 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraversal Verification for Speculative Tree Decoding
May 18, 2025Speculative decoding is a promising approach for accelerating large language models. The primary idea is to use a lightweight draft model to speculate the output of the target model for multiple subsequent timesteps, and then verify them in parallel to determine whether the drafted tokens should be accepted or rejected. To enhance acceptance rates, existing frameworks typically construct token trees containing multiple candidates in each timestep. However, their reliance on token-level verification mechanisms introduces two critical limitations: First, the probability distribution of a sequence differs from that of individual tokens, leading to suboptimal acceptance length. Second, current verification schemes begin from the root node and proceed layer by layer in a top-down manner. Once a parent node is rejected, all its child nodes should be discarded, resulting in inefficient utilization of speculative candidates. This paper introduces Traversal Verification, a novel speculative decoding algorithm that fundamentally rethinks the verification paradigm through leaf-to-root traversal. Our approach considers the acceptance of the entire token sequence from the current node to the root, and preserves potentially valid subsequences that would be prematurely discarded by existing methods. We theoretically prove that the probability distribution obtained through Traversal Verification is identical to that of the target model, guaranteeing lossless inference while achieving substantial acceleration gains. Experimental results across different large language models and multiple tasks show that our method consistently improves acceptance length and throughput over existing methods
CORAL: Learning Consistent Representations across Multi-step Training with Lighter Speculative Drafter
Feb 24, 2025Speculative decoding is a powerful technique that accelerates Large Language Model (LLM) inference by leveraging a lightweight speculative draft model. However, existing designs suffers in performance due to misalignment between training and inference. Recent methods have tried to solve this issue by adopting a multi-step training strategy, but the complex inputs of different training steps make it harder for the draft model to converge. To address this, we propose CORAL, a novel framework that improves both accuracy and efficiency in speculative drafting. CORAL introduces Cross-Step Representation Alignment, a method that enhances consistency across multiple training steps, significantly improving speculative drafting performance. Additionally, we identify the LM head as a major bottleneck in the inference speed of the draft model. We introduce a weight-grouping mechanism that selectively activates a subset of LM head parameters during inference, substantially reducing the latency of the draft model. We evaluate CORAL on three LLM families and three benchmark datasets, achieving speedup ratios of 2.50x-4.07x, outperforming state-of-the-art methods such as EAGLE-2 and HASS. Our results demonstrate that CORAL effectively mitigates training-inference misalignment and delivers significant speedup for modern LLMs with large vocabularies.
ARB-LLM: Alternating Refined Binarizations for Large Language Models
Oct 04, 2024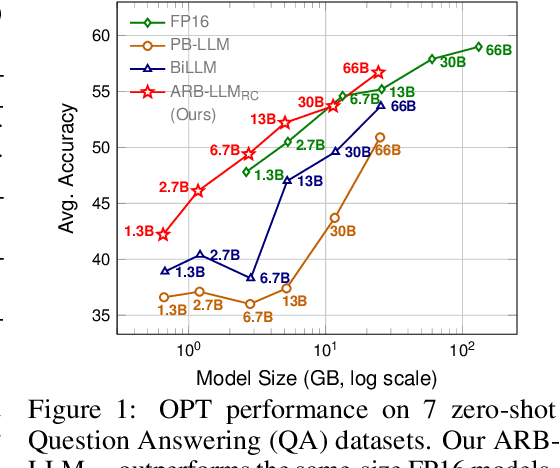
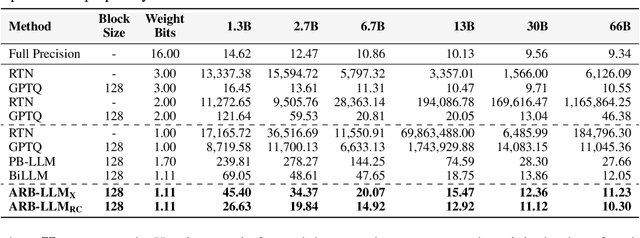
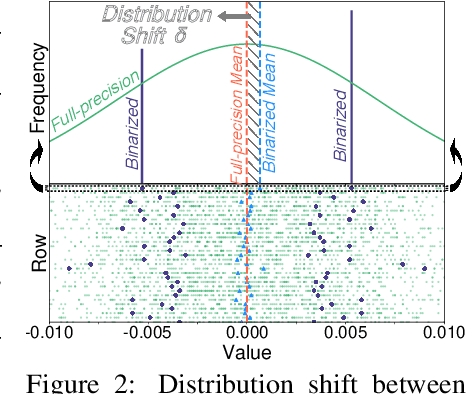
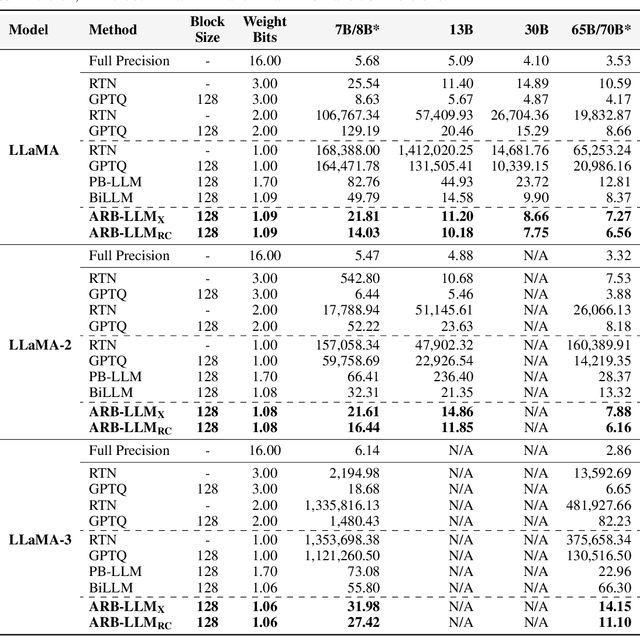
Large Language Models (LLMs) have greatly pushed forward advancements in natural language processing, yet their high memory and computational demands hinder practical deployment. Binarization, as an effective compression technique, can shrink model weights to just 1 bit, significantly reducing the high demands on computation and memory. However, current binarization methods struggle to narrow the distribution gap between binarized and full-precision weights, while also overlooking the column deviation in LLM weight distribution. To tackle these issues, we propose ARB-LLM, a novel 1-bit post-training quantization (PTQ) technique tailored for LLMs. To narrow the distribution shift between binarized and full-precision weights, we first design an alternating refined binarization (ARB) algorithm to progressively update the binarization parameters, which significantly reduces the quantization error. Moreover, considering the pivot role of calibration data and the column deviation in LLM weights, we further extend ARB to ARB-X and ARB-RC. In addition, we refine the weight partition strategy with column-group bitmap (CGB), which further enhance performance. Equipping ARB-X and ARB-RC with CGB, we obtain ARB-LLM$_\text{X}$ and ARB-LLM$_\text{RC}$ respectively, which significantly outperform state-of-the-art (SOTA) binarization methods for LLMs. As a binary PTQ method, our ARB-LLM$_\text{RC}$ is the first to surpass FP16 models of the same size. The code and models will be available at https://github.com/ZHITENGLI/ARB-LLM.
A New Transformation Approach for Uplift Modeling with Binary Outcome
Oct 09, 2023Uplift modeling has been used effectively in fields such as marketing and customer retention, to target those customers who are more likely to respond due to the campaign or treatment. Essentially, it is a machine learning technique that predicts the gain from performing some action with respect to not taking it. A popular class of uplift models is the transformation approach that redefines the target variable with the original treatment indicator. These transformation approaches only need to train and predict the difference in outcomes directly. The main drawback of these approaches is that in general it does not use the information in the treatment indicator beyond the construction of the transformed outcome and usually is not efficient. In this paper, we design a novel transformed outcome for the case of the binary target variable and unlock the full value of the samples with zero outcome. From a practical perspective, our new approach is flexible and easy to use. Experimental results on synthetic and real-world datasets obviously show that our new approach outperforms the traditional one. At present, our new approach has already been applied to precision marketing in a China nation-wide financial holdings group.
An Effective Two-stage Training Paradigm Detector for Small Dataset
Sep 11, 2023



Learning from the limited amount of labeled data to the pre-train model has always been viewed as a challenging task. In this report, an effective and robust solution, the two-stage training paradigm YOLOv8 detector (TP-YOLOv8), is designed for the object detection track in VIPriors Challenge 2023. First, the backbone of YOLOv8 is pre-trained as the encoder using the masked image modeling technique. Then the detector is fine-tuned with elaborate augmentations. During the test stage, test-time augmentation (TTA) is used to enhance each model, and weighted box fusion (WBF) is implemented to further boost the performance. With the well-designed structure, our approach has achieved 30.4% average precision from 0.50 to 0.95 on the DelftBikes test set, ranking 4th on the leaderboard.
Feature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 21, 2023



Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Learn More for Food Recognition via Progressive Self-Distillation
Mar 09, 2023



Food recognition has a wide range of applications, such as health-aware recommendation and self-service restaurants. Most previous methods of food recognition firstly locate informative regions in some weakly-supervised manners and then aggregate their features. However, location errors of informative regions limit the effectiveness of these methods to some extent. Instead of locating multiple regions, we propose a Progressive Self-Distillation (PSD) method, which progressively enhances the ability of network to mine more details for food recognition. The training of PSD simultaneously contains multiple self-distillations, in which a teacher network and a student network share the same embedding network. Since the student network receives a modified image from its teacher network by masking some informative regions, the teacher network outputs stronger semantic representations than the student network. Guided by such teacher network with stronger semantics, the student network is encouraged to mine more useful regions from the modified image by enhancing its own ability. The ability of the teacher network is also enhanced with the shared embedding network. By using progressive training, the teacher network incrementally improves its ability to mine more discriminative regions. In inference phase, only the teacher network is used without the help of the student network. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method and state-of-the-art performance.
Causal Inference Based Single-branch Ensemble Trees For Uplift Modeling
Feb 03, 2023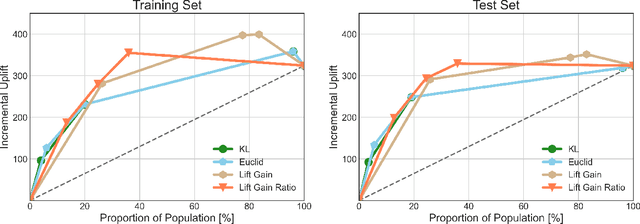


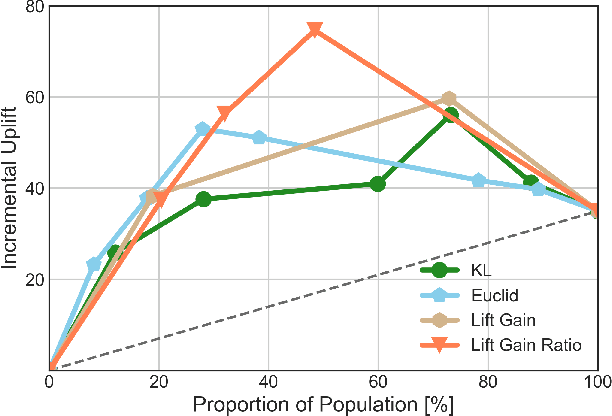
In this manuscript (ms), we propose causal inference based single-branch ensemble trees for uplift modeling, namely CIET. Different from standard classification methods for predictive probability modeling, CIET aims to achieve the change in the predictive probability of outcome caused by an action or a treatment. According to our CIET, two partition criteria are specifically designed to maximize the difference in outcome distribution between the treatment and control groups. Next, a novel single-branch tree is built by taking a top-down node partition approach, and the remaining samples are censored since they are not covered by the upper node partition logic. Repeating the tree-building process on the censored data, single-branch ensemble trees with a set of inference rules are thus formed. Moreover, CIET is experimentally demonstrated to outperform previous approaches for uplift modeling in terms of both area under uplift curve (AUUC) and Qini coefficient significantly. At present, CIET has already been applied to online personal loans in a national financial holdings group in China. CIET will also be of use to analysts applying machine learning techniques to causal inference in broader business domains such as web advertising, medicine and economics.
SAP-DETR: Bridging the Gap Between Salient Points and Queries-Based Transformer Detector for Fast Model Convergency
Nov 03, 2022Recently, the dominant DETR-based approaches apply central-concept spatial prior to accelerate Transformer detector convergency. These methods gradually refine the reference points to the center of target objects and imbue object queries with the updated central reference information for spatially conditional attention. However, centralizing reference points may severely deteriorate queries' saliency and confuse detectors due to the indiscriminative spatial prior. To bridge the gap between the reference points of salient queries and Transformer detectors, we propose SAlient Point-based DETR (SAP-DETR) by treating object detection as a transformation from salient points to instance objects. In SAP-DETR, we explicitly initialize a query-specific reference point for each object query, gradually aggregate them into an instance object, and then predict the distance from each side of the bounding box to these points. By rapidly attending to query-specific reference region and other conditional extreme regions from the image features, SAP-DETR can effectively bridge the gap between the salient point and the query-based Transformer detector with a significant convergency speed. Our extensive experiments have demonstrated that SAP-DETR achieves 1.4 times convergency speed with competitive performance. Under the standard training scheme, SAP-DETR stably promotes the SOTA approaches by 1.0 AP. Based on ResNet-DC-101, SAP-DETR achieves 46.9 AP.
Decoupled Pyramid Correlation Network for Liver Tumor Segmentation from CT images
May 26, 2022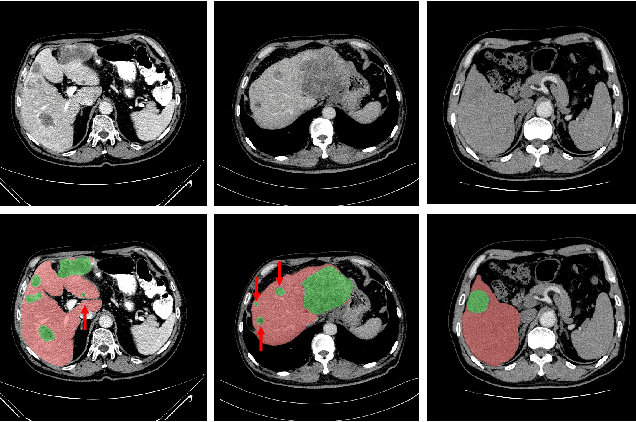
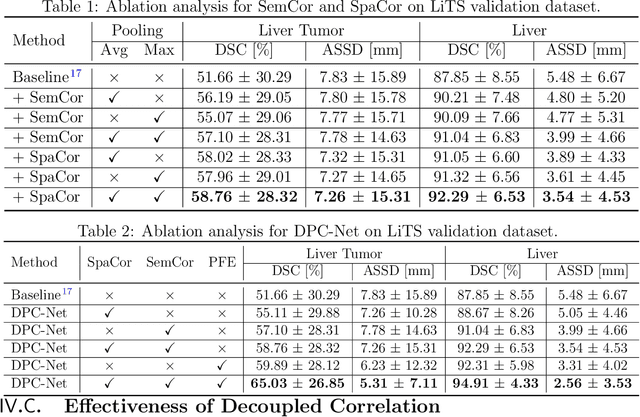
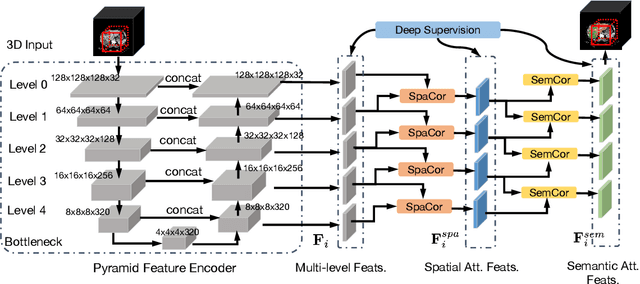
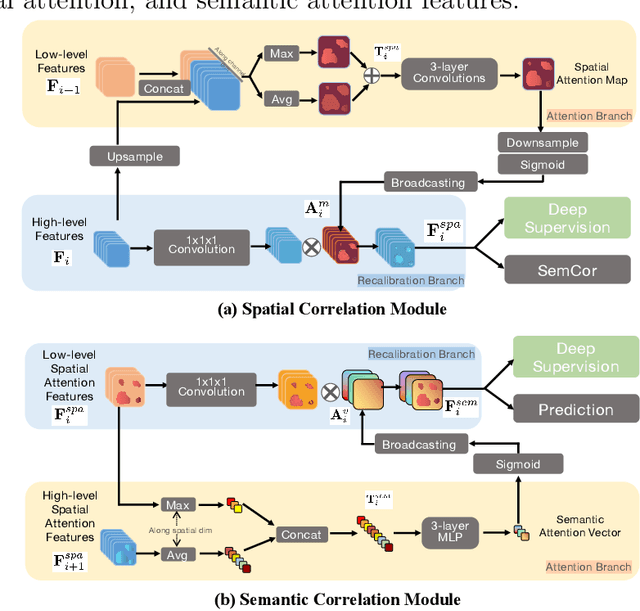
Purpose: Automated liver tumor segmentation from Computed Tomography (CT) images is a necessary prerequisite in the interventions of hepatic abnormalities and surgery planning. However, accurate liver tumor segmentation remains challenging due to the large variability of tumor sizes and inhomogeneous texture. Recent advances based on Fully Convolutional Network (FCN) for medical image segmentation drew on the success of learning discriminative pyramid features. In this paper, we propose a Decoupled Pyramid Correlation Network (DPC-Net) that exploits attention mechanisms to fully leverage both low- and high-level features embedded in FCN to segment liver tumor. Methods: We first design a powerful Pyramid Feature Encoder (PFE) to extract multi-level features from input images. Then we decouple the characteristics of features concerning spatial dimension (i.e., height, width, depth) and semantic dimension (i.e., channel). On top of that, we present two types of attention modules, Spatial Correlation (SpaCor) and Semantic Correlation (SemCor) modules, to recursively measure the correlation of multi-level features. The former selectively emphasizes global semantic information in low-level features with the guidance of high-level ones. The latter adaptively enhance spatial details in high-level features with the guidance of low-level ones. Results: We evaluate the DPC-Net on MICCAI 2017 LiTS Liver Tumor Segmentation (LiTS) challenge dataset. Dice Similarity Coefficient (DSC) and Average Symmetric Surface Distance (ASSD) are employed for evaluation. The proposed method obtains a DSC of 76.4% and an ASSD of 0.838 mm for liver tumor segmentation, outperforming the state-of-the-art methods. It also achieves a competitive results with a DSC of 96.0% and an ASSD of 1.636 mm for liver segmentation.