 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEQ: Modality-Adaptive Quantization for MoE Vision-Language Models
Feb 01, 2026Mixture-of-Experts(MoE) Vision-Language Models (VLMs) offer remarkable performance but incur prohibitive memory and computational costs, making compression essential. Post-Training Quantization (PTQ) is an effective training-free technique to address the massive memory and computation overhead. Existing quantization paradigms fall short as they are oblivious to two critical forms of heterogeneity: the inherent discrepancy between vision and language tokens, and the non-uniform contribution of different experts. To bridge this gap, we propose Visual Expert Quantization (VEQ), a dual-aware quantization framework designed to simultaneously accommodate cross-modal differences and heterogeneity between experts. Specifically, VEQ incorporates 1)Modality-expert-aware Quantization, which utilizes expert activation frequency to prioritize error minimization for pivotal experts, and 2)Modality-affinity-aware Quantization, which constructs an enhanced Hessian matrix by integrating token-expert affinity with modality information to guide the calibration process. Extensive experiments across diverse benchmarks verify that VEQ consistently outperforms state-of-the-art baselines. Specifically, under the W3A16 configuration, our method achieves significant average accuracy gains of 2.04\% on Kimi-VL and 3.09\% on Qwen3-VL compared to the previous SOTA quantization methods, demonstrating superior robustness across various multimodal tasks. Our code will be available at https://github.com/guangshuoqin/VEQ.
D$^2$Quant: Accurate Low-bit Post-Training Weight Quantization for LLMs
Jan 30, 2026Large language models (LLMs) deliver strong performance, but their high compute and memory costs make deployment difficult in resource-constrained scenarios. Weight-only post-training quantization (PTQ) is appealing, as it reduces memory usage and enables practical speedup without low-bit operators or specialized hardware. However, accuracy often degrades significantly in weight-only PTQ at sub-4-bit precision, and our analysis identifies two main causes: (1) down-projection matrices are a well-known quantization bottleneck, but maintaining their fidelity often requires extra bit-width; (2) weight quantization induces activation deviations, but effective correction strategies remain underexplored. To address these issues, we propose D$^2$Quant, a novel weight-only PTQ framework that improves quantization from both the weight and activation perspectives. On the weight side, we design a Dual-Scale Quantizer (DSQ) tailored to down-projection matrices, with an absorbable scaling factor that significantly improves accuracy without increasing the bit budget. On the activation side, we propose Deviation-Aware Correction (DAC), which incorporates a mean-shift correction within LayerNorm to mitigate quantization-induced activation distribution shifts. Extensive experiments across multiple LLM families and evaluation metrics show that D$^2$Quant delivers superior performance for weight-only PTQ at sub-4-bit precision. The code and models will be available at https://github.com/XIANGLONGYAN/D2Quant.
FlashEdit: Decoupling Speed, Structure, and Semantics for Precise Image Editing
Sep 26, 2025Text-guided image editing with diffusion models has achieved remarkable quality but suffers from prohibitive latency, hindering real-world applications. We introduce FlashEdit, a novel framework designed to enable high-fidelity, real-time image editing. Its efficiency stems from three key innovations: (1) a One-Step Inversion-and-Editing (OSIE) pipeline that bypasses costly iterative processes; (2) a Background Shield (BG-Shield) technique that guarantees background preservation by selectively modifying features only within the edit region; and (3) a Sparsified Spatial Cross-Attention (SSCA) mechanism that ensures precise, localized edits by suppressing semantic leakage to the background. Extensive experiments demonstrate that FlashEdit maintains superior background consistency and structural integrity, while performing edits in under 0.2 seconds, which is an over 150$\times$ speedup compared to prior multi-step methods. Our code will be made publicly available at https://github.com/JunyiWuCode/FlashEdit.
ReCalKV: Low-Rank KV Cache Compression via Head Reordering and Offline Calibration
May 30, 2025
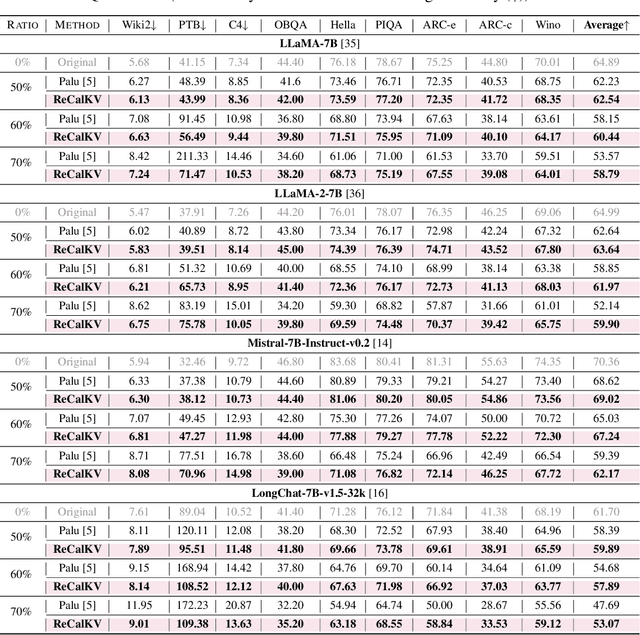
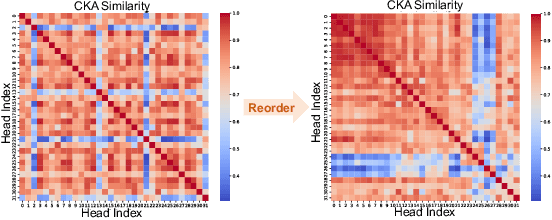

Large language models (LLMs) have achieved remarkable performance, yet their capability on long-context reasoning is often constrained by the excessive memory required to store the Key-Value (KV) cache. This makes KV cache compression an essential step toward enabling efficient long-context reasoning. Recent methods have explored reducing the hidden dimensions of the KV cache, but many introduce additional computation through projection layers or suffer from significant performance degradation under high compression ratios. To address these challenges, we propose ReCalKV, a post-training KV cache compression method that reduces the hidden dimensions of the KV cache. We develop distinct compression strategies for Keys and Values based on their different roles and varying importance in the attention mechanism. For Keys, we propose Head-wise Similarity-aware Reordering (HSR), which clusters similar heads and applies grouped SVD to the key projection matrix, reducing additional computation while preserving accuracy. For Values, we propose Offline Calibration and Matrix Fusion (OCMF) to preserve accuracy without extra computational overhead. Experiments show that ReCalKV outperforms existing low-rank compression methods, achieving high compression ratios with minimal performance loss. Code is available at: https://github.com/XIANGLONGYAN/ReCalKV.
DVD-Quant: Data-free Video Diffusion Transformers Quantization
May 24, 2025Diffusion Transformers (DiTs) have emerged as the state-of-the-art architecture for video generation, yet their computational and memory demands hinder practical deployment. While post-training quantization (PTQ) presents a promising approach to accelerate Video DiT models, existing methods suffer from two critical limitations: (1) dependence on lengthy, computation-heavy calibration procedures, and (2) considerable performance deterioration after quantization. To address these challenges, we propose DVD-Quant, a novel Data-free quantization framework for Video DiTs. Our approach integrates three key innovations: (1) Progressive Bounded Quantization (PBQ) and (2) Auto-scaling Rotated Quantization (ARQ) for calibration data-free quantization error reduction, as well as (3) $\delta$-Guided Bit Switching ($\delta$-GBS) for adaptive bit-width allocation. Extensive experiments across multiple video generation benchmarks demonstrate that DVD-Quant achieves an approximately 2$\times$ speedup over full-precision baselines on HunyuanVideo while maintaining visual fidelity. Notably, DVD-Quant is the first to enable W4A4 PTQ for Video DiTs without compromising video quality. Code and models will be available at https://github.com/lhxcs/DVD-Quant.
Low-bit Model Quantization for Deep Neural Networks: A Survey
May 08, 2025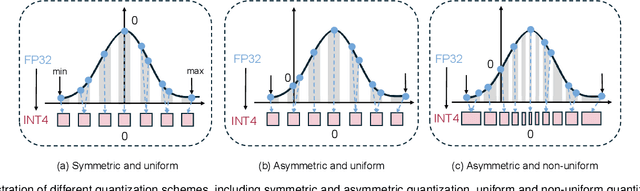
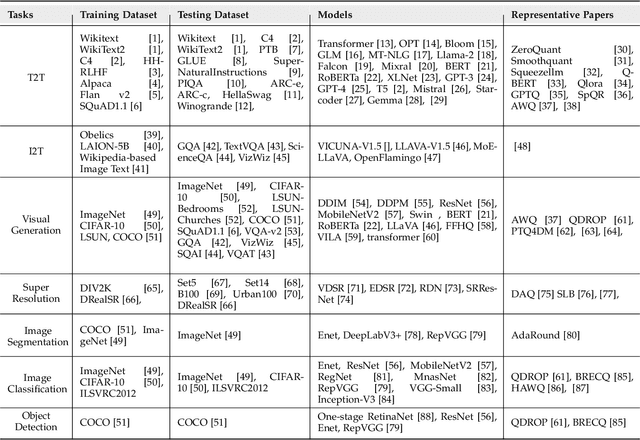
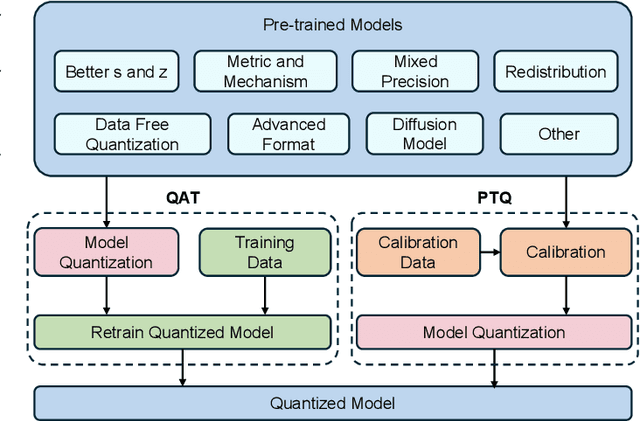
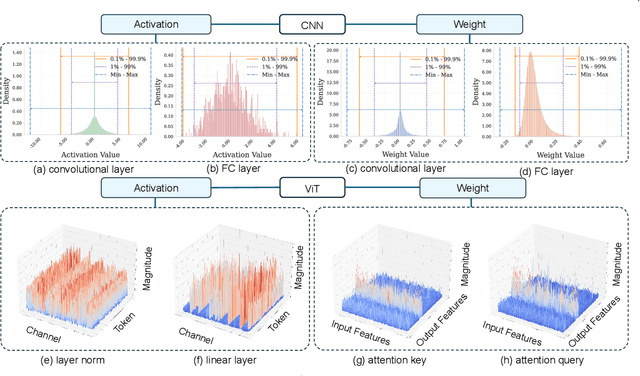
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.
QuantCache: Adaptive Importance-Guided Quantization with Hierarchical Latent and Layer Caching for Video Generation
Mar 09, 2025Recently, Diffusion Transformers (DiTs) have emerged as a dominant architecture in video generation, surpassing U-Net-based models in terms of performance. However, the enhanced capabilities of DiTs come with significant drawbacks, including increased computational and memory costs, which hinder their deployment on resource-constrained devices. Current acceleration techniques, such as quantization and cache mechanism, offer limited speedup and are often applied in isolation, failing to fully address the complexities of DiT architectures. In this paper, we propose QuantCache, a novel training-free inference acceleration framework that jointly optimizes hierarchical latent caching, adaptive importance-guided quantization, and structural redundancy-aware pruning. QuantCache achieves an end-to-end latency speedup of 6.72$\times$ on Open-Sora with minimal loss in generation quality. Extensive experiments across multiple video generation benchmarks demonstrate the effectiveness of our method, setting a new standard for efficient DiT inference. The code and models will be available at https://github.com/JunyiWuCode/QuantCache.
CondiQuant: Condition Number Based Low-Bit Quantization for Image Super-Resolution
Feb 21, 2025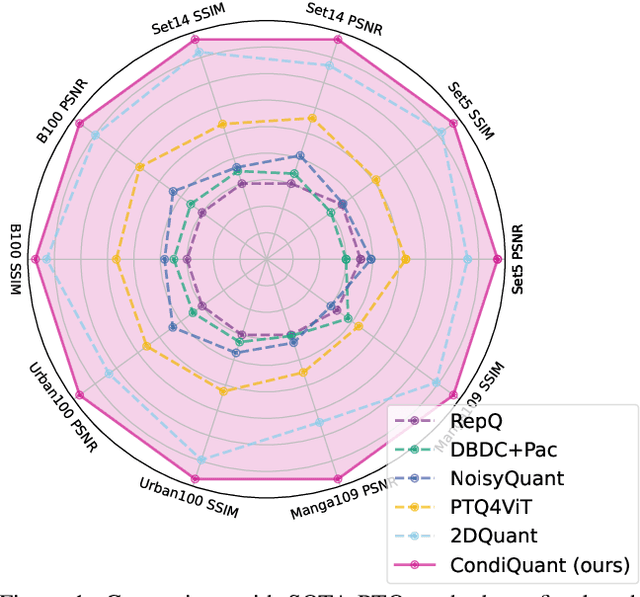
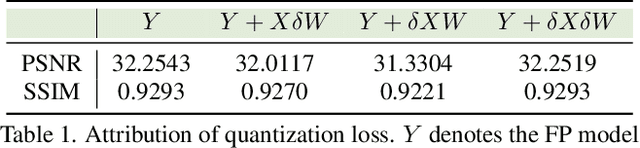
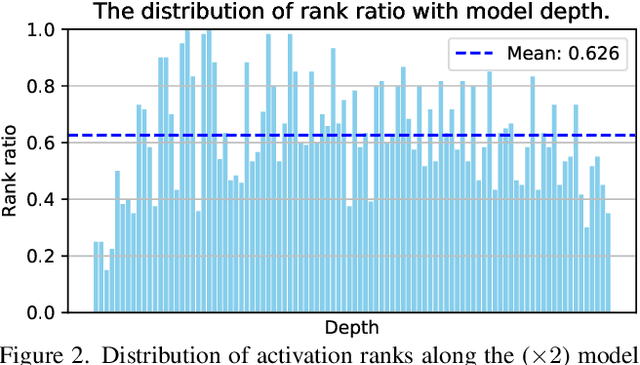
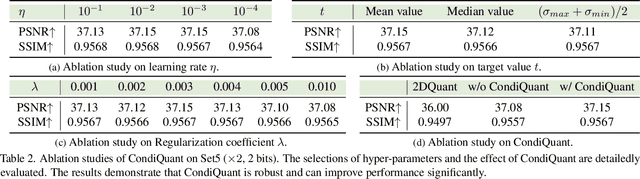
Low-bit model quantization for image super-resolution (SR) is a longstanding task that is renowned for its surprising compression and acceleration ability. However, accuracy degradation is inevitable when compressing the full-precision (FP) model to ultra-low bit widths (2~4 bits). Experimentally, we observe that the degradation of quantization is mainly attributed to the quantization of activation instead of model weights. In numerical analysis, the condition number of weights could measure how much the output value can change for a small change in the input argument, inherently reflecting the quantization error. Therefore, we propose CondiQuant, a condition number based low-bit post-training quantization for image super-resolution. Specifically, we formulate the quantization error as the condition number of weight metrics. By decoupling the representation ability and the quantization sensitivity, we design an efficient proximal gradient descent algorithm to iteratively minimize the condition number and maintain the output still. With comprehensive experiments, we demonstrate that CondiQuant outperforms existing state-of-the-art post-training quantization methods in accuracy without computation overhead and gains the theoretically optimal compression ratio in model parameters. Our code and model are released at https://github.com/Kai-Liu001/CondiQuant.
AdaSVD: Adaptive Singular Value Decomposition for Large Language Models
Feb 04, 2025



Large language models (LLMs) have achieved remarkable success in natural language processing (NLP) tasks, yet their substantial memory requirements present significant challenges for deployment on resource-constrained devices. Singular Value Decomposition (SVD) has emerged as a promising compression technique for LLMs, offering considerable reductions in memory overhead. However, existing SVD-based methods often struggle to effectively mitigate the errors introduced by SVD truncation, leading to a noticeable performance gap when compared to the original models. Furthermore, applying a uniform compression ratio across all transformer layers fails to account for the varying importance of different layers. To address these challenges, we propose AdaSVD, an adaptive SVD-based LLM compression approach. Specifically, AdaSVD introduces adaComp, which adaptively compensates for SVD truncation errors by alternately updating the singular matrices U and V^T. Additionally, AdaSVD introduces adaCR, which adaptively assigns layer-specific compression ratios based on the relative importance of each layer. Extensive experiments across multiple LLM families and evaluation metrics demonstrate that AdaSVD consistently outperforms state-of-the-art (SOTA) SVD-based methods, achieving superior performance with significantly reduced memory requirements. The code and models will be available at https://github.com/ZHITENGLI/AdaSVD.
Progressive Binarization with Semi-Structured Pruning for LLMs
Feb 03, 2025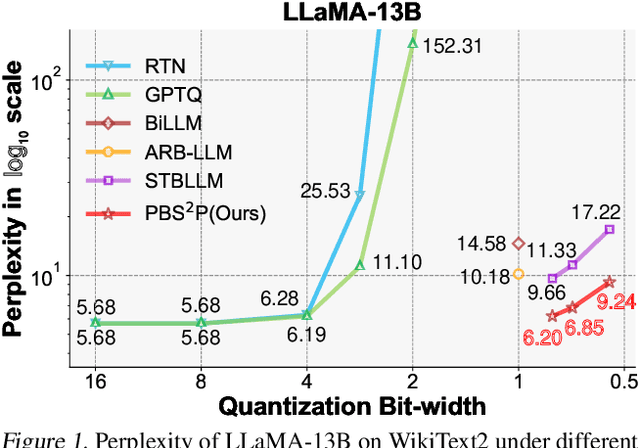
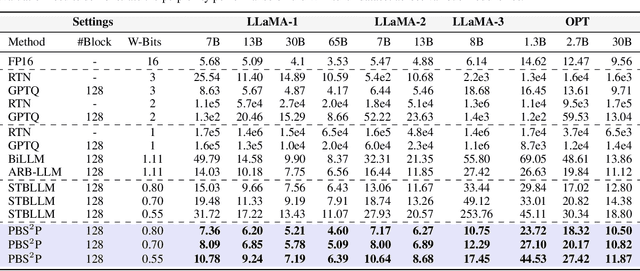
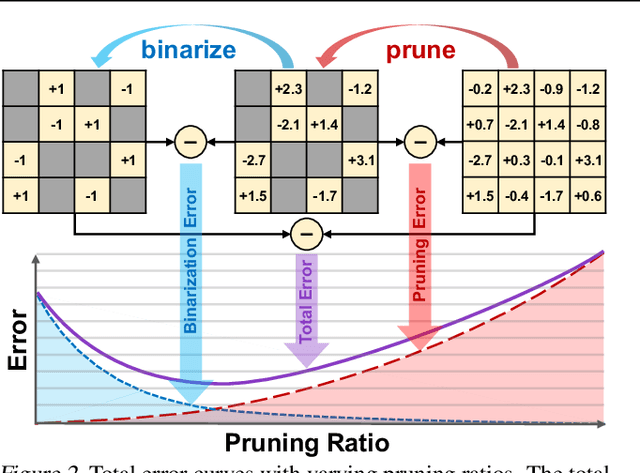
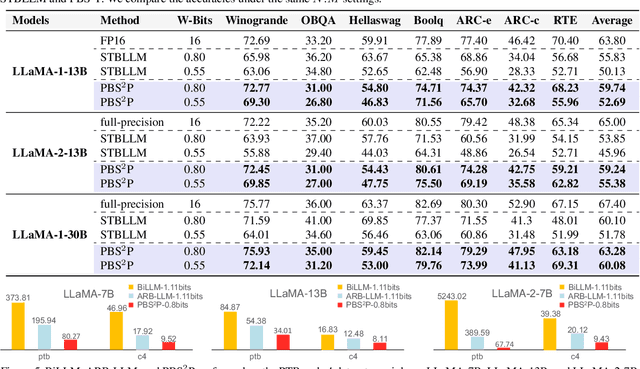
Large language models (LLMs) have achieved remarkable success in natural language processing tasks, but their high computational and memory demands pose challenges for deployment on resource-constrained devices. Binarization, as an efficient compression method that reduces model weights to just 1 bit, significantly lowers both computational and memory requirements. Despite this, the binarized LLM still contains redundancy, which can be further compressed. Semi-structured pruning provides a promising approach to achieve this, which offers a better trade-off between model performance and hardware efficiency. However, simply combining binarization with semi-structured pruning can lead to a significant performance drop. To address this issue, we propose a Progressive Binarization with Semi-Structured Pruning (PBS$^2$P) method for LLM compression. We first propose a Stepwise semi-structured Pruning with Binarization Optimization (SPBO). Our optimization strategy significantly reduces the total error caused by pruning and binarization, even below that of the no-pruning scenario. Furthermore, we design a Coarse-to-Fine Search (CFS) method to select pruning elements more effectively. Extensive experiments demonstrate that PBS$^2$P achieves superior accuracy across various LLM families and evaluation metrics, noticeably outperforming state-of-the-art (SOTA) binary PTQ methods. The code and models will be available at https://github.com/XIANGLONGYAN/PBS2P.