 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Binarization with Semi-Structured Pruning for LLMs
Paper and Code
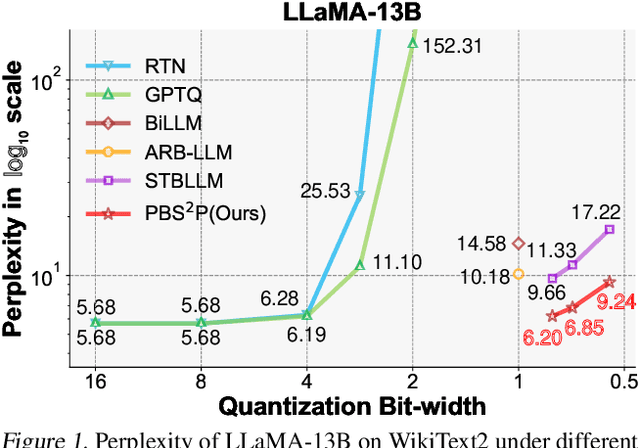
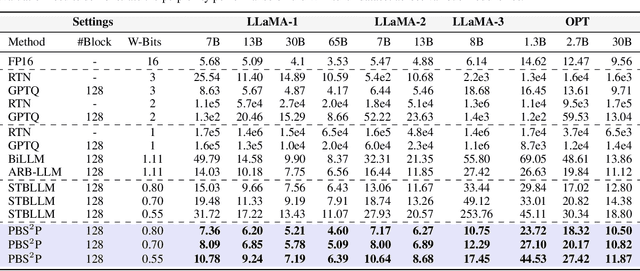
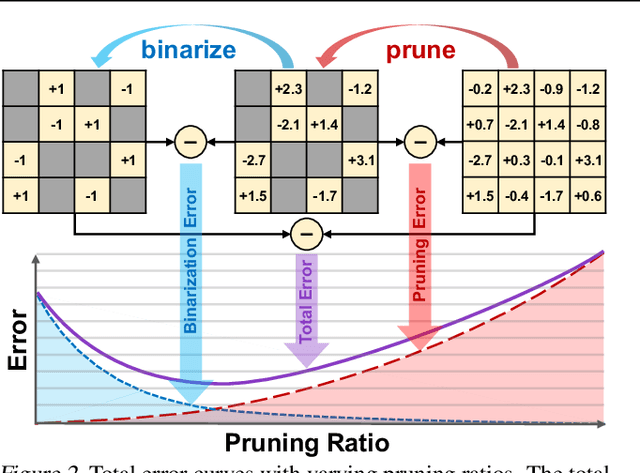
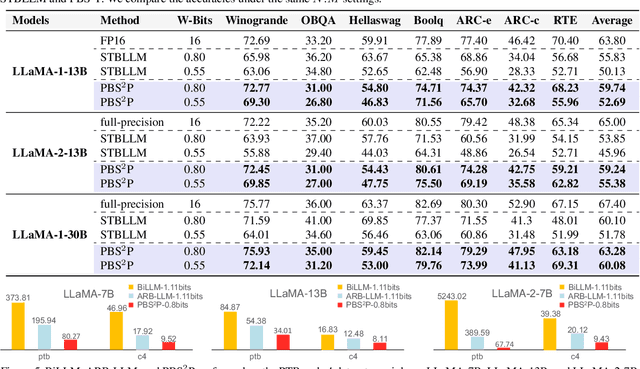
Large language models (LLMs) have achieved remarkable success in natural language processing tasks, but their high computational and memory demands pose challenges for deployment on resource-constrained devices. Binarization, as an efficient compression method that reduces model weights to just 1 bit, significantly lowers both computational and memory requirements. Despite this, the binarized LLM still contains redundancy, which can be further compressed. Semi-structured pruning provides a promising approach to achieve this, which offers a better trade-off between model performance and hardware efficiency. However, simply combining binarization with semi-structured pruning can lead to a significant performance drop. To address this issue, we propose a Progressive Binarization with Semi-Structured Pruning (PBS$^2$P) method for LLM compression. We first propose a Stepwise semi-structured Pruning with Binarization Optimization (SPBO). Our optimization strategy significantly reduces the total error caused by pruning and binarization, even below that of the no-pruning scenario. Furthermore, we design a Coarse-to-Fine Search (CFS) method to select pruning elements more effectively. Extensive experiments demonstrate that PBS$^2$P achieves superior accuracy across various LLM families and evaluation metrics, noticeably outperforming state-of-the-art (SOTA) binary PTQ methods. The code and models will be available at https://github.com/XIANGLONGYAN/PBS2P.