstrate that DVD-Quant achieves an approximately 2$\times$ speedup over full-precision baselines on HunyuanVideo while maintaining visual fidelity. Notably, DVD-Quant is the first to enable W4A4 PTQ for Video DiTs without compromising video quality. Code and models will be available at https://github.com/lhxcs/DVD-Quant.
EMO-X: Efficient Multi-Person Pose and Shape Estimation in One-Stage
Apr 11, 2025Expressive Human Pose and Shape Estimation (EHPS) aims to jointly estimate human pose, hand gesture, and facial expression from monocular images. Existing methods predominantly rely on Transformer-based architectures, which suffer from quadratic complexity in self-attention, leading to substantial computational overhead, especially in multi-person scenarios. Recently, Mamba has emerged as a promising alternative to Transformers due to its efficient global modeling capability. However, it remains limited in capturing fine-grained local dependencies, which are essential for precise EHPS. To address these issues, we propose EMO-X, the Efficient Multi-person One-stage model for multi-person EHPS. Specifically, we explore a Scan-based Global-Local Decoder (SGLD) that integrates global context with skeleton-aware local features to iteratively enhance human tokens. Our EMO-X leverages the superior global modeling capability of Mamba and designs a local bidirectional scan mechanism for skeleton-aware local refinement. Comprehensive experiments demonstrate that EMO-X strikes an excellent balance between efficiency and accuracy. Notably, it achieves a significant reduction in computational complexity, requiring 69.8% less inference time compared to state-of-the-art (SOTA) methods, while outperforming most of them in accuracy.
SpecEE: Accelerating Large Language Model Inference with Speculative Early Exiting
Apr 11, 2025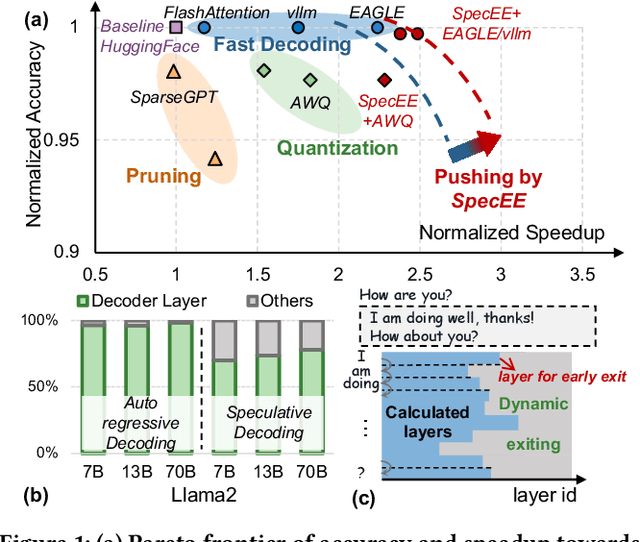
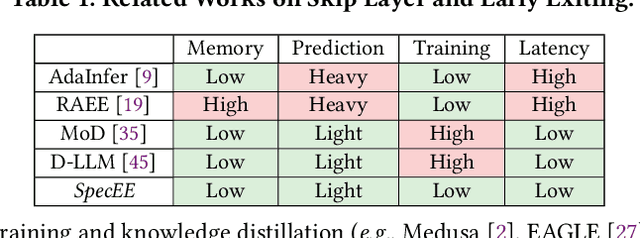
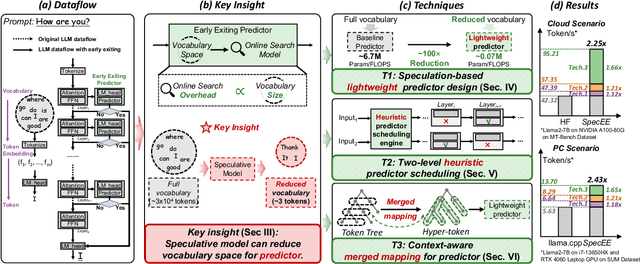
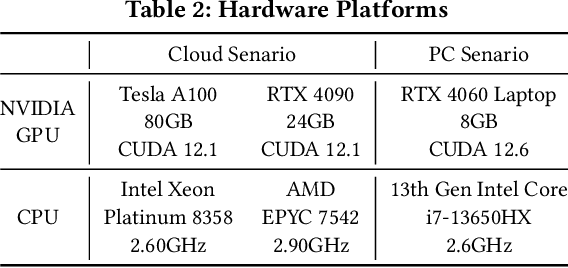
Early exiting has recently emerged as a promising technique for accelerating large language models (LLMs) by effectively reducing the hardware computation and memory access. In this paper, we present SpecEE, a fast LLM inference engine with speculative early exiting. (1) At the algorithm level, we propose the speculation-based lightweight predictor design by exploiting the probabilistic correlation between the speculative tokens and the correct results and high parallelism of GPUs. (2) At the system level, we point out that not all layers need a predictor and design the two-level heuristic predictor scheduling engine based on skewed distribution and contextual similarity. (3) At the mapping level, we point out that different decoding methods share the same essential characteristics, and propose the context-aware merged mapping for predictor with efficient GPU implementations to support speculative decoding, and form a framework for various existing orthogonal acceleration techniques (e.g., quantization and sparse activation) on cloud and personal computer (PC) scenarios, successfully pushing the Pareto frontier of accuracy and speedup. It is worth noting that SpecEE can be applied to any LLM by negligible training overhead in advance without affecting the model original parameters. Extensive experiments show that SpecEE achieves 2.25x and 2.43x speedup with Llama2-7B on cloud and PC scenarios respectively.