 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD$^2$Quant: Accurate Low-bit Post-Training Weight Quantization for LLMs
Jan 30, 2026Large language models (LLMs) deliver strong performance, but their high compute and memory costs make deployment difficult in resource-constrained scenarios. Weight-only post-training quantization (PTQ) is appealing, as it reduces memory usage and enables practical speedup without low-bit operators or specialized hardware. However, accuracy often degrades significantly in weight-only PTQ at sub-4-bit precision, and our analysis identifies two main causes: (1) down-projection matrices are a well-known quantization bottleneck, but maintaining their fidelity often requires extra bit-width; (2) weight quantization induces activation deviations, but effective correction strategies remain underexplored. To address these issues, we propose D$^2$Quant, a novel weight-only PTQ framework that improves quantization from both the weight and activation perspectives. On the weight side, we design a Dual-Scale Quantizer (DSQ) tailored to down-projection matrices, with an absorbable scaling factor that significantly improves accuracy without increasing the bit budget. On the activation side, we propose Deviation-Aware Correction (DAC), which incorporates a mean-shift correction within LayerNorm to mitigate quantization-induced activation distribution shifts. Extensive experiments across multiple LLM families and evaluation metrics show that D$^2$Quant delivers superior performance for weight-only PTQ at sub-4-bit precision. The code and models will be available at https://github.com/XIANGLONGYAN/D2Quant.
ReCalKV: Low-Rank KV Cache Compression via Head Reordering and Offline Calibration
May 30, 2025
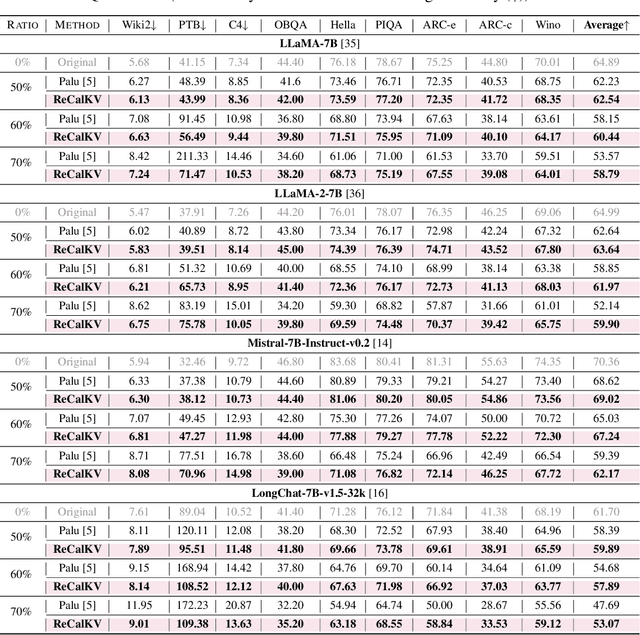
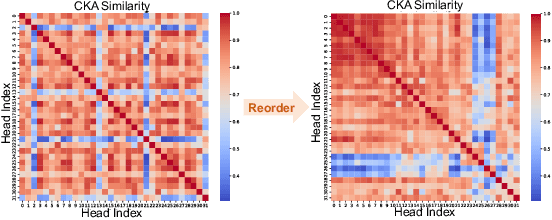

Large language models (LLMs) have achieved remarkable performance, yet their capability on long-context reasoning is often constrained by the excessive memory required to store the Key-Value (KV) cache. This makes KV cache compression an essential step toward enabling efficient long-context reasoning. Recent methods have explored reducing the hidden dimensions of the KV cache, but many introduce additional computation through projection layers or suffer from significant performance degradation under high compression ratios. To address these challenges, we propose ReCalKV, a post-training KV cache compression method that reduces the hidden dimensions of the KV cache. We develop distinct compression strategies for Keys and Values based on their different roles and varying importance in the attention mechanism. For Keys, we propose Head-wise Similarity-aware Reordering (HSR), which clusters similar heads and applies grouped SVD to the key projection matrix, reducing additional computation while preserving accuracy. For Values, we propose Offline Calibration and Matrix Fusion (OCMF) to preserve accuracy without extra computational overhead. Experiments show that ReCalKV outperforms existing low-rank compression methods, achieving high compression ratios with minimal performance loss. Code is available at: https://github.com/XIANGLONGYAN/ReCalKV.
Progressive Binarization with Semi-Structured Pruning for LLMs
Feb 03, 2025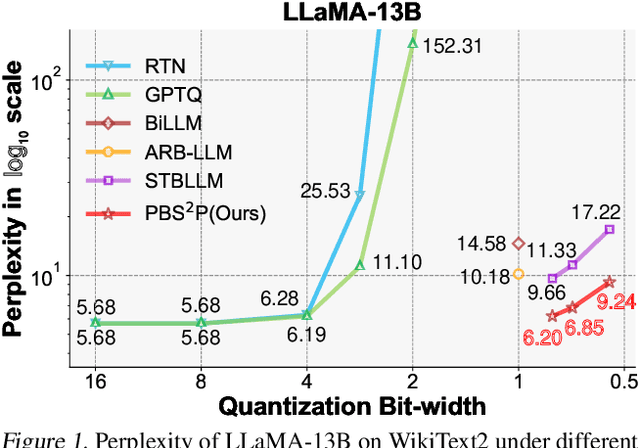
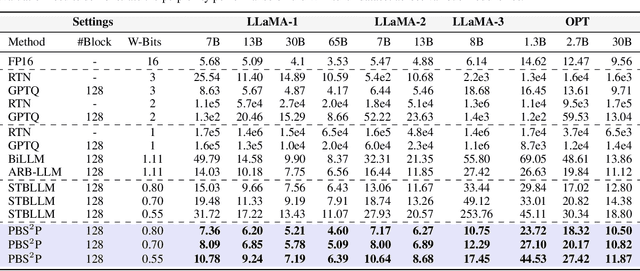
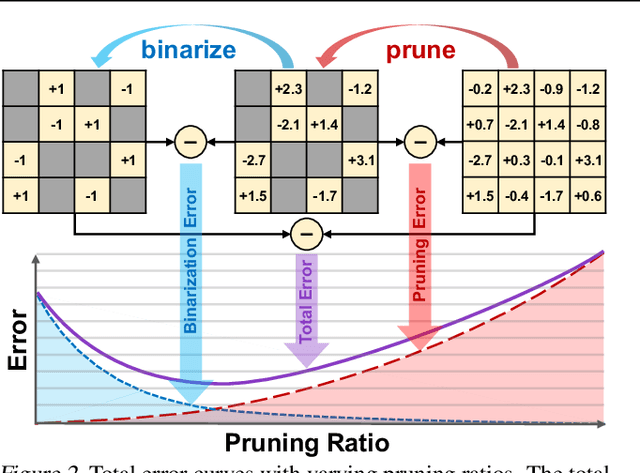
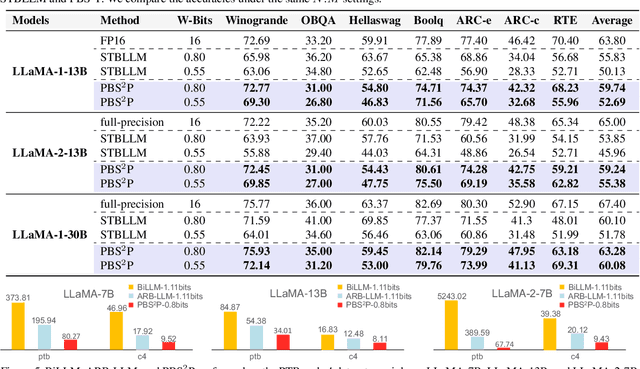
Large language models (LLMs) have achieved remarkable success in natural language processing tasks, but their high computational and memory demands pose challenges for deployment on resource-constrained devices. Binarization, as an efficient compression method that reduces model weights to just 1 bit, significantly lowers both computational and memory requirements. Despite this, the binarized LLM still contains redundancy, which can be further compressed. Semi-structured pruning provides a promising approach to achieve this, which offers a better trade-off between model performance and hardware efficiency. However, simply combining binarization with semi-structured pruning can lead to a significant performance drop. To address this issue, we propose a Progressive Binarization with Semi-Structured Pruning (PBS$^2$P) method for LLM compression. We first propose a Stepwise semi-structured Pruning with Binarization Optimization (SPBO). Our optimization strategy significantly reduces the total error caused by pruning and binarization, even below that of the no-pruning scenario. Furthermore, we design a Coarse-to-Fine Search (CFS) method to select pruning elements more effectively. Extensive experiments demonstrate that PBS$^2$P achieves superior accuracy across various LLM families and evaluation metrics, noticeably outperforming state-of-the-art (SOTA) binary PTQ methods. The code and models will be available at https://github.com/XIANGLONGYAN/PBS2P.
ARB-LLM: Alternating Refined Binarizations for Large Language Models
Oct 04, 2024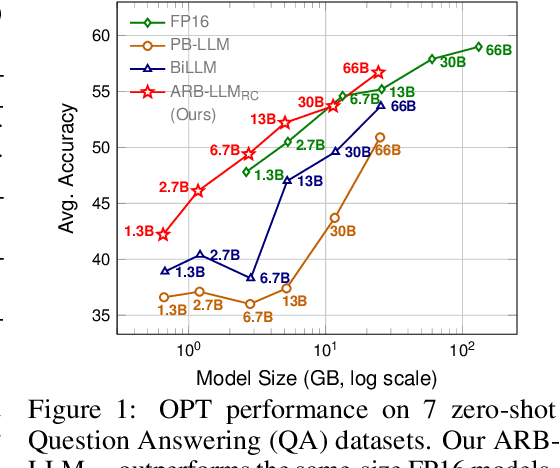
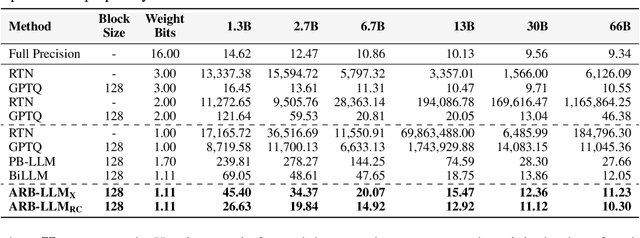
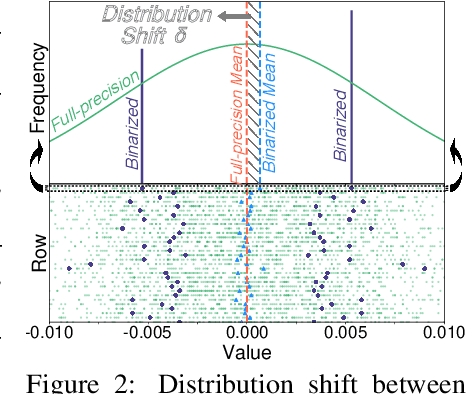
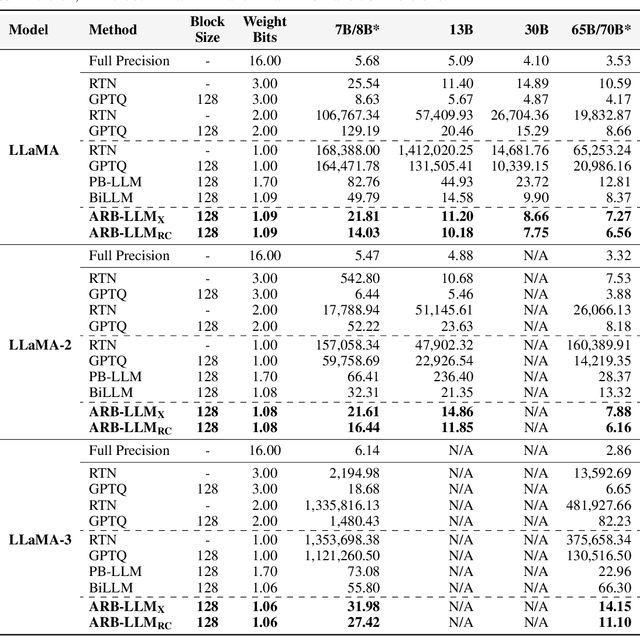
Large Language Models (LLMs) have greatly pushed forward advancements in natural language processing, yet their high memory and computational demands hinder practical deployment. Binarization, as an effective compression technique, can shrink model weights to just 1 bit, significantly reducing the high demands on computation and memory. However, current binarization methods struggle to narrow the distribution gap between binarized and full-precision weights, while also overlooking the column deviation in LLM weight distribution. To tackle these issues, we propose ARB-LLM, a novel 1-bit post-training quantization (PTQ) technique tailored for LLMs. To narrow the distribution shift between binarized and full-precision weights, we first design an alternating refined binarization (ARB) algorithm to progressively update the binarization parameters, which significantly reduces the quantization error. Moreover, considering the pivot role of calibration data and the column deviation in LLM weights, we further extend ARB to ARB-X and ARB-RC. In addition, we refine the weight partition strategy with column-group bitmap (CGB), which further enhance performance. Equipping ARB-X and ARB-RC with CGB, we obtain ARB-LLM$_\text{X}$ and ARB-LLM$_\text{RC}$ respectively, which significantly outperform state-of-the-art (SOTA) binarization methods for LLMs. As a binary PTQ method, our ARB-LLM$_\text{RC}$ is the first to surpass FP16 models of the same size. The code and models will be available at https://github.com/ZHITENGLI/ARB-LLM.